Beyond Imitation: Reinforcement Learning Fine-Tuning for Adaptive Diffusion Navigation Policies
作者: Junhe Sheng, Ruofei Bai, Kuan Xu, Ruimeng Liu, Jie Chen, Shenghai Yuan, Wei-Yun Yau, Lihua Xie
分类: cs.RO
发布日期: 2026-03-13
💡 一句话要点
提出基于强化学习微调的自适应扩散导航策略,提升机器人泛化能力。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人导航 扩散模型 强化学习 模仿学习 零样本迁移
📋 核心要点
- 现有基于扩散模型的机器人导航策略受限于离线数据集,在新环境中泛化能力不足,易产生安全问题。
- 利用扩散模型的多轨迹采样特性,结合Group Relative Policy Optimization,无需额外价值网络即可进行强化学习微调。
- 通过冻结视觉编码器和选择性更新策略,保留预训练知识的同时,提升策略对新环境的适应性和安全性。
📝 摘要(中文)
本文提出了一种基于强化学习微调的扩散模型导航策略,旨在解决大规模模仿学习数据集训练的扩散模型在未知环境中泛化能力不足的问题。现有方法受限于离线数据集的覆盖范围,容易因分布偏移导致轨迹误差累积和安全问题。针对扩散模型迭代去噪结构带来的梯度反向传播困难和价值网络训练成本高昂等挑战,本文利用扩散模型的多轨迹采样机制,采用Group Relative Policy Optimization (GRPO) 估计轨迹间的相对优势,无需额外的价值网络。同时,冻结视觉编码器并选择性更新解码器高层和动作头,在保留预训练表征的同时,通过在线环境反馈增强安全意识行为。在Isaac Sim的PointGoal任务中,该方法在未知场景中的成功率从52.0%提升至58.7%,SPL从0.49提升至0.54,并降低了碰撞频率。实验表明,微调后的策略能够零样本迁移到真实的四足机器人平台,并在几何分布外环境中保持稳定性能,表明其具有更好的适应性和安全泛化能力。
🔬 方法详解
问题定义:论文旨在解决基于扩散模型的机器人导航策略在未知环境中泛化能力差的问题。现有方法依赖大规模离线数据集进行模仿学习,但当部署到未见过的环境中时,由于分布偏移,容易出现轨迹误差累积,甚至导致安全事故。此外,直接对扩散模型进行强化学习微调面临梯度反向传播困难和训练额外价值网络成本高昂的问题。
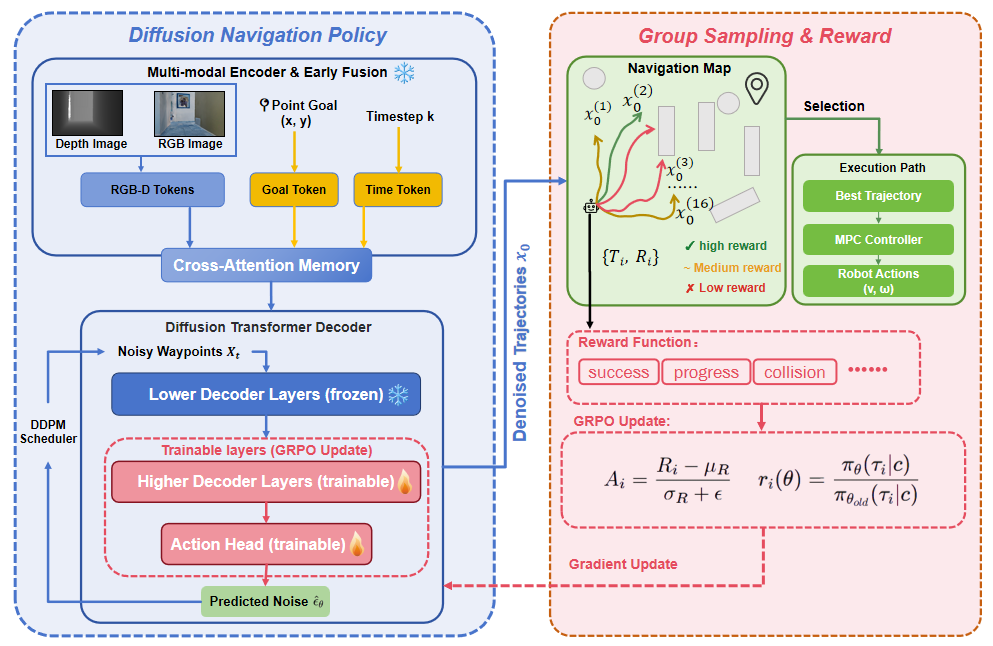
核心思路:论文的核心思路是利用强化学习对预训练的扩散模型导航策略进行微调,使其能够适应新的环境并提高安全性。为了解决梯度反向传播和价值网络训练的难题,论文利用扩散模型本身的多轨迹采样能力,并采用Group Relative Policy Optimization (GRPO) 算法,通过比较不同轨迹的相对优势来指导策略更新,避免了对独立价值网络的依赖。
技术框架:整体框架包含预训练的扩散模型导航策略和强化学习微调模块。预训练的扩散模型基于视觉输入生成多条候选轨迹。强化学习微调模块使用GRPO算法,根据环境反馈(奖励信号)评估这些轨迹的相对优劣,并更新策略参数。为了保持预训练模型的泛化能力,论文冻结了视觉编码器,只对解码器的高层和动作头进行微调。
关键创新:论文的关键创新在于将Group Relative Policy Optimization (GRPO) 算法应用于扩散模型的强化学习微调。GRPO算法能够直接利用扩散模型生成的多条轨迹进行策略优化,无需额外的价值网络,从而降低了计算成本和训练难度。此外,选择性参数更新策略(冻结视觉编码器,微调解码器高层和动作头)能够在保留预训练知识的同时,提高策略对新环境的适应性。
关键设计:论文的关键设计包括:1) 使用扩散模型生成多条候选轨迹;2) 采用Group Relative Policy Optimization (GRPO) 算法进行策略优化,GRPO算法通过计算不同轨迹的相对优势来更新策略,避免了对独立价值网络的依赖;3) 冻结视觉编码器,只对解码器的高层和动作头进行微调,以保留预训练模型的泛化能力;4) 使用奖励函数来鼓励安全行为,例如避免碰撞。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在Isaac Sim的PointGoal任务中,在未知场景中的成功率从52.0%提升至58.7%,SPL从0.49提升至0.54,并降低了碰撞频率。更重要的是,微调后的策略能够零样本迁移到真实的四足机器人平台,并在几何分布外环境中保持稳定性能,验证了该方法的有效性和泛化能力。
