RAPTOR: A Foundation Policy for Quadrotor Control
作者: Jonas Eschmann, Dario Albani, Giuseppe Loianno
分类: cs.RO, cs.AI, cs.LG
发布日期: 2026-04-07
💡 一句话要点
提出RAPTOR以解决四旋翼控制的适应性问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 四旋翼控制 元模仿学习 零-shot适应 强化学习 神经网络策略
📋 核心要点
- 现有的强化学习方法在面对新环境时表现出过拟合,难以适应小的变化,如仿真到现实的差距。
- RAPTOR方法通过元模仿学习算法训练一个适应性强的基础策略,能够控制多种不同类型的四旋翼。
- 实验结果显示,所提出的策略在多种条件下均能实现零-shot适应,且在不同的四旋翼上表现出色。
📝 摘要(中文)
人类在适应新环境时表现出极高的数据效率,而现代机器人控制系统,如基于强化学习的神经网络策略,通常对单一环境高度专门化,导致在小的环境变化下容易失效。为此,本文提出RAPTOR,一种用于四旋翼控制的高度适应性基础策略训练方法。该方法通过训练一个单一的端到端神经网络策略,能够控制多种四旋翼。实验表明,具有2084个参数的三层小型策略能够实现对多种平台的零-shot适应,且在数毫秒内完成适应。
🔬 方法详解
问题定义:本文旨在解决现有四旋翼控制策略在面对新环境时的适应性不足问题,尤其是强化学习策略在小变化下的过拟合现象。
核心思路:提出RAPTOR方法,通过训练一个单一的神经网络策略,使其能够适应多种四旋翼平台,利用上下文学习实现快速适应。
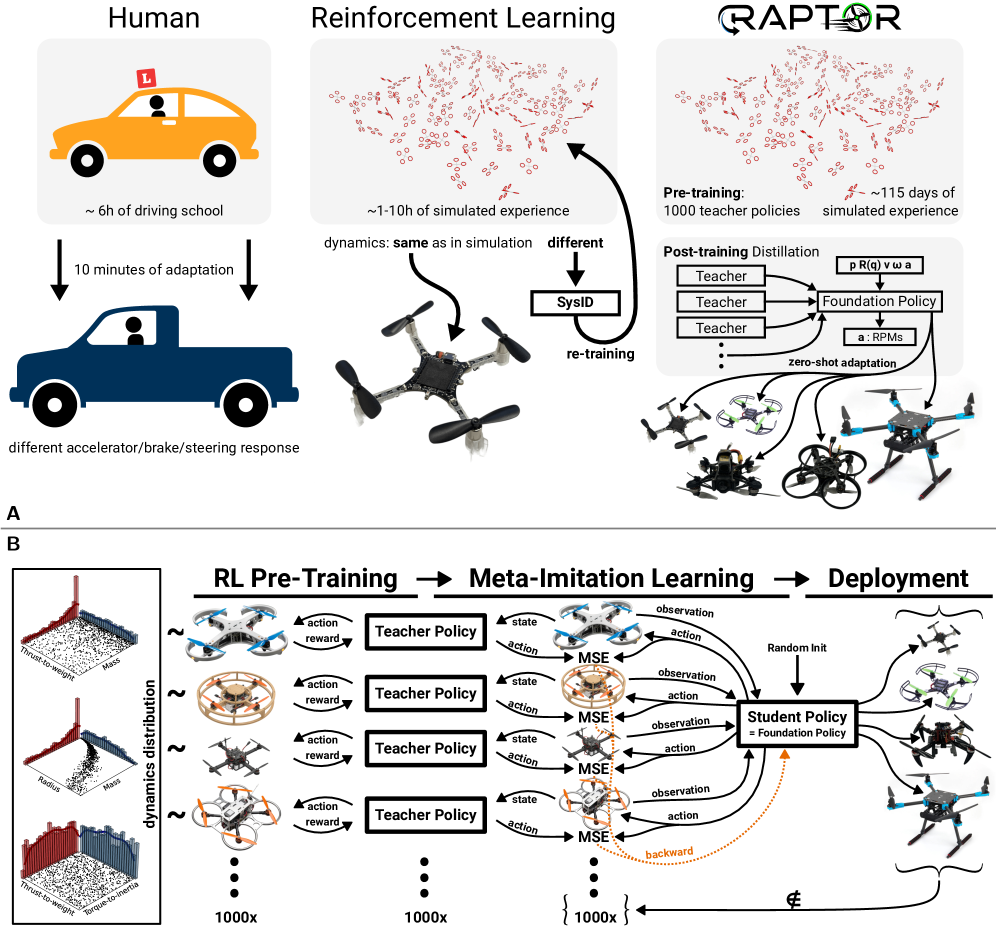
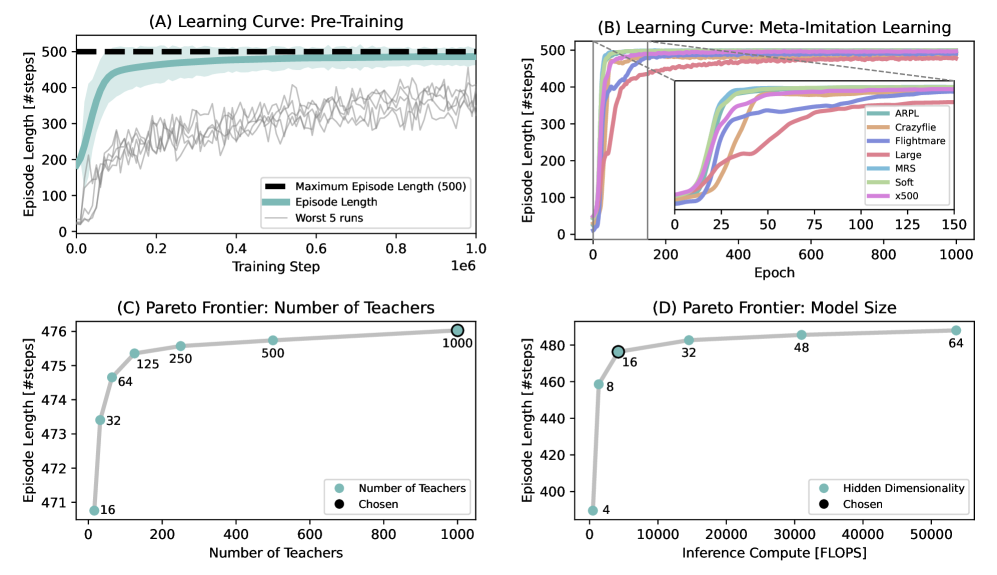
技术框架:整体架构包括两个主要阶段:首先为1000个四旋翼训练教师策略,然后将这些教师策略蒸馏为一个适应性学生策略。
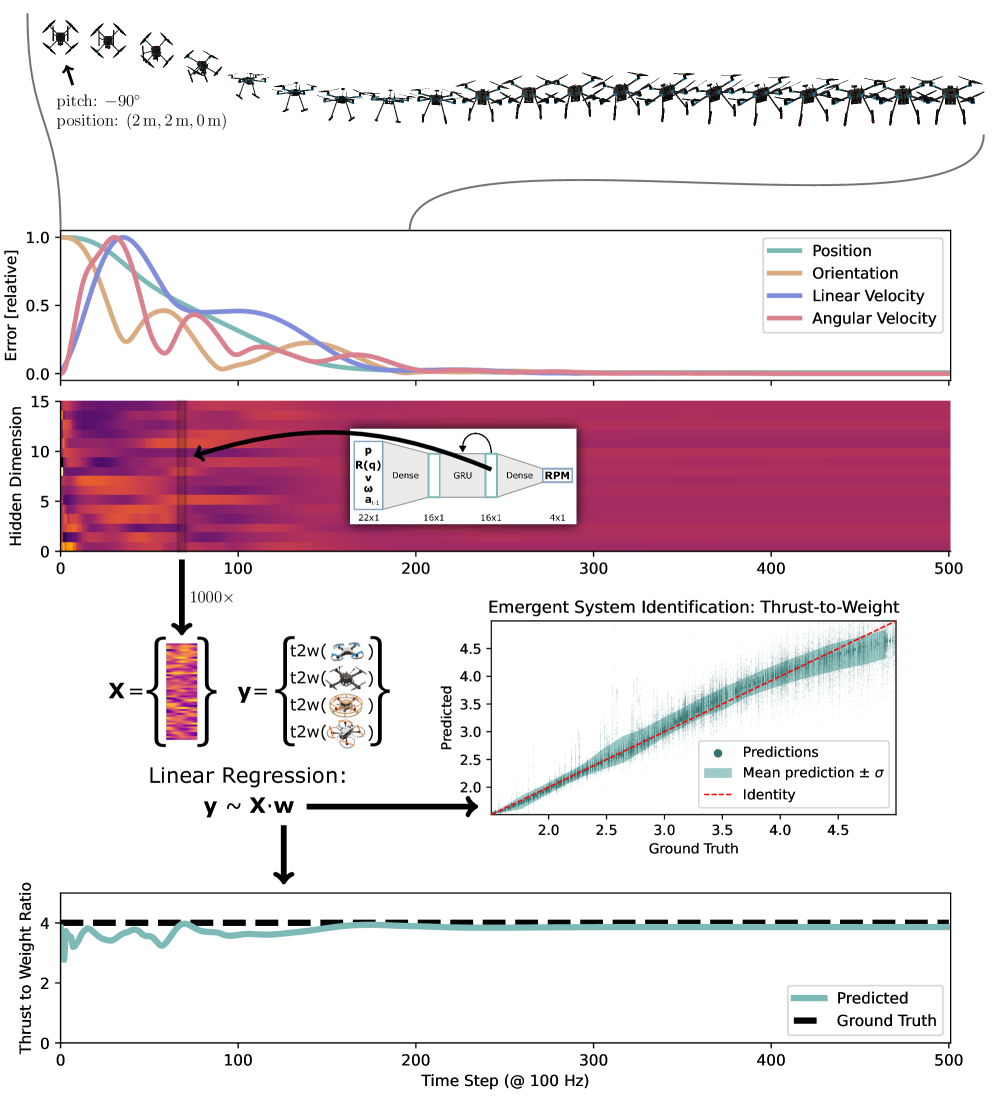
关键创新:最重要的创新在于使用了隐藏层的递归结构,使得策略能够在数毫秒内实现对未见四旋翼的零-shot适应,显著提高了适应能力。
