PALM: Progress-Aware Policy Learning via Affordance Reasoning for Long-Horizon Robotic Manipulation
作者: Yuanzhe Liu, Jingyuan Zhu, Yuchen Mo, Gen Li, Xu Cao, Jin Jin, Yifan Shen, Zhengyuan Li, Tianjiao Yu, Wenzhen Yuan, Fangqiang Ding, Ismini Lourentzou
分类: cs.RO
发布日期: 2026-04-07
💡 一句话要点
PALM:基于可供性推理和进度感知策略学习的长程机器人操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 视觉-语言-动作模型 可供性推理 长程任务 策略学习 进度感知 机器人控制 人工智能
📋 核心要点
- 现有VLA模型在长程机器人操作中面临挑战,缺乏有效的内部推理机制来识别关键交互线索和跟踪任务进度。
- PALM框架通过可供性推理和子任务进度感知来构建策略学习,从而实现更稳定和高效的长程任务执行。
- 实验结果表明,PALM在模拟和真实环境中均显著优于现有基线方法,提升了长程任务的成功率和泛化能力。
📝 摘要(中文)
视觉-语言-动作(VLA)模型在机器人操作领域展现出潜力,但仍难以处理长程、多步骤任务。现有方法缺乏识别任务相关交互线索或跟踪子任务进度的内部推理机制,导致重复动作、遗漏步骤和过早终止等严重执行错误。为了解决这些挑战,我们提出了PALM,一个VLA框架,围绕以交互为中心的可供性推理和子任务进度线索来构建策略学习。PALM提炼出互补的可供性表示,捕捉对象相关性、接触几何、空间位置和运动动力学,并作为视觉运动控制的任务相关锚点。为了进一步稳定长程执行,PALM预测子任务内的连续进度,从而实现无缝的子任务转换。在广泛的模拟和真实世界实验中,PALM始终优于基线方法,在LIBERO-LONG上实现了91.8%的成功率,在CALVIN ABC->D上平均长度提高了12.5%,并且在三个长程泛化设置中,真实世界性能提升了2倍。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型在处理长程、多步骤机器人操作任务时,由于缺乏有效的内部推理机制,难以准确识别任务相关的交互线索,也无法有效跟踪子任务的执行进度,从而导致一系列问题,如重复执行动作、遗漏关键步骤以及过早终止任务等。这些问题严重影响了机器人完成复杂任务的能力。
核心思路:PALM的核心思路是构建一个以交互为中心的可供性推理框架,并结合子任务进度感知机制,从而提升VLA模型在长程任务中的表现。通过可供性推理,模型能够更好地理解对象之间的交互关系,并将其作为视觉运动控制的锚点。同时,通过预测子任务的执行进度,模型能够更平滑地进行子任务之间的切换,避免出现上述的执行错误。
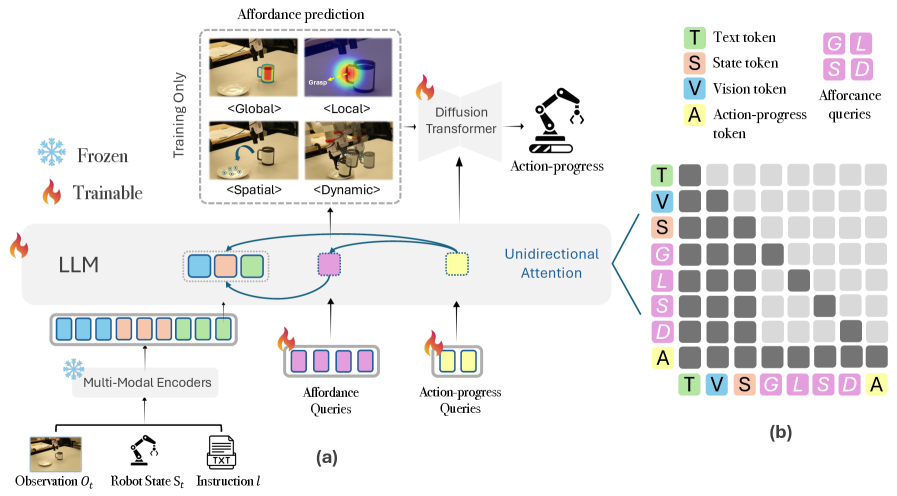
技术框架:PALM框架主要包含以下几个关键模块:1) 可供性表示模块:用于提取对象相关性、接触几何、空间位置和运动动力学等信息,形成互补的可供性表示。2) 策略学习模块:基于可供性表示,学习执行动作的策略。3) 进度预测模块:预测当前子任务的执行进度,用于平滑子任务之间的切换。整个框架通过端到端的方式进行训练,从而实现长程任务的有效执行。
关键创新:PALM最重要的创新在于其将可供性推理和子任务进度感知相结合,从而解决了现有VLA模型在长程任务中面临的挑战。与现有方法相比,PALM能够更准确地识别任务相关的交互线索,并更有效地跟踪子任务的执行进度,从而显著提升了长程任务的成功率和稳定性。
关键设计:在可供性表示模块中,论文采用了多种不同的网络结构来提取不同的可供性信息,例如,使用卷积神经网络来提取图像特征,使用图神经网络来建模对象之间的关系。在策略学习模块中,论文采用了Transformer结构来学习动作策略。在进度预测模块中,论文使用循环神经网络来预测子任务的执行进度。损失函数方面,论文采用了交叉熵损失函数和均方误差损失函数,分别用于策略学习和进度预测。
