Phase Re-service in Reinforcement Learning Traffic Signal Control
作者: Zhiyao Zhang, George Gunter, Marcos Quinones-Grueiro, Yuhang Zhang, William Barbour, Gautam Biswas, Daniel Work
分类: eess.SY
发布日期: 2024-07-20 (更新: 2024-08-02)
备注: Accepted to IEEE ITSC 2024
💡 一句话要点
提出基于强化学习的相位重服务交通信号控制方法,显著降低车辆延误和停车次数。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 交通信号控制 强化学习 相位重服务 冲击波理论 半马尔可夫决策过程
📋 核心要点
- 现有交通信号控制方法难以应对交通流量的动态变化,导致车辆延误和停车次数增加。
- 该方法结合强化学习与相位重服务,利用冲击波理论动态调整信号相位,优化交通流。
- 实验表明,该方法显著降低了车辆延误和停车次数,提升了交通效率和鲁棒性。
📝 摘要(中文)
本文提出了一种结合相位重服务与强化学习(RL)的交通信号控制新方法。RL智能体直接决定预定义序列中下一个相位的持续时间。在执行RL智能体的决策之前,我们使用冲击波理论来估计指定运动的排队扩展,并决定是否需要相位重服务。如果需要,则在下一个常规相位之前插入一个临时相位重服务。我们将RL问题表述为半马尔可夫决策过程(SMDP),并使用近端策略优化(PPO)算法求解。实验结果表明,引入相位重服务后,车辆平均延误最多减少29.95%,延误标准差最多减少59.21%。停车次数平均减少26.05%,标准差减少45.77%。
🔬 方法详解
问题定义:现有交通信号控制方法在应对交通流量的动态变化时存在不足,无法根据实时交通状况灵活调整信号相位,导致车辆延误增加、停车次数增多,以及交通拥堵加剧。传统的固定配时方案和简单的自适应控制策略难以满足日益增长的交通需求,尤其是在高峰时段或突发事件发生时。
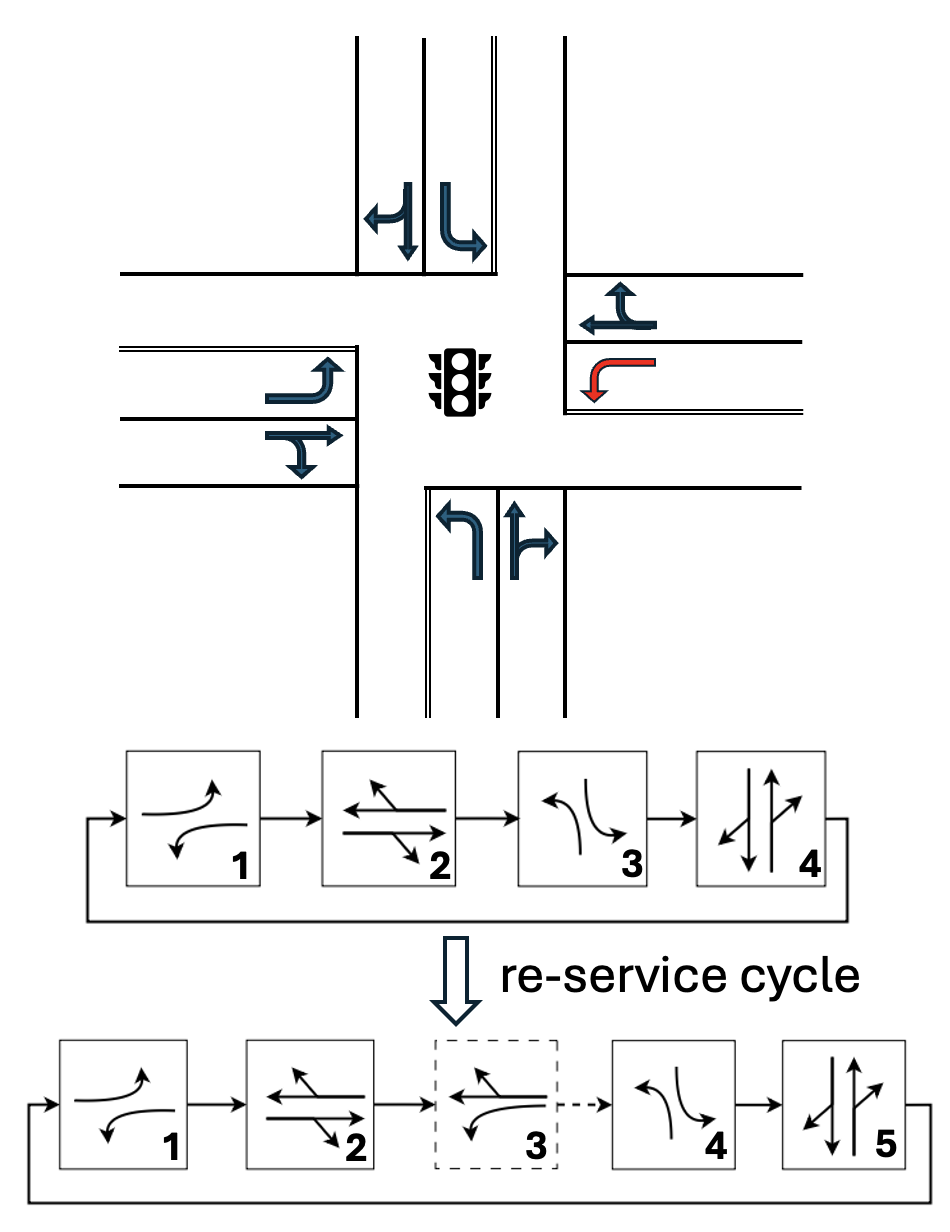
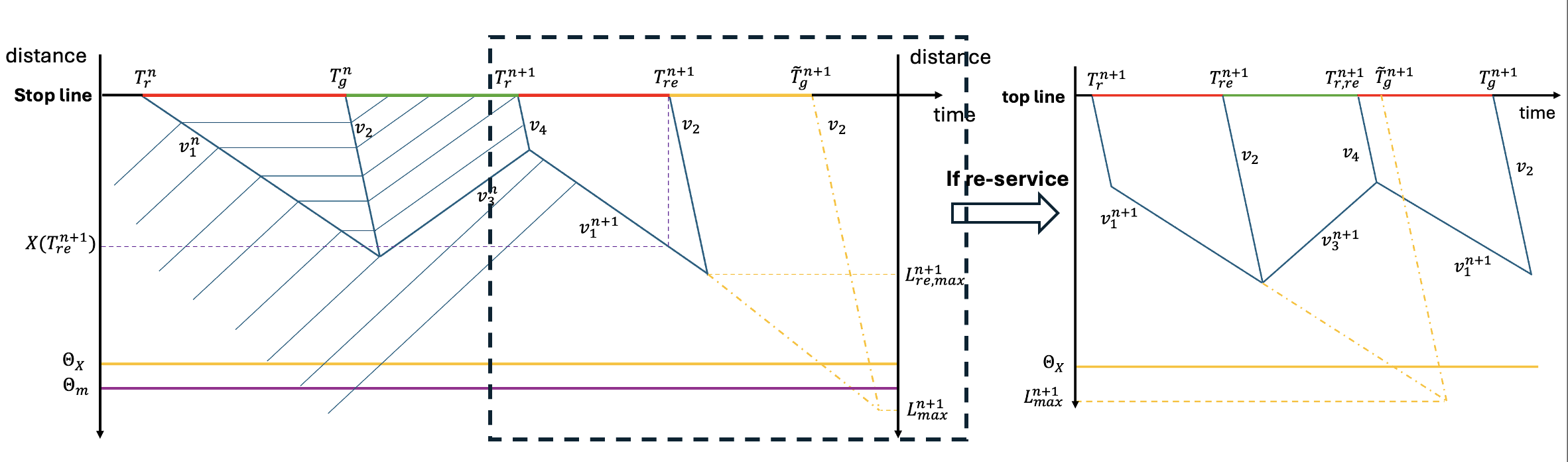
