Hierarchical Event-Triggered Systems: Safe Learning of Quasi-Optimal Deadline Policies
作者: Pio Ong, Manuel Mazo, Aaron D. Ames
分类: eess.SY, math.OC
发布日期: 2024-09-15
备注: 7 pages, 4 figures, IEEE Conference on Decision and Control
💡 一句话要点
提出分层事件触发系统,通过强化学习优化截止时间策略,安全降低资源消耗
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 事件触发控制 强化学习 分层控制 截止时间策略 资源优化
📋 核心要点
- 传统事件触发控制采用贪婪策略优化平均事件间隔,缺乏对长期性能的优化。
- 提出分层架构,底层采用事件触发控制保证安全,高层采用强化学习优化截止时间策略,提升长期折扣事件间隔时间。
- 在轨道航天器控制上的实验表明,该方案在保证安全性的前提下,有效降低了驱动频率。
📝 摘要(中文)
本文提出了一种分层架构,旨在提高事件触发控制(ETC)在降低资源消耗方面的效率。该架构将事件触发系统视为脉冲控制系统,目标是最小化脉冲数量。传统ETC采用贪婪策略优化平均事件间隔时间,本文引入截止时间策略,以优化长期折扣事件间隔时间。底层采用事件触发控制,保证控制目标的实现;高层采用强化学习设计的截止时间策略,以改善折扣事件间隔时间。该方案应用于轨道航天器的控制,实验结果表明,相对于标准(单层)ETC,该方案在保证安全性的前提下,显著降低了驱动频率。
🔬 方法详解
问题定义:论文旨在解决事件触发控制系统中资源消耗过高的问题。传统的事件触发控制方法通常采用贪婪策略,即每次事件触发都尽可能延长下一次触发的时间间隔,但这种方法只关注局部最优,忽略了长期性能的优化,可能导致整体资源消耗较高。
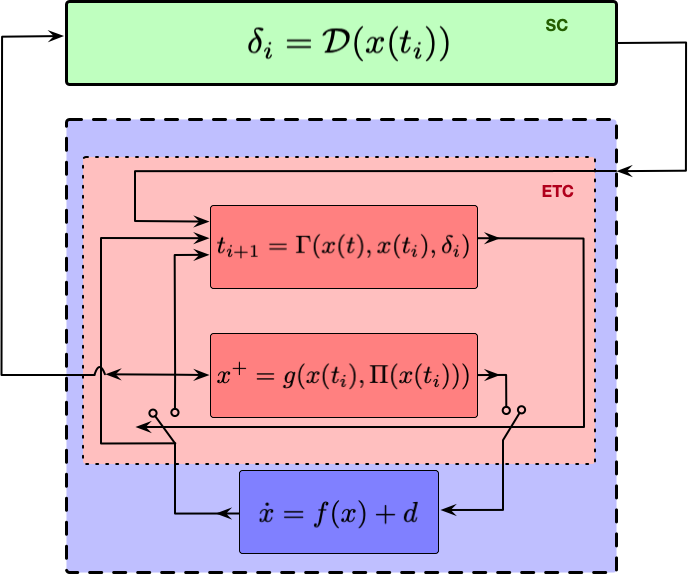
核心思路:论文的核心思路是将事件触发控制系统设计为分层结构。底层采用传统的事件触发控制,保证系统的安全性和基本性能;高层引入截止时间策略,通过强化学习优化长期折扣事件间隔时间,从而在保证安全性的前提下,降低整体资源消耗。
技术框架:整体架构包含两个主要层级: 1. 底层事件触发控制:负责保证控制目标的实现,例如系统的稳定性、跟踪性能等。当系统状态满足预定义的触发条件时,触发控制动作。 2. 高层截止时间策略:基于强化学习,学习一个最优的截止时间策略。该策略决定何时应该强制触发事件,即使底层事件触发条件尚未满足。通过调整截止时间,可以优化长期折扣事件间隔时间。
关键创新:最重要的创新点在于引入了截止时间策略,并使用强化学习进行优化。与传统的事件触发控制方法相比,该方法能够更好地平衡局部性能和长期性能,从而在保证安全性的前提下,降低整体资源消耗。
关键设计: 1. 强化学习算法:论文采用的强化学习算法未知,需要查阅论文细节。 2. 奖励函数设计:奖励函数的设计至关重要,需要考虑事件间隔时间、控制误差、资源消耗等因素,以引导强化学习算法学习到最优的截止时间策略。 3. 截止时间策略表示:截止时间策略可以使用神经网络等函数逼近器来表示,需要根据具体问题选择合适的网络结构。
