Steerable Vision-Language-Action Policies for Embodied Reasoning and Hierarchical Control
作者: William Chen, Jagdeep Singh Bhatia, Catherine Glossop, Nikhil Mathihalli, Ria Doshi, Andy Tang, Danny Driess, Karl Pertsch, Sergey Levine
分类: cs.RO
发布日期: 2026-04-07
💡 一句话要点
提出可操纵的视觉-语言-动作策略,用于具身推理和分层控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 视觉-语言模型 机器人控制 分层控制 可操纵策略
📋 核心要点
- 现有方法依赖自然语言指令连接VLM和VLA,限制了VLM推理对低级行为的指导能力。
- 论文提出可操纵策略,通过在不同抽象级别的丰富合成命令上训练VLA,提高低级可控性。
- 实验表明,使用学习到的推理器或现成VLM控制可操纵策略,在泛化和长时程任务上优于现有方法。
📝 摘要(中文)
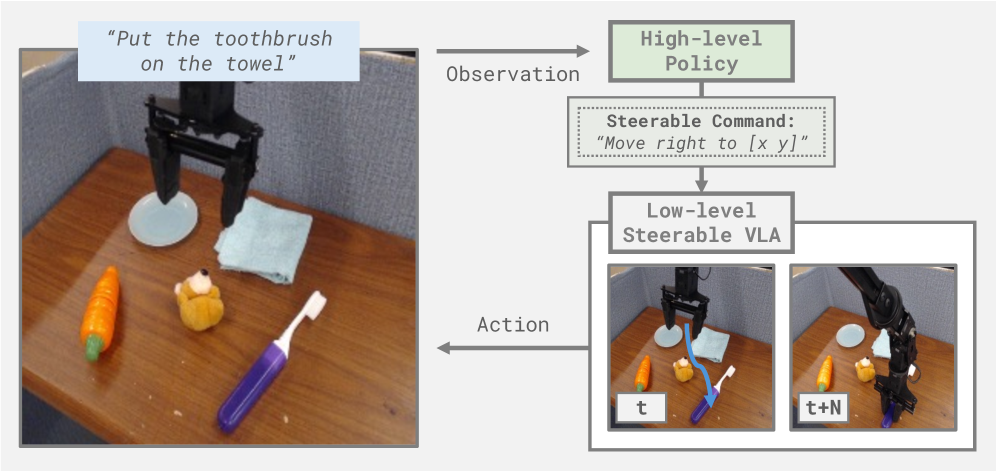
预训练的视觉-语言模型(VLM)可以在各种环境中进行语义和视觉推理,为机器人控制提供有价值的常识先验知识。然而,如何有效地将这些知识融入到机器人行为中仍然是一个开放的挑战。先前的方法通常采用分层方法,其中VLM推理高级命令,然后由单独的低级策略(例如,视觉-语言-动作模型(VLA))执行。VLM和VLA之间的接口通常是自然语言任务指令,这从根本上限制了VLM推理对低级行为的指导程度。因此,我们引入了可操纵策略:VLA在各种抽象级别的丰富合成命令上进行训练,例如子任务、动作和接地的像素坐标。通过提高低级可控性,可操纵策略可以解锁VLM中预训练的知识,从而提高任务泛化能力。我们通过使用学习到的高级具身推理器和现成的VLM(通过上下文学习推理命令抽象)来控制我们的可操纵策略,从而证明了这种优势。在广泛的真实世界操作实验中,这两种新方法优于先前的具身推理VLA和基于VLM的分层基线,包括在具有挑战性的泛化和长时程任务上。
🔬 方法详解
问题定义:现有方法在将预训练的视觉-语言模型(VLM)的知识迁移到机器人控制中存在瓶颈。具体来说,VLM通常通过自然语言指令与低级视觉-语言-动作模型(VLA)交互,这种交互方式限制了VLM对低级行为的精细控制,阻碍了任务泛化能力。现有方法难以充分利用VLM的推理能力来指导机器人的具体动作。
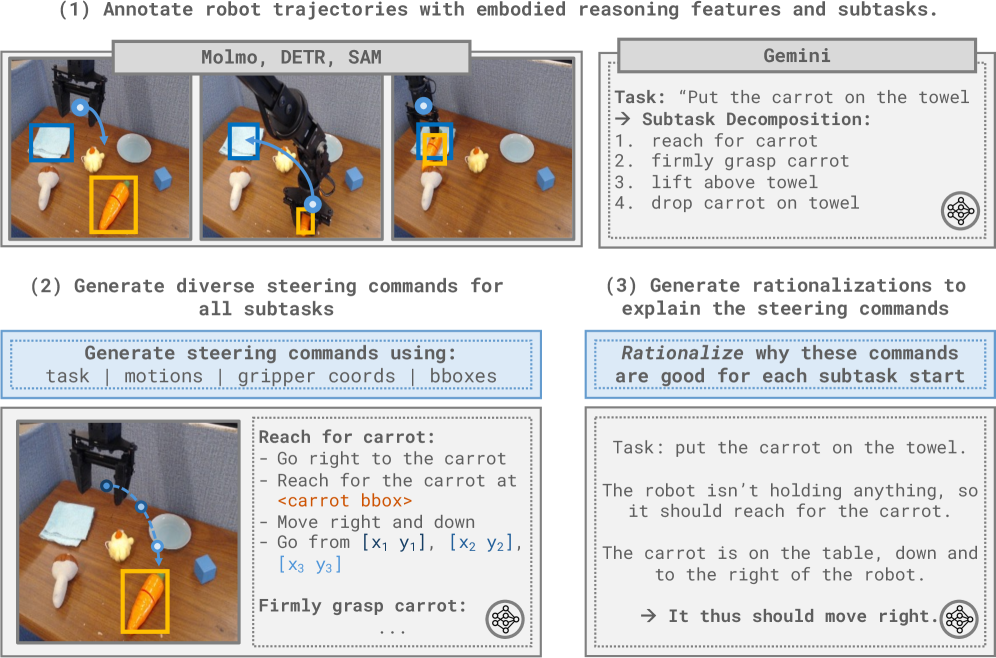
核心思路:论文的核心思路是通过训练“可操纵策略”(Steerable Policies)来提高低级VLA的可控性。这些策略不是简单地接收自然语言指令,而是在各种抽象级别的丰富合成命令上进行训练,包括子任务、动作和像素坐标等。这种更细粒度的控制接口允许VLM更有效地指导低级行为,从而解锁VLM中预训练的知识,提高任务泛化能力。
技术框架:整体框架包含两个主要部分:可操纵策略(Steerable Policies)和高级控制器。可操纵策略是低级VLA,负责执行具体的机器人动作。高级控制器可以是学习到的具身推理器,也可以是现成的VLM。高级控制器负责生成各种抽象级别的命令,这些命令被传递给可操纵策略,指导其执行相应的动作。整个流程形成一个分层控制结构,其中VLM的推理能力被用于指导低级策略的执行。
关键创新:最重要的技术创新点在于可操纵策略的设计。与传统的VLA不同,可操纵策略不是简单地接收自然语言指令,而是在更丰富、更细粒度的合成命令上进行训练。这种训练方式使得可操纵策略能够更好地响应VLM的推理结果,实现更精确的控制。此外,论文还探索了使用现成的VLM通过上下文学习来生成命令,进一步提高了系统的灵活性和泛化能力。
