Embodied-R1: Reinforced Embodied Reasoning for General Robotic Manipulation
作者: Yifu Yuan, Haiqin Cui, Yaoting Huang, Yibin Chen, Fei Ni, Zibin Dong, Pengyi Li, Yan Zheng, Hongyao Tang, Jianye Hao
分类: cs.RO, cs.AI, cs.LG
发布日期: 2026-04-07
💡 一句话要点
Embodied-R1:强化具身推理,实现通用机器人操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 机器人操作 视觉语言模型 强化学习 零样本泛化
📋 核心要点
- 现有具身AI方法在泛化性方面存在不足,主要受限于数据稀缺和不同机器人平台之间的差异。
- 论文提出以“指向”作为统一的中间表示,连接视觉语言理解和底层动作,实现跨平台的通用操作。
- Embodied-R1模型在多个基准测试中达到SOTA,并在真实机器人任务中展现出强大的零样本泛化能力。
📝 摘要(中文)
具身AI的泛化能力受到“视觉到动作鸿沟”的限制,这源于数据稀缺和具身异构性。为了解决这个问题,我们率先提出“指向”作为一种统一的、与具身无关的中间表示,定义了四个核心的具身指向能力,将高层视觉-语言理解与低层动作原语连接起来。我们引入了Embodied-R1,一个专门为具身推理和指向设计的30亿参数视觉-语言模型(VLM)。我们使用广泛的具身和通用视觉推理数据集作为来源,构建了一个大规模数据集Embodied-Points-200K,它支持关键的具身指向能力。然后,我们使用一个专门的多任务奖励设计的两阶段强化微调(RFT)课程来训练Embodied-R1。Embodied-R1在11个具身空间和指向基准测试中取得了最先进的性能。关键的是,它通过在SIMPLEREnv中达到56.2%的成功率,并在8个真实世界的XArm任务中达到87.5%的成功率,展示了强大的零样本泛化能力,比强大的基线提高了62%。此外,该模型对各种视觉干扰表现出很高的鲁棒性。我们的工作表明,以指向为中心的表示,结合RFT训练范式,为缩小机器人中的感知-动作差距提供了一条有效且通用的途径。
🔬 方法详解
问题定义:现有具身AI方法难以泛化到不同的机器人平台和任务中,主要原因是“视觉到动作鸿沟”,即高层视觉理解和底层动作执行之间存在差距。数据稀缺性和不同机器人平台的异构性加剧了这个问题。现有方法通常需要针对特定任务进行大量训练,难以适应新的环境和机器人。
核心思路:论文的核心思路是将“指向”作为一种统一的、与具身无关的中间表示。通过让模型学习如何根据视觉和语言指令指向目标对象,可以将高层视觉-语言理解与低层动作原语连接起来。这种方法降低了对特定机器人平台和任务的依赖,从而提高了泛化能力。
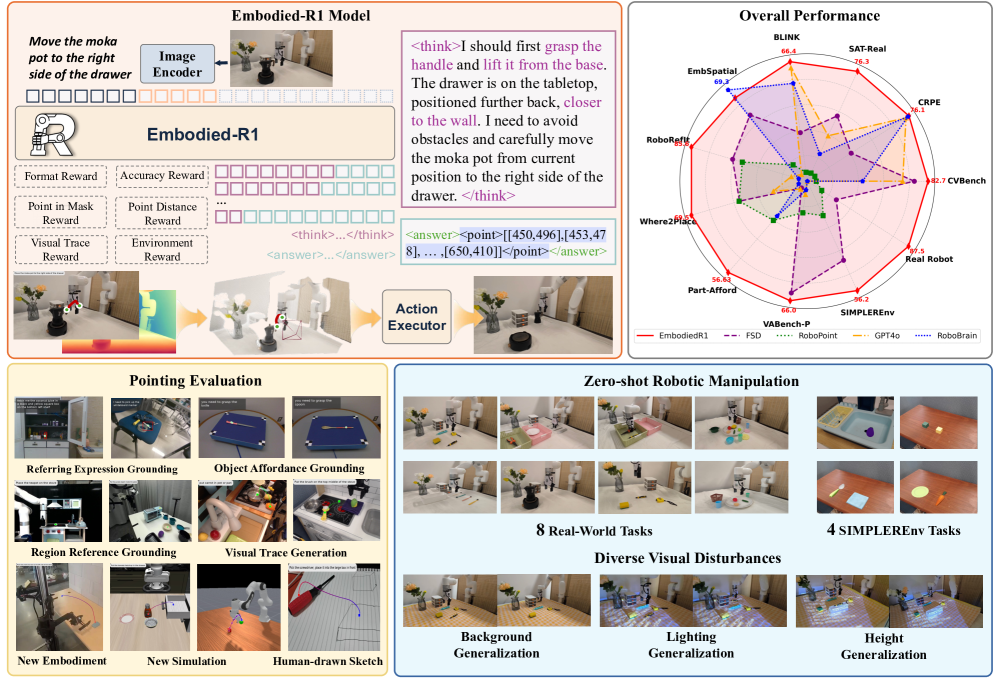
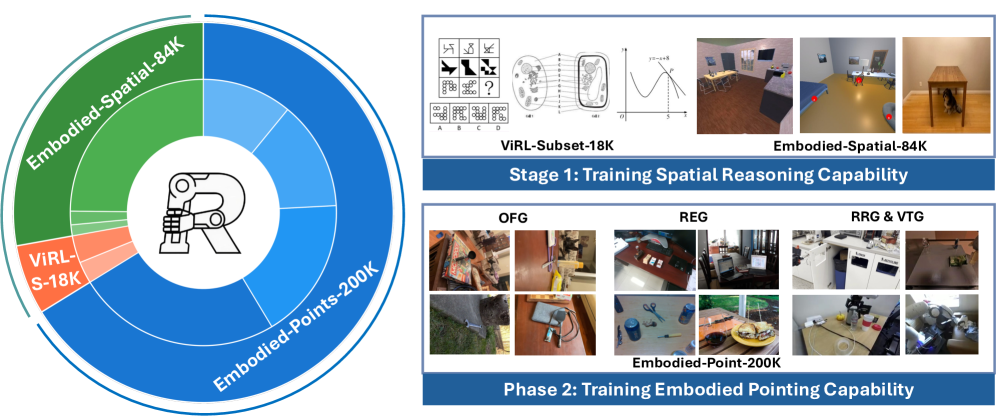
技术框架:Embodied-R1的整体框架包含以下几个主要模块:1) 视觉-语言模型(VLM):用于理解视觉输入和语言指令;2) 指向模块:用于根据VLM的输出,生成指向目标对象的动作;3) 强化微调(RFT)模块:用于优化模型的指向能力和整体性能。训练过程包括两个阶段:首先,使用大规模数据集进行预训练;然后,使用RFT进行微调。
关键创新:论文最重要的技术创新点在于提出了“指向”作为一种统一的中间表示。与现有方法直接学习从视觉输入到动作的映射不同,Embodied-R1学习如何指向目标对象,从而解耦了视觉理解和动作执行。这种方法使得模型可以更容易地泛化到不同的机器人平台和任务中。
关键设计:Embodied-R1的关键设计包括:1) 大规模数据集Embodied-Points-200K,用于训练模型的指向能力;2) 两阶段强化微调(RFT)课程,包括预训练和微调两个阶段;3) 多任务奖励设计,用于优化模型的指向精度、动作效率和任务完成率。具体来说,RFT阶段使用PPO算法,奖励函数结合了指向精度、动作步数和任务成功与否等因素。
