MoE-ACT: Scaling Multi-Task Bimanual Manipulation with Sparse Language-Conditioned Mixture-of-Experts Transformers
作者: Kangjun Guo, Haichao Liu, Yanji Sun, Ruhan Zhao, Jinni Zhou, Jun Ma
分类: cs.RO
发布日期: 2026-03-16
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出MoE-ACT,通过稀疏MoE Transformer提升多任务双臂操作模仿学习性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多任务学习 模仿学习 双臂操作 混合专家模型 Transformer 机器人控制 语言条件 动作生成
📋 核心要点
- 现有通用机器人策略在多任务学习中面临任务间干扰和负迁移的问题,源于任务间分布差异。
- MoE-ACT通过将稀疏MoE模块集成到Transformer中,将统一策略分解为多个专家,解耦任务动作分布。
- 实验结果表明,MoE-ACT在多任务双臂操作中显著优于vanilla ACT,成功率平均提升33%。
📝 摘要(中文)
本文提出了一种轻量级的多任务模仿学习框架,用于双臂操作,称为混合专家增强动作分块Transformer (MoE-ACT)。该框架将稀疏混合专家(MoE)模块集成到ACT的Transformer编码器中。MoE层将统一的任务策略分解为独立调用的专家组件,通过自适应激活,自然地解耦潜在空间中的多任务动作分布。在解码过程中,特征线性调制(FiLM)动态地调制动作tokens,以提高动作生成和任务指令之间的一致性。同时,多尺度交叉注意力使策略能够同时关注低级和高级语义特征,为机器人操作提供丰富的视觉信息。进一步整合文本信息,将框架从纯视觉模型转变为以视觉为中心、语言条件动作生成系统。在模拟和真实世界的双臂设置中的实验验证表明,MoE-ACT显著提高了多任务性能。具体而言,MoE-ACT的成功率比vanilla ACT平均提高了33%。这些结果表明,MoE-ACT在复杂的多任务双臂操作环境中提供了更强的鲁棒性和泛化能力。
🔬 方法详解
问题定义:现有机器人策略在处理多任务时,由于任务间分布差异大,容易出现任务干扰和负迁移现象,导致整体性能下降。尤其是在双臂操作这种复杂场景下,如何训练一个通用的、鲁棒的多任务策略是一个挑战。
核心思路:MoE-ACT的核心思路是利用混合专家模型(MoE)将一个统一的策略分解成多个独立的专家,每个专家负责处理特定类型的任务。通过稀疏激活机制,每次只激活少数几个相关的专家,从而避免任务间的相互干扰,实现更好的多任务学习效果。同时,引入语言条件,使模型能够根据文本指令生成相应的动作。
技术框架:MoE-ACT基于Action Chunking Transformer (ACT)框架,主要包含以下几个模块:1) Transformer编码器:用于提取视觉和语言特征。2) MoE层:集成在Transformer编码器中,将任务策略分解为多个专家。3) 特征线性调制(FiLM):用于动态调制动作tokens,提高动作生成和任务指令之间的一致性。4) 多尺度交叉注意力:用于同时关注低级和高级语义特征。
关键创新:MoE-ACT的关键创新在于将稀疏MoE模块集成到Transformer编码器中,实现任务策略的解耦。与传统的密集模型相比,MoE模型具有更高的容量和更好的泛化能力。此外,通过FiLM和多尺度交叉注意力,进一步提高了动作生成的质量和鲁棒性。
关键设计:MoE层采用稀疏门控机制,每次只激活Top-K个专家。损失函数包括模仿学习损失和辅助损失,用于鼓励专家之间的差异性和稀疏性。语言条件通过将文本嵌入与视觉特征融合来实现。具体参数设置(如Transformer层数、MoE专家数量、注意力头数等)根据实验进行调整。
🖼️ 关键图片

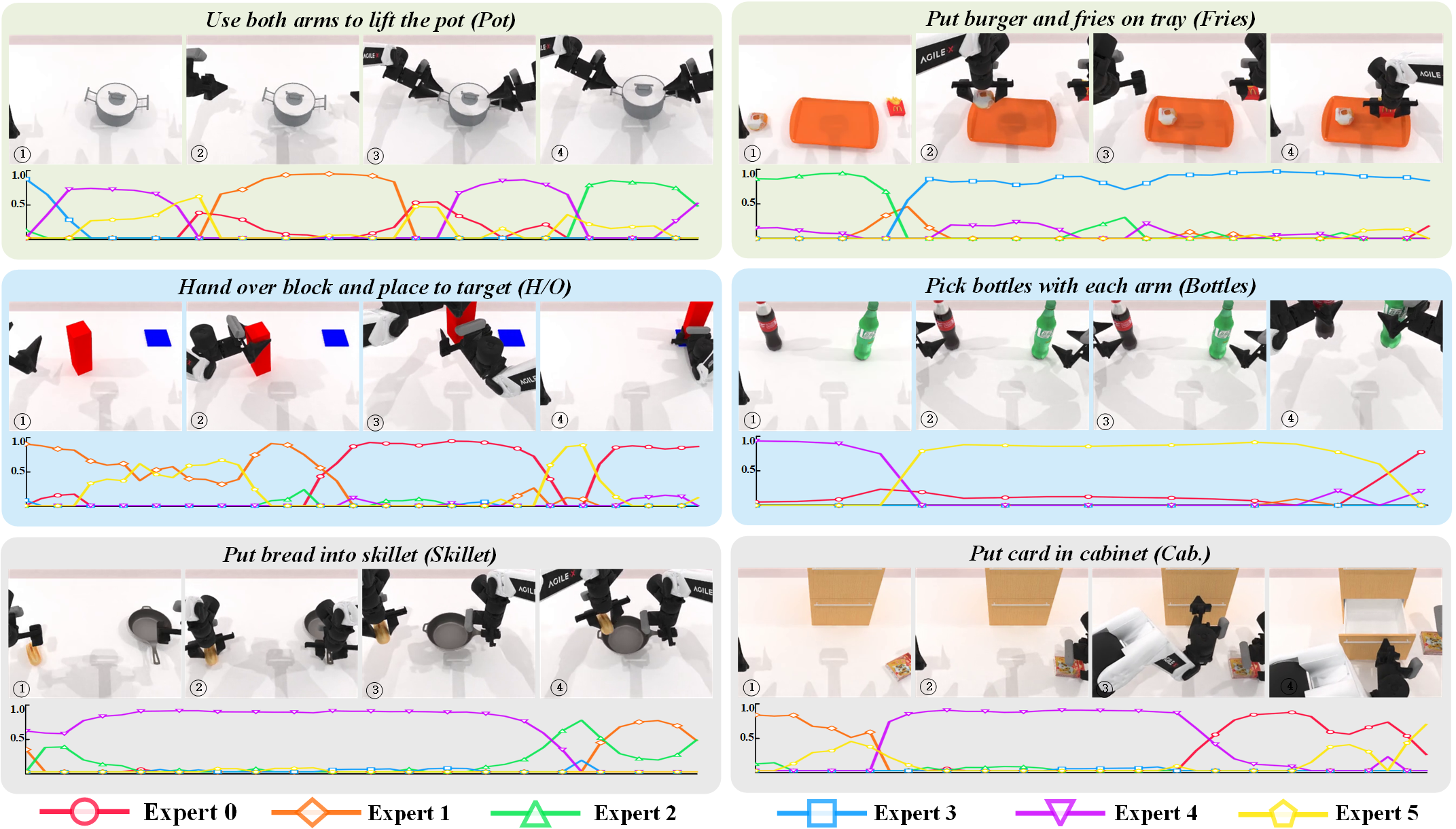

📊 实验亮点
MoE-ACT在模拟和真实世界的双臂操作任务中取得了显著的性能提升。在多任务环境中,MoE-ACT的成功率比vanilla ACT平均提高了33%。实验结果表明,MoE-ACT能够有效地解耦任务策略,提高多任务学习的鲁棒性和泛化能力。此外,MoE-ACT在零样本泛化方面也表现出一定的优势。
🎯 应用场景