🎯 应用场景
该研究成果可应用于各种机器人导航场景,例如家庭服务机器人、自动驾驶汽车、无人机等。通过强化学习微调,可以使机器人在复杂、动态和未知的环境中更安全、更有效地完成导航任务。此外,该方法还可以推广到其他基于扩散模型的机器人控制任务中,例如操作和抓取。
📄 摘要(原文)
Diffusion-based robot navigation policies trained on large-scale imitation learning datasets, can generate multi-modal trajectories directly from the robot's visual observations, bypassing the traditional localization-mapping-planning pipeline and achieving strong zero-shot generalization. However, their performance remains constrained by the coverage of offline datasets, and when deployed in unseen settings, distribution shift often leads to accumulated trajectory errors and safety-critical failures. Adapting diffusion policies with reinforcement learning is challenging because their iterative denoising structure hinders effective gradient backpropagation, while also making the training of an additional value network computationally expensive and less stable. To address these issues, we propose a reinforcement learning fine-tuning framework tailored for diffusion-based navigation. The method leverages the inherent multi-trajectory sampling mechanism of diffusion models and adopts Group Relative Policy Optimization (GRPO), which estimates relative advantages across sampled trajectories without requiring a separate value network. To preserve pretrained representations while enabling adaptation, we freeze the visual encoder and selectively update the higher decoder layers and action head, enhancing safety-aware behaviors through online environmental feedback. On the PointGoal task in Isaac Sim, our approach improves the Success Rate from 52.0% to 58.7% and SPL from 0.49 to 0.54 on unseen scenes, while reducing collision frequency. Additional experiments show that the fine-tuned policy transfers zero-shot to a real quadruped platform and maintains stable performance in geometrically out-of-distribution environments, suggesting improved adaptability and safe generalization to new domains.