Model Predictive Control and Reinforcement Learning: A Unified Framework Based on Dynamic Programming
作者: Dimitri P. Bertsekas
分类: eess.SY, cs.AI, math.OC
发布日期: 2024-06-02 (更新: 2024-06-30)
💡 一句话要点
提出基于动态规划的统一框架,桥接模型预测控制与强化学习
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 模型预测控制 动态规划 离线训练 在线博弈 序列决策 牛顿法
📋 核心要点
- 现有强化学习与模型预测控制在理论和实践上存在隔阂,阻碍了二者优势互补。
- 论文提出基于动态规划的统一框架,通过离线训练和在线博弈算法协同,桥接两者。
- 该框架借鉴AlphaZero和TD-Gammon的成功经验,为MPC的稳定性、不确定性处理等问题提供新思路。
📝 摘要(中文)
本文提出了一个全新的概念框架,将近似动态规划(DP)、模型预测控制(MPC)和强化学习(RL)联系起来。该框架围绕两个算法展开,这两个算法在很大程度上彼此独立设计,并通过牛顿法的强大机制协同工作。我们称它们为离线训练算法和在线博弈算法。这些名称借鉴自RL在游戏领域的一些重大成功案例;主要的例子包括最近的AlphaZero程序(下国际象棋)和早期的TD-Gammon程序(下西洋双陆棋)。在这些游戏环境中,离线训练算法是用于教导程序如何评估局面并在任何给定局面生成好的走法的方法,而在线博弈算法是用于实时与人类或计算机对手对弈的方法。
重要的是,离线训练和在线博弈之间的协同作用也是MPC的基础(以及其他主要类别的序列决策问题),事实上,MPC的设计架构与AlphaZero和TD-Gammon的架构非常相似。这种概念性的洞察力为弥合RL和MPC之间的文化差距提供了一种途径,并为MPC中的一些基本问题提供了新的思路。这些问题包括通过rollout增强稳定性,通过使用确定性等价处理不确定性,MPC在涉及系统参数变化的自适应控制设置中的弹性,以及牛顿法所隐含的超线性性能界限所提供的见解。
🔬 方法详解
问题定义:论文旨在弥合强化学习(RL)和模型预测控制(MPC)之间的理论和实践差距。现有的RL和MPC方法通常被视为独立的领域,缺乏统一的理论框架,导致难以结合两者的优点。例如,MPC在处理约束和稳定性方面表现出色,而RL则擅长处理未知环境和长期决策。
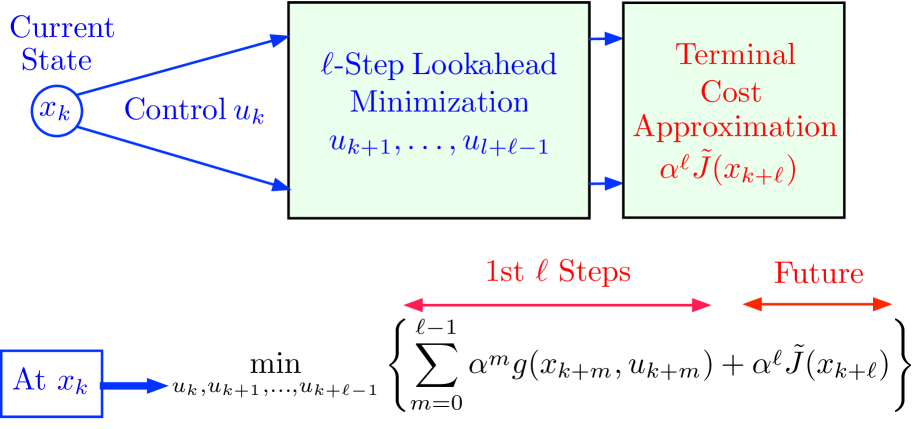
核心思路:论文的核心思路是利用动态规划(DP)作为桥梁,将RL和MPC统一到一个框架中。该框架借鉴了AlphaZero和TD-Gammon等成功案例的经验,采用离线训练和在线博弈相结合的策略。离线训练用于学习价值函数或策略,在线博弈则利用学习到的模型进行实时决策。
技术框架:该框架包含两个主要算法:离线训练算法和在线博弈算法。离线训练算法负责学习价值函数或策略,可以使用各种RL方法,如时序差分学习或策略梯度方法。在线博弈算法则利用离线训练得到的模型,通过模型预测控制或其他优化方法,进行实时决策。这两个算法通过牛顿法进行协同,从而提高整体性能。
关键创新:该框架的关键创新在于将RL和MPC统一到一个基于动态规划的框架中,并强调离线训练和在线博弈的协同作用。这种统一的视角有助于理解RL和MPC之间的联系,并为解决序列决策问题提供新的思路。此外,该框架还借鉴了AlphaZero和TD-Gammon等成功案例的经验,证明了离线训练和在线博弈相结合的有效性。
关键设计:论文没有提供具体的参数设置、损失函数或网络结构的细节,而是侧重于提出一个通用的框架。具体的实现细节取决于具体的应用场景和所使用的RL和MPC方法。然而,论文强调了牛顿法在协同离线训练和在线博弈中的作用,这可能涉及到对价值函数或策略的二阶导数进行估计和利用。
🖼️ 关键图片


📊 实验亮点
论文主要贡献在于框架的提出,并没有提供具体的实验结果。但论文借鉴了AlphaZero和TD-Gammon的成功经验,暗示了该框架在实际应用中具有潜力。未来的研究可以针对具体应用场景,验证该框架的有效性,并与其他基线方法进行比较。
🎯 应用场景
该研究成果可应用于机器人控制、自动驾驶、资源调度等领域。通过结合强化学习的自适应能力和模型预测控制的精确控制,可以提升系统在复杂环境下的性能和鲁棒性。例如,在自动驾驶中,可以利用该框架实现车辆在动态交通环境下的安全高效行驶。
📄 摘要(原文)
In this paper we describe a new conceptual framework that connects approximate Dynamic Programming (DP), Model Predictive Control (MPC), and Reinforcement Learning (RL). This framework centers around two algorithms, which are designed largely independently of each other and operate in synergy through the powerful mechanism of Newton's method. We call them the off-line training and the on-line play algorithms. The names are borrowed from some of the major successes of RL involving games; primary examples are the recent (2017) AlphaZero program (which plays chess, [SHS17], [SSS17]), and the similarly structured and earlier (1990s) TD-Gammon program (which plays backgammon, [Tes94], [Tes95], [TeG96]). In these game contexts, the off-line training algorithm is the method used to teach the program how to evaluate positions and to generate good moves at any given position, while the on-line play algorithm is the method used to play in real time against human or computer opponents. Significantly, the synergy between off-line training and on-line play also underlies MPC (as well as other major classes of sequential decision problems), and indeed the MPC design architecture is very similar to the one of AlphaZero and TD-Gammon. This conceptual insight provides a vehicle for bridging the cultural gap between RL and MPC, and sheds new light on some fundamental issues in MPC. These include the enhancement of stability properties through rollout, the treatment of uncertainty through the use of certainty equivalence, the resilience of MPC in adaptive control settings that involve changing system parameters, and the insights provided by the superlinear performance bounds implied by Newton's method.