Enhanced Flight Envelope Protection: A Novel Reinforcement Learning Approach
作者: Akin Catak, Ege C. Altunkaya, Mustafa Demir, Emre Koyuncu, Ibrahim Ozkol
分类: eess.SY
发布日期: 2024-06-08 (更新: 2024-06-11)
💡 一句话要点
提出基于强化学习的飞行包线保护算法,提升飞行安全性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 飞行包线保护 飞行安全 控制算法 深度学习
📋 核心要点
- 传统飞行包线保护方法依赖手动调整,难以适应复杂飞行条件和非线性系统。
- 利用强化学习自动学习复杂控制策略,无需手动调整参数,简化设计流程。
- 实验结果表明,该方法能有效限制迎角、载荷系数和俯仰角速率,提升飞行安全性。
📝 摘要(中文)
本文提出了一种基于强化学习(RL)的纵向飞行包线保护算法。该算法通过考虑迎角、载荷系数和俯仰角速率等变量的限制,对抗飞行员或控制指令的过度操作,并采取恢复动作。与需要手动调整的传统方法不同,强化学习能够在训练模型中逼近复杂函数,从而简化设计过程。研究结果表明,强化学习在增强飞行包线保护方面具有良好的前景,为确保飞行安全提供了一种新颖且易于扩展的方法。
🔬 方法详解
问题定义:飞行包线保护旨在防止飞机超出安全飞行范围,避免失速、结构损坏等风险。传统方法依赖于人工设计的控制律和参数调整,难以应对复杂飞行环境和飞行器非线性特性,需要耗费大量时间和精力进行调试。
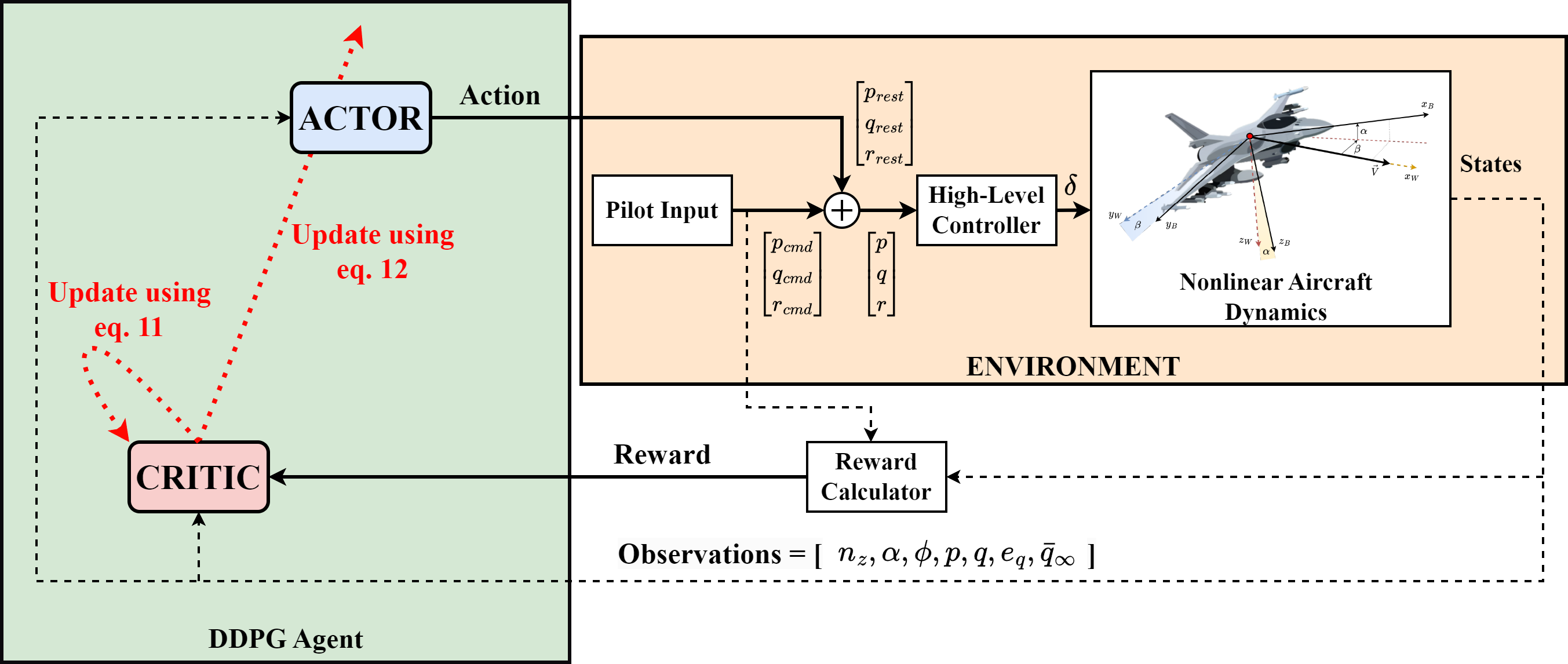
核心思路:本文的核心思路是利用强化学习算法,让智能体(Agent)通过与飞行环境的交互,自主学习最优的飞行包线保护策略。通过奖励函数引导智能体学习在满足约束条件(迎角、载荷系数等)的同时,尽可能地响应飞行员的指令。
技术框架:该方法构建了一个强化学习框架,主要包括以下几个模块:1. 飞行环境模型:模拟飞机的纵向运动特性。2. 智能体:采用深度神经网络作为策略网络,根据当前状态输出控制指令。3. 奖励函数:根据飞行状态和控制动作,给予智能体相应的奖励或惩罚,引导其学习安全的飞行策略。4. 训练过程:智能体与环境交互,不断调整策略网络参数,最终学习到最优的飞行包线保护策略。
关键创新:该方法最重要的创新在于将强化学习应用于飞行包线保护,无需人工设计复杂的控制律,而是通过数据驱动的方式自动学习最优策略。与传统方法相比,该方法具有更强的适应性和鲁棒性,能够更好地应对复杂飞行环境。
关键设计:奖励函数的设计至关重要,需要综合考虑飞行安全性和控制性能。例如,可以设置以下奖励:1. 保持在飞行包线内:给予正向奖励。2. 超出飞行包线:给予负向奖励。3. 响应飞行员指令:给予正向奖励。此外,策略网络可以选择深度Q网络(DQN)或Actor-Critic等结构,并采用合适的优化算法进行训练。
🖼️ 关键图片


📊 实验亮点
该研究通过强化学习算法实现了飞行包线保护,无需手动调整参数,简化了设计流程。实验结果表明,该方法能够有效地限制迎角、载荷系数和俯仰角速率等关键参数,防止飞机超出安全飞行范围。与传统方法相比,该方法具有更强的适应性和鲁棒性,能够更好地应对复杂飞行环境。
🎯 应用场景
该研究成果可应用于各种飞行器,包括民用飞机、无人机和军用飞机,提高飞行安全性,降低飞行事故率。此外,该方法还可扩展到其他控制领域,例如机器人控制和自动驾驶,实现更安全、更智能的控制系统。未来,该技术有望在航空航天领域发挥重要作用。
📄 摘要(原文)
This paper introduces a flight envelope protection algorithm on a longitudinal axis that leverages reinforcement learning (RL). By considering limits on variables such as angle of attack, load factor, and pitch rate, the algorithm counteracts excessive pilot or control commands with restoring actions. Unlike traditional methods requiring manual tuning, RL facilitates the approximation of complex functions within the trained model, streamlining the design process. This study demonstrates the promising results of RL in enhancing flight envelope protection, offering a novel and easy-to-scale method for safety-ensured flight.