关键设计:该策略采用三层结构,仅有2084个参数,使用元模仿学习算法进行训练,确保了在多种飞行条件下的有效性。具体的损失函数和参数设置在论文中详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RAPTOR方法在10种不同的四旋翼上实现了零-shot适应,且在各种条件下(如轨迹跟踪、室内外飞行、风干扰等)均表现出色,显示出显著的适应能力提升。
🎯 应用场景
RAPTOR方法在无人机控制、自动驾驶和机器人导航等领域具有广泛的应用潜力。其高适应性使得机器人能够在多变的环境中快速调整策略,提升操作效率和安全性。未来,该技术可能推动更智能的自主系统的发展。
📄 摘要(原文)
Humans are remarkably data-efficient when adapting to new unseen conditions, like driving a new car. In contrast, modern robotic control systems, like neural network policies trained using Reinforcement Learning (RL), are highly specialized for single environments. Because of this overfitting, they are known to break down even under small differences like the Simulation-to-Reality (Sim2Real) gap and require system identification and retraining for even minimal changes to the system. In this work, we present RAPTOR, a method for training a highly adaptive foundation policy for quadrotor control. Our method enables training a single, end-to-end neural-network policy to control a wide variety of quadrotors. We test 10 different real quadrotors from 32 g to 2.4 kg that also differ in motor type (brushed vs. brushless), frame type (soft vs. rigid), propeller type (2/3/4-blade), and flight controller (PX4/Betaflight/Crazyflie/M5StampFly). We find that a tiny, three-layer policy with only 2084 parameters is sufficient for zero-shot adaptation to a wide variety of platforms. The adaptation through in-context learning is made possible by using a recurrence in the hidden layer. The policy is trained through our proposed Meta-Imitation Learning algorithm, where we sample 1000 quadrotors and train a teacher policy for each of them using RL. Subsequently, the 1000 teachers are distilled into a single, adaptive student policy. We find that within milliseconds, the resulting foundation policy adapts zero-shot to unseen quadrotors. We extensively test the capabilities of the foundation policy under numerous conditions (trajectory tracking, indoor/outdoor, wind disturbance, poking, different propellers).