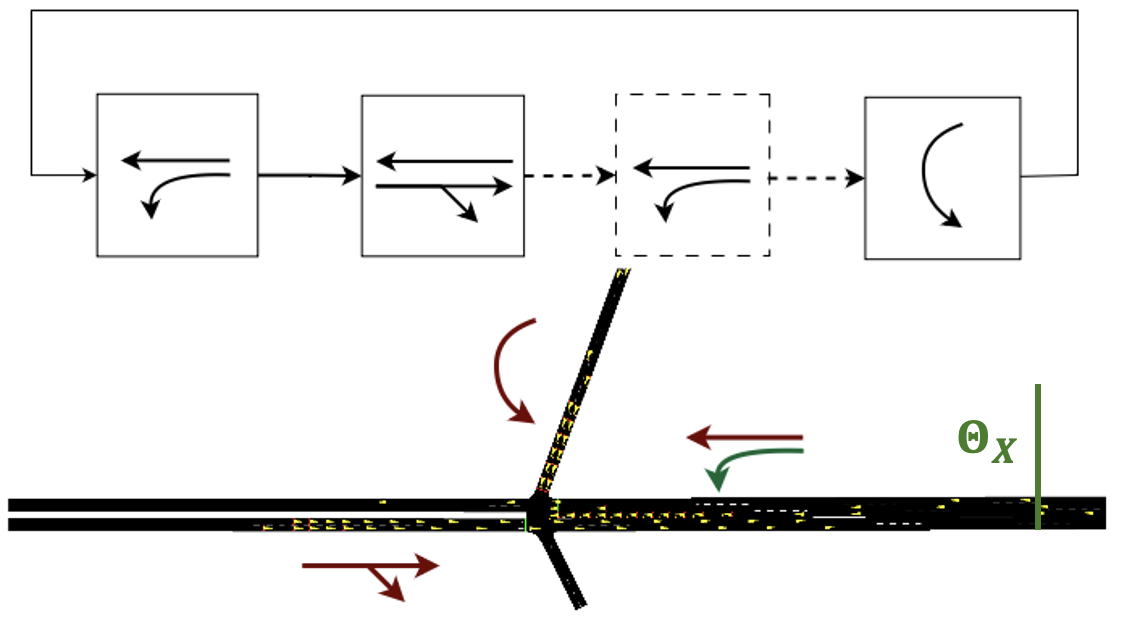
核心思路:本文的核心思路是将强化学习与相位重服务相结合,利用强化学习智能体学习最优的信号相位控制策略,并根据冲击波理论动态判断是否需要插入临时相位重服务。通过这种方式,可以更有效地利用道路资源,减少车辆延误和停车次数,提高交通效率。
技术框架:该方法的技术框架主要包括以下几个模块:1) 强化学习智能体:负责学习最优的信号相位控制策略,决定下一个相位的持续时间。2) 相位重服务决策模块:利用冲击波理论估计指定运动的排队扩展,并决定是否需要插入临时相位重服务。3) 交通仿真环境:用于模拟真实的交通状况,为强化学习智能体提供训练数据。4) 半马尔可夫决策过程(SMDP)建模:将交通信号控制问题建模为SMDP,以便使用强化学习算法进行求解。5) 近端策略优化(PPO)算法:用于训练强化学习智能体,使其能够学习到最优的信号相位控制策略。
关键创新:该方法最重要的技术创新点在于将相位重服务与强化学习相结合,提出了一种动态调整信号相位的策略。与传统的固定配时方案和简单的自适应控制策略相比,该方法能够根据实时交通状况灵活调整信号相位,更有效地利用道路资源,减少车辆延误和停车次数。此外,利用冲击波理论进行相位重服务决策也是一个创新点,可以更准确地估计排队长度,从而做出更合理的决策。
关键设计:在关键设计方面,该方法采用了半马尔可夫决策过程(SMDP)对交通信号控制问题进行建模,并使用近端策略优化(PPO)算法进行求解。SMDP能够更好地描述交通信号控制的动态特性,而PPO算法则具有较好的稳定性和收敛性。此外,在相位重服务决策模块中,需要仔细选择冲击波模型的参数,以确保排队长度估计的准确性。奖励函数的设计也至关重要,需要综合考虑车辆延误、停车次数等因素,以引导强化学习智能体学习到最优的控制策略。
🖼️ 关键图片
📊 实验亮点
实验结果表明,与传统方法相比,该方法在车辆延误和停车次数方面均有显著改善。车辆平均延误最多减少29.95%,延误标准差最多减少59.21%。停车次数平均减少26.05%,标准差减少45.77%。这些数据表明,该方法能够有效地提高交通效率和鲁棒性。
🎯 应用场景
该研究成果可应用于城市交通信号控制系统,尤其适用于交通流量变化较大的交叉口。通过优化信号相位,可以有效减少车辆延误和停车次数,提高道路通行能力,缓解交通拥堵,降低环境污染。未来,该方法可进一步扩展到区域交通信号协调控制,实现更大范围的交通优化。
📄 摘要(原文)
This article proposes a novel approach to traffic signal control that combines phase re-service with reinforcement learning (RL). The RL agent directly determines the duration of the next phase in a pre-defined sequence. Before the RL agent's decision is executed, we use the shock wave theory to estimate queue expansion at the designated movement allowed for re-service and decide if phase re-service is necessary. If necessary, a temporary phase re-service is inserted before the next regular phase. We formulate the RL problem as a semi-Markov decision process (SMDP) and solve it with proximal policy optimization (PPO). We conducted a series of experiments that showed significant improvements thanks to the introduction of phase re-service. Vehicle delays are reduced by up to 29.95% of the average and up to 59.21% of the standard deviation. The number of stops is reduced by 26.05% on average with 45.77% less standard deviation.