🖼️ 关键图片
📊 实验亮点
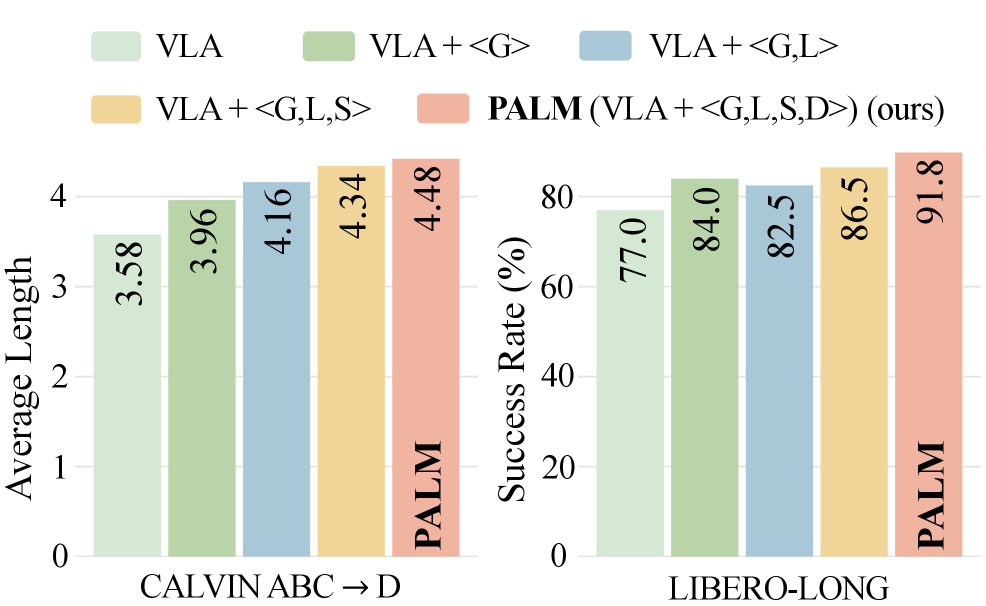
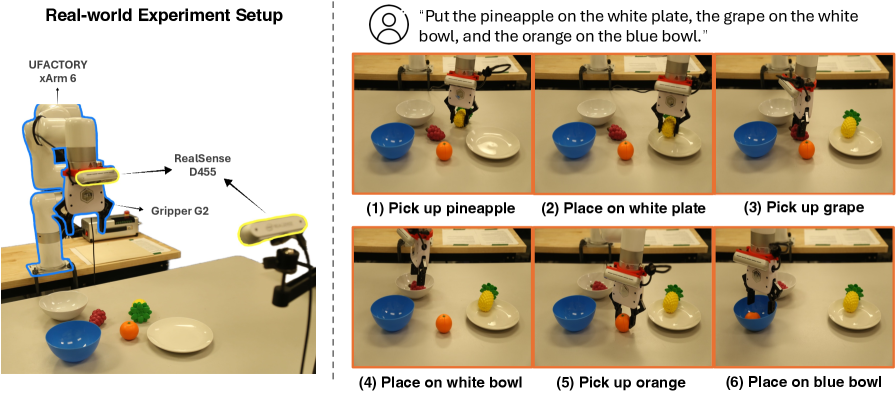
PALM在LIBERO-LONG数据集上实现了91.8%的成功率,显著优于现有基线方法。在CALVIN ABC->D数据集上,PALM的平均任务完成长度提高了12.5%。在真实世界实验中,PALM在三个长程泛化设置中,性能提升了2倍,证明了其在实际应用中的有效性和泛化能力。这些实验结果充分表明,PALM在长程机器人操作任务中具有显著的优势。
🎯 应用场景
PALM框架在机器人操作领域具有广泛的应用前景,例如,可应用于自动化装配、家庭服务机器人、医疗机器人等场景。通过提升机器人对长程复杂任务的理解和执行能力,PALM能够显著提高生产效率和服务质量,并为未来的智能机器人发展奠定基础。该研究的成果也有助于推动人工智能在其他领域的应用,例如,智能交通、智能制造等。
📄 摘要(原文)
Recent advancements in vision-language-action (VLA) models have shown promise in robotic manipulation, yet they continue to struggle with long-horizon, multi-step tasks. Existing methods lack internal reasoning mechanisms that can identify task-relevant interaction cues or track progress within a subtask, leading to critical execution errors such as repeated actions, missed steps, and premature termination. To address these challenges, we introduce PALM, a VLA framework that structures policy learning around interaction-centric affordance reasoning and subtask progress cues. PALM distills complementary affordance representations that capture object relevance, contact geometry, spatial placements, and motion dynamics, and serve as task-relevant anchors for visuomotor control. To further stabilize long-horizon execution, PALM predicts continuous within-subtask progress, enabling seamless subtask transitions. Across extensive simulation and real-world experiments, PALM consistently outperforms baselines, achieving a 91.8% success rate on LIBERO-LONG, a 12.5% improvement in average length on CALVIN ABC->D, and a 2x improvement over real-world baselines across three long-horizon generalization settings.