Federated Fine-Tuning for Pre-Trained Foundation Models Over Wireless Networks
作者: Zixin Wang, Yong Zhou, Yuanming Shi, Khaled. B. Letaief
分类: eess.SY
发布日期: 2024-07-03
💡 一句话要点
提出Split Federated LoRA框架,解决无线网络下联邦微调预训练大模型的资源限制问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 预训练模型 无线网络 低秩适应 边缘计算
📋 核心要点
- 现有联邦微调方法在无线网络环境下,受限于边缘设备的计算能力和无线资源,难以有效部署。
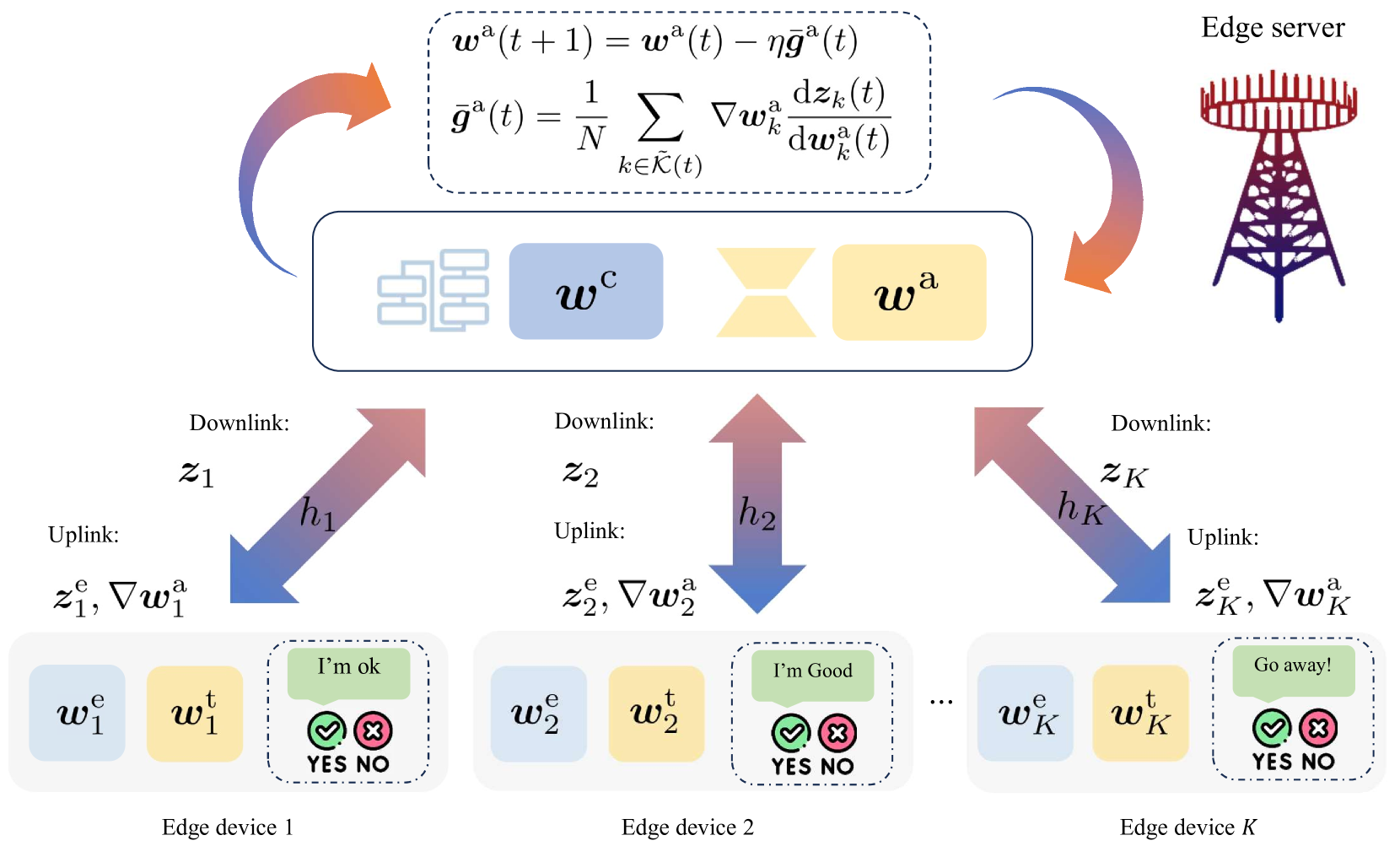
- 提出Split Federated LoRA框架,将计算密集型编码器置于边缘服务器,减轻边缘设备负担,优化资源分配。
- 通过在线算法进行设备调度和带宽分配,最小化收敛差距上界,仿真结果验证了算法的有效性。
📝 摘要(中文)
预训练大模型(FMs)拥有大量的神经元,是推动下一代智能服务的关键。个性化这些模型需要大量的特定任务数据和计算资源。目前流行的解决方案是在边缘服务器上进行集中处理,但这会因原始数据的传输而引发隐私问题。联邦微调(FedFT)是一种新兴的保护隐私的微调(FT)范例,用于个性化预训练大模型。特别是,通过将低秩适应(LoRA)与联邦学习(FL)相结合,联邦LoRA能够与边缘设备协同FT全局模型,在分布式数据上训练更少的参数,同时保持原始数据隐私,从而实现与完全FT相当的学习性能。然而,边缘设备有限的无线资源和计算能力对在无线网络上部署联邦LoRA提出了重大挑战。本文提出了一种split federated LoRA框架,该框架将预训练模型计算密集型的编码器部署在边缘服务器上,而将嵌入和任务模块保留在边缘设备上。在此split框架的基础上,本文对无线联邦LoRA系统的收敛差距的上界进行了严格的分析。该分析促使我们制定了一个长期上界最小化问题,我们使用Lyapunov技术将制定的长期混合整数规划(MIP)问题分解为顺序子问题。然后,我们开发了一种在线算法,用于有效的设备调度和带宽分配。仿真结果表明,所提出的在线算法在提高学习性能方面是有效的。
🔬 方法详解
问题定义:论文旨在解决无线网络环境下,联邦学习微调预训练大模型时,边缘设备计算资源和无线资源受限的问题。现有方法,如直接在边缘设备上进行联邦微调,会因设备算力不足和通信带宽限制而导致训练效率低下,甚至无法完成训练。
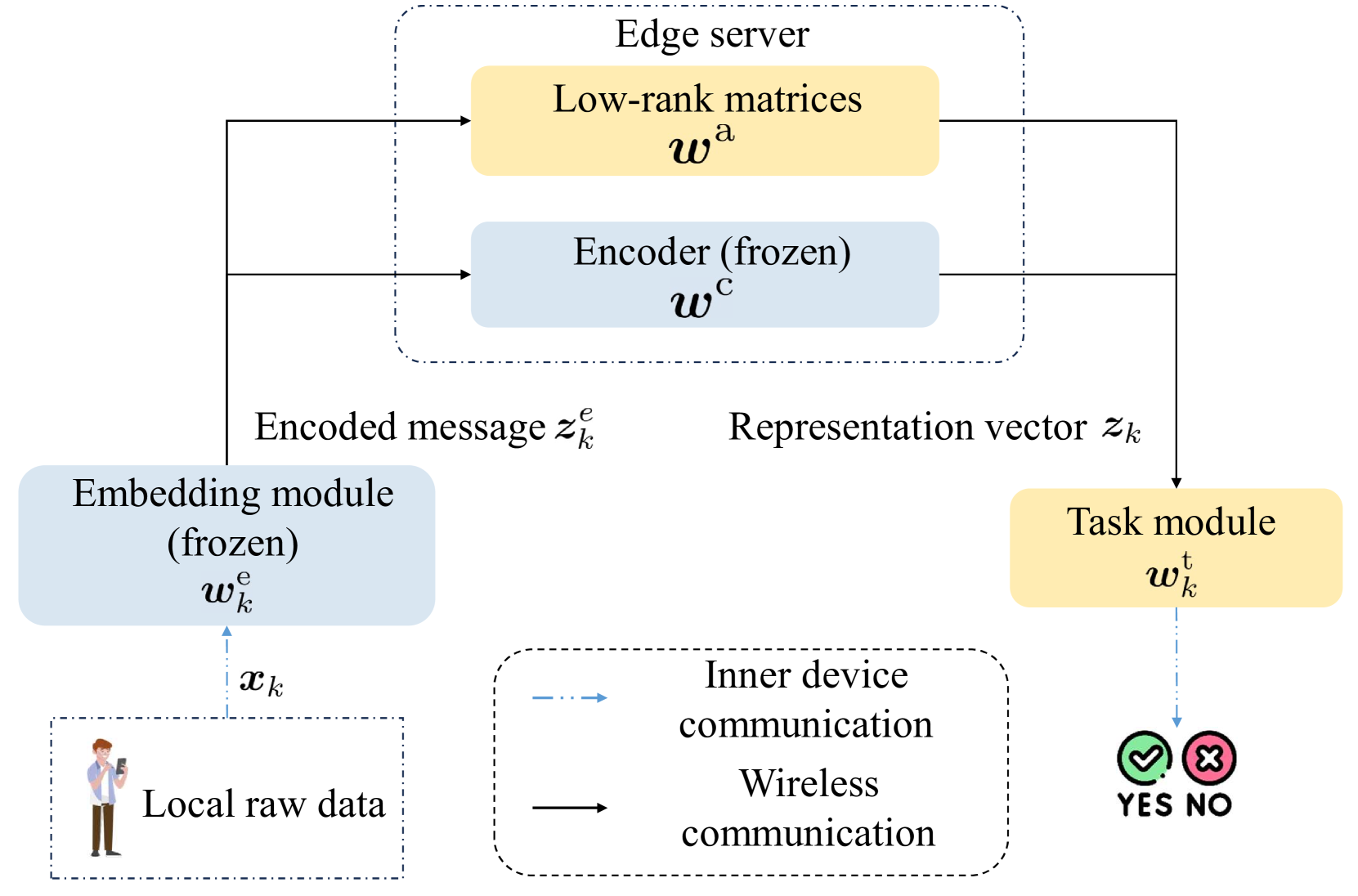
核心思路:论文的核心思路是将预训练模型的编码器部分部署在边缘服务器上,而将嵌入层和任务相关的模块保留在边缘设备上。这样可以利用边缘服务器的强大计算能力来处理编码器的计算密集型任务,减轻边缘设备的负担,同时通过联邦学习的方式保护用户数据的隐私。
