Reinforcement Learning for Infinite-Dimensional Systems
作者: Wei Zhang, Jr-Shin Li
分类: eess.SY, math.OC
发布日期: 2024-09-24 (更新: 2025-09-15)
💡 一句话要点
提出基于矩核变换的强化学习框架,解决大规模智能体系统控制问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 无限维系统 矩核变换 分层算法 大规模智能体 再生核希尔伯特空间 参数化控制系统 最优控制
📋 核心要点
- 大规模智能体系统强化学习面临计算成本高和性能下降的挑战。
- 论文提出基于矩核变换的强化学习框架,将无限维系统映射到有限维空间。
- 通过分层算法和提前停止策略,加速收敛,并在工程和量子系统上验证有效性。
📝 摘要(中文)
近年来,针对大规模系统的强化学习(RL)兴趣显著增长,这些系统包含与异构环境交互的大量智能体。然而,这些系统的大规模特性通常导致计算成本高昂或现有RL技术的性能下降。为了应对这些挑战,我们提出了一种新颖的RL架构,并推导出有效的算法来学习任意大型智能体系统的最优策略。在我们的公式中,我们将此类系统建模为在无限维函数空间上定义的参数化控制系统。然后,我们开发了一种矩核变换,将参数化系统和价值函数映射到再生核希尔伯特空间。这种变换为RL问题生成一系列有限维矩表示,组织成一个过滤结构。利用这种RL过滤,我们开发了一种分层算法来学习无限维参数化系统的最优策略。为了提高算法的效率,我们利用每个层次的提前停止,通过构建收敛谱序列来证明算法的快速收敛性。通过工程和量子系统中的实际例子验证了所提出算法的性能和效率。
🔬 方法详解
问题定义:论文旨在解决大规模智能体系统强化学习中,由于状态空间维度过高导致的计算复杂度问题。现有方法难以处理无限维状态空间,或者在大规模系统中的性能显著下降。
核心思路:论文的核心思路是将无限维的参数化控制系统通过矩核变换映射到再生核希尔伯特空间,从而将问题转化为一系列有限维的矩表示。通过这种降维,可以降低计算复杂度,并利用分层算法进行优化。
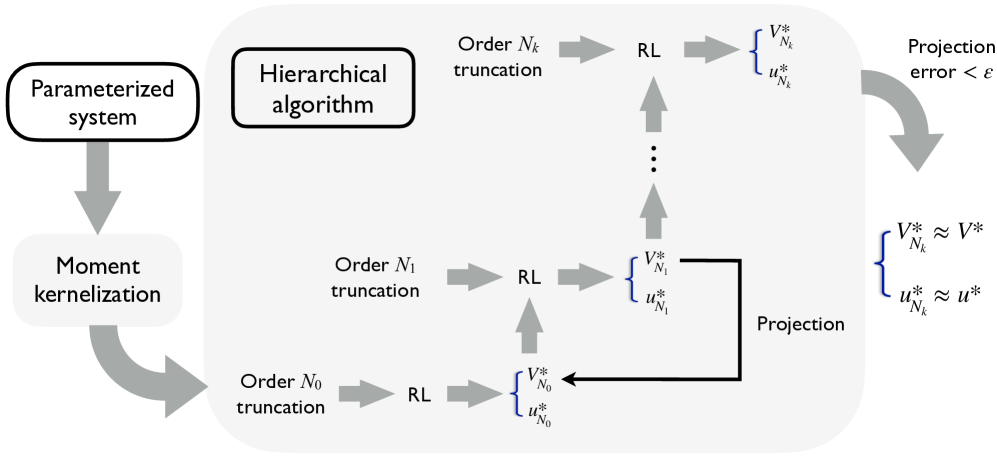
技术框架:整体框架包含以下几个主要阶段:1) 将大规模智能体系统建模为无限维函数空间上的参数化控制系统;2) 利用矩核变换将参数化系统和价值函数映射到再生核希尔伯特空间;3) 构建RL过滤,生成一系列有限维矩表示;4) 利用分层算法学习最优策略,并在每个层次采用提前停止策略加速收敛。
关键创新:最重要的技术创新点在于矩核变换的应用,它能够有效地将无限维系统转化为有限维表示,从而使得强化学习算法能够处理大规模系统。此外,分层算法和提前停止策略进一步提高了算法的效率。
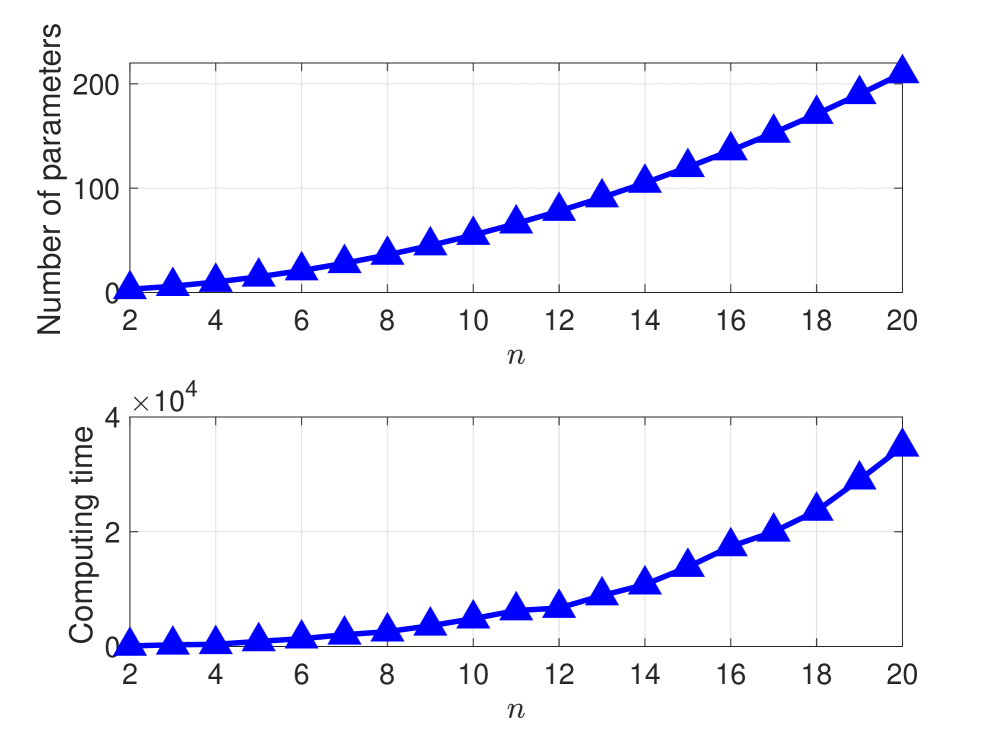
关键设计:论文的关键设计包括:矩核函数的选择,它决定了映射的性质和表示的有效性;分层算法的层次划分,影响了算法的收敛速度和性能;提前停止策略的阈值设置,需要在收敛速度和精度之间进行权衡。具体的参数设置和损失函数等技术细节在论文中可能没有详细展开,需要进一步研究。
🖼️ 关键图片
📊 实验亮点
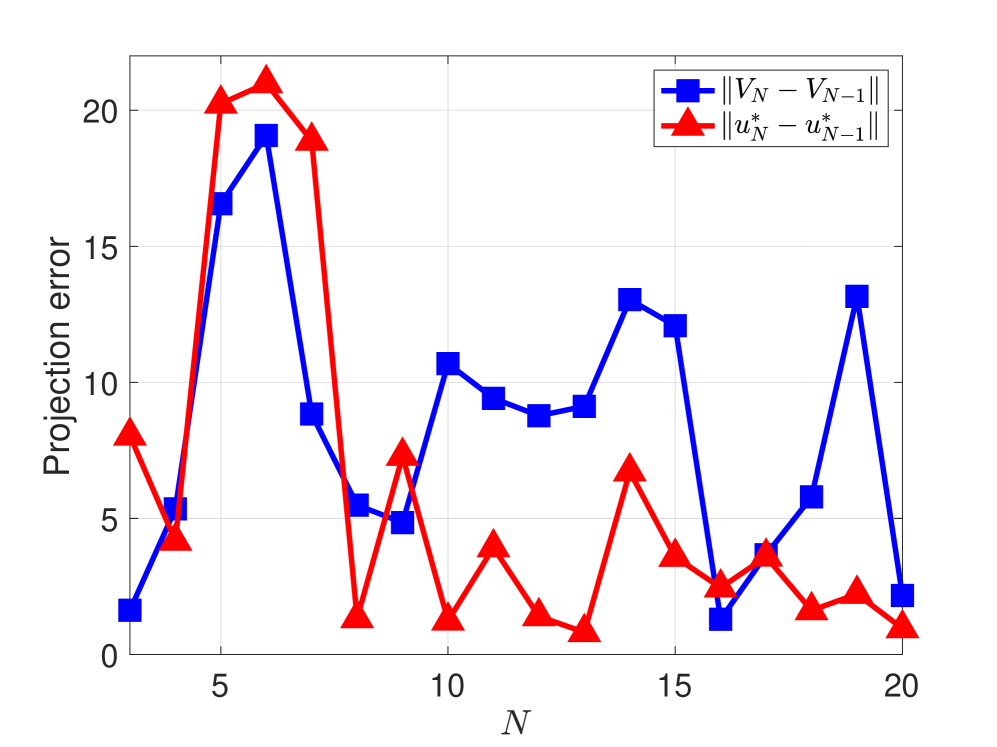
论文通过工程和量子系统中的实际例子验证了所提出算法的性能和效率。虽然具体的性能数据和对比基线没有在摘要中给出,但强调了算法的快速收敛性,并通过构建收敛谱序列进行了理论证明。这表明该算法在处理大规模系统时具有显著的优势。
🎯 应用场景