🖼️ 关键图片
📊 实验亮点
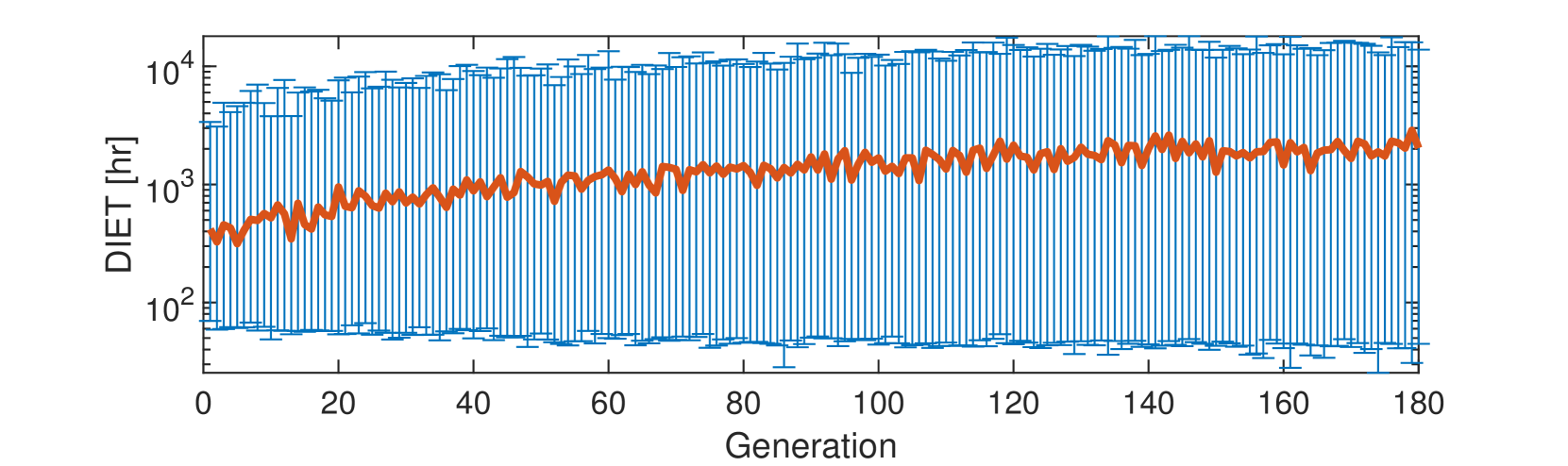
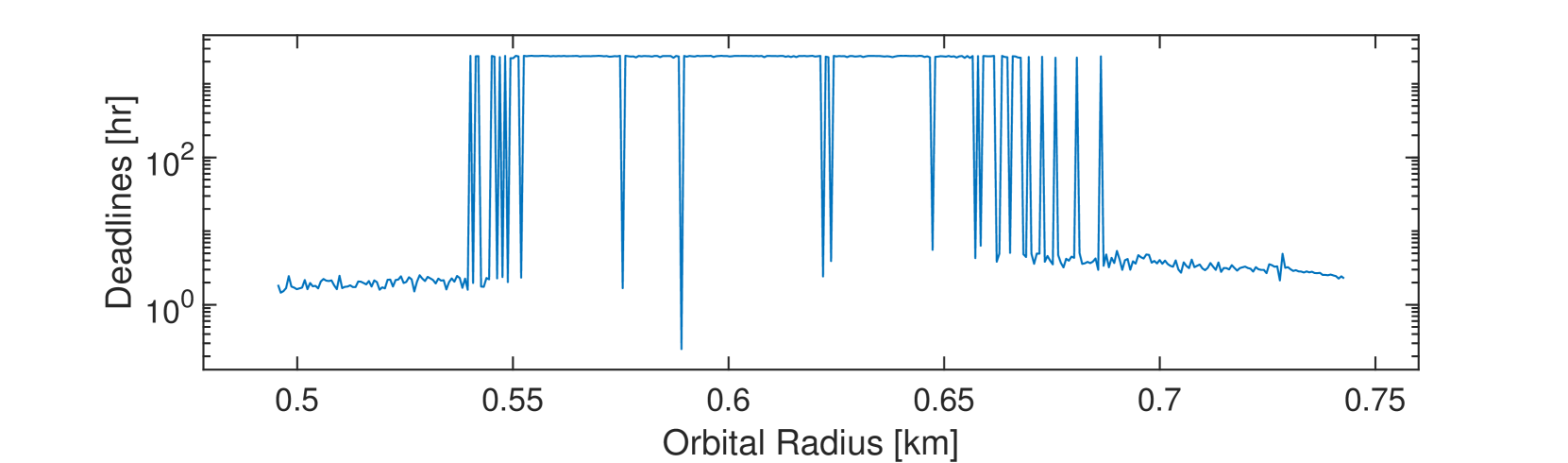
论文将该方案应用于轨道航天器的控制,实验结果表明,相对于标准(单层)ETC,该方案在保证安全性的前提下,显著降低了驱动频率。具体的性能提升数据未知,需要在论文中查找。
🎯 应用场景
该研究成果可应用于各种资源受限的控制系统,例如无人机集群控制、机器人网络、智能电网等。通过优化事件触发策略,可以在保证系统性能的前提下,降低通信带宽、计算资源和能量消耗,提高系统的整体效率和可靠性。该方法对于延长设备寿命、降低运营成本具有重要意义。
📄 摘要(原文)
We present a hierarchical architecture to improve the efficiency of event-triggered control (ETC) in reducing resource consumption. This paper considers event-triggered systems generally as an impulsive control system in which the objective is to minimize the number of impulses. Our architecture recognizes that traditional ETC is a greedy strategy towards optimizing average inter-event times and introduces the idea of a deadline policy for the optimization of long-term discounted inter-event times. A lower layer is designed employing event-triggered control to guarantee the satisfaction of control objectives, while a higher layer implements a deadline policy designed with reinforcement learning to improve the discounted inter-event time. We apply this scheme to the control of an orbiting spacecraft, showing superior performance in terms of actuation frequency reduction with respect to a standard (one-layer) ETC while maintaining safety guarantees.