技术框架:该框架主要包含以下几个模块:1) 边缘设备:负责存储本地数据,进行嵌入层和任务模块的计算,并将梯度上传到边缘服务器。2) 边缘服务器:负责存储和计算预训练模型的编码器部分,接收来自边缘设备的梯度,进行聚合,并将更新后的编码器参数广播回边缘设备。3) 无线网络:负责边缘设备和边缘服务器之间的通信,需要进行设备调度和带宽分配,以优化通信效率。整体流程是,边缘设备首先利用本地数据计算嵌入层和任务模块的梯度,然后将梯度上传到边缘服务器。边缘服务器利用接收到的梯度更新编码器的参数,并将更新后的参数广播回边缘设备。
关键创新:论文的关键创新在于提出了Split Federated LoRA框架,将预训练模型的不同部分部署在不同的设备上,从而实现了计算资源和通信资源的有效利用。此外,论文还提出了一个在线算法,用于设备调度和带宽分配,以最小化收敛差距的上界。
关键设计:论文使用Lyapunov优化技术将长期混合整数规划问题分解为一系列子问题,从而设计了一个在线算法。该算法根据设备的计算能力、无线信道质量和数据量等因素,动态地进行设备调度和带宽分配。此外,论文还对无线联邦LoRA系统的收敛差距的上界进行了严格的分析,为算法的设计提供了理论依据。
🖼️ 关键图片

📊 实验亮点
仿真结果表明,所提出的在线算法能够有效地提高学习性能。具体来说,该算法能够显著地减少模型的收敛时间,并提高模型的准确率。与传统的联邦学习算法相比,该算法在无线资源受限的情况下,能够更好地利用边缘设备的计算资源和无线资源,从而实现更好的学习效果。
🎯 应用场景
该研究成果可应用于各种需要个性化预训练大模型的场景,例如智能医疗、智能金融、智能交通等。通过联邦学习的方式,可以在保护用户数据隐私的前提下,利用分布式数据进行模型训练,提高模型的泛化能力和个性化程度。该研究对于推动联邦学习在实际应用中的落地具有重要意义。
📄 摘要(原文)
Pre-trained foundation models (FMs), with extensive number of neurons, are key to advancing next-generation intelligence services, where personalizing these models requires massive amount of task-specific data and computational resources. The prevalent solution involves centralized processing at the edge server, which, however, raises privacy concerns due to the transmission of raw data. Instead, federated fine-tuning (FedFT) is an emerging privacy-preserving fine-tuning (FT) paradigm for personalized pre-trained foundation models. In particular, by integrating low-rank adaptation (LoRA) with federated learning (FL), federated LoRA enables the collaborative FT of a global model with edge devices, achieving comparable learning performance to full FT while training fewer parameters over distributed data and preserving raw data privacy. However, the limited radio resources and computation capabilities of edge devices pose significant challenges for deploying federated LoRA over wireless networks. To this paper, we propose a split federated LoRA framework, which deploys the computationally-intensive encoder of a pre-trained model at the edge server, while keeping the embedding and task modules at the edge devices. Building on this split framework, the paper provides a rigorous analysis of the upper bound of the convergence gap for the wireless federated LoRA system. This analysis motivates the formulation of a long-term upper bound minimization problem, where we decompose the formulated long-term mixed-integer programming (MIP) problem into sequential sub-problems using the Lyapunov technique. We then develop an online algorithm for effective device scheduling and bandwidth allocation. Simulation results demonstrate the effectiveness of the proposed online algorithm in enhancing learning performance.