关键设计:论文中关于可操纵策略的训练数据生成是一个关键设计。通过合成各种抽象级别的命令,包括子任务、动作和像素坐标等,可以使VLA学习到更丰富的控制策略。此外,损失函数的设计也至关重要,需要平衡不同抽象级别命令的影响,并确保VLA能够准确地执行相应的动作。具体的网络结构和参数设置在论文中没有详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用学习到的高级推理器和现成的VLM控制可操纵策略,在真实世界的操作任务中优于现有的具身推理VLA和基于VLM的分层基线。尤其在具有挑战性的泛化和长时程任务上,性能提升显著,证明了可操纵策略的有效性和优越性。具体的性能数据和提升幅度在论文中没有明确给出,属于未知信息。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,例如家庭服务机器人、工业自动化和医疗机器人等。通过提高机器人对复杂任务的理解和执行能力,可以实现更智能、更自主的机器人系统。未来,该技术有望推动机器人技术在更多领域的应用,并为人类提供更便捷、更高效的服务。
📄 摘要(原文)
Pretrained vision-language models (VLMs) can make semantic and visual inferences across diverse settings, providing valuable common-sense priors for robotic control. However, effectively grounding this knowledge in robot behaviors remains an open challenge. Prior methods often employ a hierarchical approach where VLMs reason over high-level commands to be executed by separate low-level policies, e.g., vision-language-action models (VLAs). The interface between VLMs and VLAs is usually natural language task instructions, which fundamentally limits how much VLM reasoning can steer low-level behavior. We thus introduce Steerable Policies: VLAs trained on rich synthetic commands at various levels of abstraction, like subtasks, motions, and grounded pixel coordinates. By improving low-level controllability, Steerable Policies can unlock pretrained knowledge in VLMs, enabling improved task generalization. We demonstrate this benefit by controlling our Steerable Policies with both a learned high-level embodied reasoner and an off-the-shelf VLM prompted to reason over command abstractions via in-context learning. Across extensive real-world manipulation experiments, these two novel methods outperform prior embodied reasoning VLAs and VLM-based hierarchical baselines, including on challenging generalization and long-horizon tasks.Website:this http URL