Reinforcement learning-based adaptive speed controllers in mixed autonomy condition
作者: Han Wang, Hossein Nick Zinat Matin, Maria Laura Delle Monache
分类: eess.SY
发布日期: 2024-08-17
DOI: 10.23919/ECC64448.2024.10590883
💡 一句话要点
提出基于强化学习的自适应速度控制器,优化混合交通流
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 自动驾驶 交通流优化 混合交通流 Actor-Critic 自适应控制
📋 核心要点
- 现有交通控制方法难以有效应对混合交通流中人类驾驶行为的不确定性,导致交通拥堵。
- 利用强化学习算法,为自动驾驶车辆设计自适应速度控制器,通过与环境交互学习最优策略。
- 数值模拟验证了所提出控制器的有效性,表明自动驾驶车辆能够改善交通流量并减少拥堵。
📝 摘要(中文)
本文提出了一种自适应速度控制器,专为混合自主驾驶场景设计,其中自动驾驶车辆(AVs)与人类驾驶车辆相互作用。我们使用强耦合的偏微分方程(PDE)和常微分方程(ODE)系统来模拟交通动态,其中PDE捕捉人类驾驶交通的总体流量,ODE表征AV的轨迹。AV的速度策略是通过在Actor-Critic(AC)框架内构建的强化学习(RL)算法导出的。该算法与PDE-ODE模型交互,以优化AV控制策略。数值模拟结果表明了该控制器对交通模式的影响,展示了AV在改善交通流量和减少拥堵方面的潜力。
🔬 方法详解
问题定义:论文旨在解决混合自主交通环境中,如何利用自动驾驶车辆(AVs)优化整体交通流量,缓解拥堵的问题。现有方法难以有效建模人类驾驶员行为的不确定性,并且缺乏针对混合交通流的自适应控制策略。
核心思路:论文的核心思路是利用强化学习(RL)算法,训练AVs学习最优的速度控制策略,使其能够根据周围人类驾驶车辆的交通状况,自适应地调整自身速度,从而优化整体交通流。通过将AVs视为交通流中的执行器,可以有效地影响和改善交通状况。
技术框架:整体框架包括:1) 使用偏微分方程(PDE)模拟人类驾驶车辆的交通流;2) 使用常微分方程(ODE)描述AVs的轨迹;3) 构建基于Actor-Critic(AC)的强化学习算法,与PDE-ODE模型交互,学习AVs的最优速度控制策略。Actor负责输出AV的速度控制动作,Critic负责评估该动作的价值,并指导Actor进行策略更新。
关键创新:关键创新在于将强化学习与交通流的PDE-ODE模型相结合,实现AVs的自适应速度控制。这种方法能够有效地建模混合交通流的复杂动态,并学习到针对特定交通状况的最优控制策略。此外,使用Actor-Critic框架可以提高学习效率和稳定性。
关键设计:Actor网络和Critic网络的具体结构未知。强化学习算法的目标是最大化累积奖励,奖励函数的设计需要考虑交通流量、车辆密度和行驶安全性等因素。具体的参数设置和训练过程未知。
🖼️ 关键图片
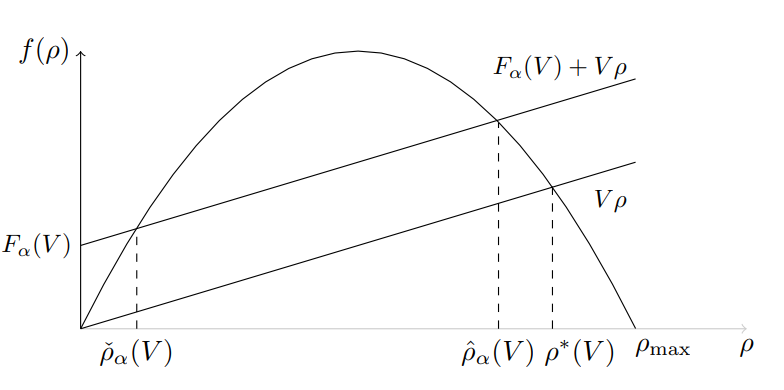


📊 实验亮点
论文通过数值模拟验证了所提出控制器的有效性,结果表明,自动驾驶车辆能够显著改善交通流量,减少交通拥堵。具体的性能数据和对比基线未知,但结果表明了自动驾驶车辆在优化混合交通流方面的潜力。
🎯 应用场景
该研究成果可应用于智能交通系统,通过部署配备自适应速度控制器的自动驾驶车辆,优化城市交通流量,减少交通拥堵,提高道路通行效率,并降低能源消耗和排放。未来,该技术可进一步扩展到车队管理、自动驾驶出租车等领域,实现更高效、更环保的交通运输。
📄 摘要(原文)
The integration of Automated Vehicles (AVs) into traffic flow holds the potential to significantly improve traffic congestion by enabling AVs to function as actuators within the flow. This paper introduces an adaptive speed controller tailored for scenarios of mixed autonomy, where AVs interact with human-driven vehicles. We model the traffic dynamics using a system of strongly coupled Partial and Ordinary Differential Equations (PDE-ODE), with the PDE capturing the general flow of human-driven traffic and the ODE characterizing the trajectory of the AVs. A speed policy for AVs is derived using a Reinforcement Learning (RL) algorithm structured within an Actor-Critic (AC) framework. This algorithm interacts with the PDE-ODE model to optimize the AV control policy. Numerical simulations are presented to demonstrate the controller's impact on traffic patterns, showing the potential of AVs to improve traffic flow and reduce congestion.