该研究成果可应用于大规模机器人集群控制、智能交通系统优化、量子系统控制等领域。通过降低计算复杂度和提高学习效率,能够更好地解决实际工程问题,并推动相关领域的发展。未来,该方法有望扩展到更复杂的动态系统和更广泛的应用场景。
📄 摘要(原文)
Interest in reinforcement learning (RL) for large-scale systems, comprising extensive populations of intelligent agents interacting with heterogeneous environments, has surged significantly across diverse scientific domains in recent years. However, the large-scale nature of these systems often leads to high computational costs or reduced performance for most state-of-the-art RL techniques. To address these challenges, we propose a novel RL architecture and derive effective algorithms to learn optimal policies for arbitrarily large systems of agents. In our formulation, we model such systems as parameterized control systems defined on an infinite-dimensional function space. We then develop a moment kernel transform that maps the parameterized system and the value function into a reproducing kernel Hilbert space. This transformation generates a sequence of finite-dimensional moment representations for the RL problem, organized into a filtrated structure. Leveraging this RL filtration, we develop a hierarchical algorithm for learning optimal policies for the infinite-dimensional parameterized system. To enhance the algorithm's efficiency, we exploit early stopping at each hierarchy, demonstrating the fast convergence property of the algorithm through the construction of a convergent spectral sequence. The performance and efficiency of the proposed algorithm are validated using practical examples in engineering and quantum systems.