🖼️ 关键图片

📊 实验亮点
Embodied-R1在11个具身空间和指向基准测试中取得了SOTA性能。更重要的是,它在SIMPLEREnv中实现了56.2%的成功率,并在8个真实世界的XArm任务中实现了87.5%的成功率,无需任何特定任务的微调。与强大的基线相比,零样本泛化能力提高了62%,同时对视觉干扰表现出很高的鲁棒性。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,例如家庭服务机器人、工业自动化机器人和医疗辅助机器人。通过提高机器人的泛化能力,可以使其更好地适应不同的环境和任务,从而提高工作效率和安全性。未来,该技术有望实现更智能、更灵活的机器人系统。
📄 摘要(原文)
Generalization in embodied AI is hindered by the "seeing-to-doing gap," which stems from data scarcity and embodiment heterogeneity. To address this, we pioneer "pointing" as a unified, embodiment-agnostic intermediate representation, defining four core embodied pointing abilities that bridge high-level vision-language comprehension with low-level action primitives. We introduce Embodied-R1, a 3B Vision-Language Model (VLM) specifically designed for embodied reasoning and pointing. We use a wide range of embodied and general visual reasoning datasets as sources to construct a large-scale dataset, Embodied-Points-200K, which supports key embodied pointing capabilities. We then train Embodied-R1 using a two-stage Reinforced Fine-tuning (RFT) curriculum with a specialized multi-task reward design. Embodied-R1 achieves state-of-the-art performance on 11 embodied spatial and pointing benchmarks. Critically, it demonstrates robust zero-shot generalization by achieving a 56.2% success rate in the SIMPLEREnv and 87.5% across 8 real-world XArm tasks without any task-specific fine-tuning, representing a 62% improvement over strong baselines. Furthermore, the model exhibits high robustness against diverse visual disturbances. Our work shows that a pointing-centric representation, combined with an RFT training paradigm, offers an effective and generalizable pathway to closing the perception-action gap in robotics.