MoE-ACT在家庭服务机器人、工业自动化等领域具有广泛的应用前景。例如,可以用于训练机器人完成各种家务任务,如清洁、烹饪、整理等。在工业领域,可以用于训练机器人完成装配、搬运、检测等任务。该研究有助于提高机器人的通用性和智能化水平,使其能够更好地适应复杂多变的环境。
📄 摘要(原文)
The ability of robots to handle multiple tasks under a unified policy is critical for deploying embodied intelligence in real-world household and industrial applications. However, out-of-distribution variation across tasks often causes severe task interference and negative transfer when training general robotic policies. To address this challenge, we propose a lightweight multi-task imitation learning framework for bimanual manipulation, termed Mixture-of-Experts-Enhanced Action Chunking Transformer (MoE-ACT), which integrates sparse Mixture-of-Experts (MoE) modules into the Transformer encoder of ACT. The MoE layer decomposes a unified task policy into independently invoked expert components. Through adaptive activation, it naturally decouples multi-task action distributions in latent space. During decoding, Feature-wise Linear Modulation (FiLM) dynamically modulates action tokens to improve consistency between action generation and task instructions. In parallel, multi-scale cross-attention enables the policy to simultaneously focus on both low-level and high-level semantic features, providing rich visual information for robotic manipulation. We further incorporate textual information, transitioning the framework from a purely vision-based model to a vision-centric, language-conditioned action generation system. Experimental validation in both simulation and a real-world dual-arm setup shows that MoE-ACT substantially improves multi-task performance. Specifically, MoE-ACT outperforms vanilla ACT by an average of 33% in success rate. These results indicate that MoE-ACT provides stronger robustness and generalization in complex multi-task bimanual manipulation environments. Our open-source project page can be found at https://j3k7.github.io/MoE-ACT/.