AffordGrasp: Cross-Modal Diffusion for Affordance-Aware Grasp Synthesis
作者: Xiaofei Wu, Yi Zhang, Yumeng Liu, Yuexin Ma, Yujiao Shi, Xuming He
分类: cs.RO, cs.CV
发布日期: 2026-03-09
💡 一句话要点
AffordGrasp:提出基于跨模态扩散的抓取姿态合成方法,提升语义感知能力。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱五:交互与反应 (Interaction & Reaction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 抓取姿态合成 扩散模型 可供性感知 人机交互 具身智能
📋 核心要点
- 现有语义抓取方法难以弥合3D对象表示和文本指令之间的巨大模态差距,缺乏显式的空间或语义约束,导致抓取姿态在物理上无效或语义上不一致。
- AffordGrasp利用扩散模型,结合对象几何形状、空间可供性和指令语义,生成物理稳定且语义准确的人手抓取姿态,提升抓取的语义感知能力。
- 在多个数据集上的实验结果表明,AffordGrasp在抓取质量、语义准确性和多样性方面均优于现有技术水平。
📝 摘要(中文)
本文提出AffordGrasp,一个基于扩散模型的框架,旨在生成物理稳定且语义准确的人手抓取姿态。该方法通过结合对象几何形状、空间可供性和指令语义,实现高精度的抓取合成。首先,引入了一种可扩展的标注流程,自动利用细粒度的结构化语言标签丰富手-物交互数据集,捕捉交互意图。其次,AffordGrasp集成了手部姿态的可供性感知潜在表示与双重条件扩散过程,使模型能够联合推理对象几何、空间可供性和指令语义。此外,分布调整模块进一步加强了物理接触一致性和语义对齐。在HO-3D、OakInk、GRAB和AffordPose四个指令增强基准数据集上的评估表明,AffordGrasp在抓取质量、语义准确性和多样性方面均显著优于现有方法。
🔬 方法详解
问题定义:现有方法在生成人手抓取姿态时,难以同时兼顾对象几何形状、用户指定的交互语义以及物理上的可行性。模态差距大,缺乏有效的空间和语义约束,导致生成的抓取姿态可能不自然,甚至无法实现。
核心思路:AffordGrasp的核心思路是利用扩散模型,通过双重条件作用(对象几何形状和文本指令),逐步生成符合要求的抓取姿态。同时,引入可供性感知的潜在表示,显式地建模手部姿态与对象之间的交互关系,从而提升抓取的语义一致性和物理可行性。
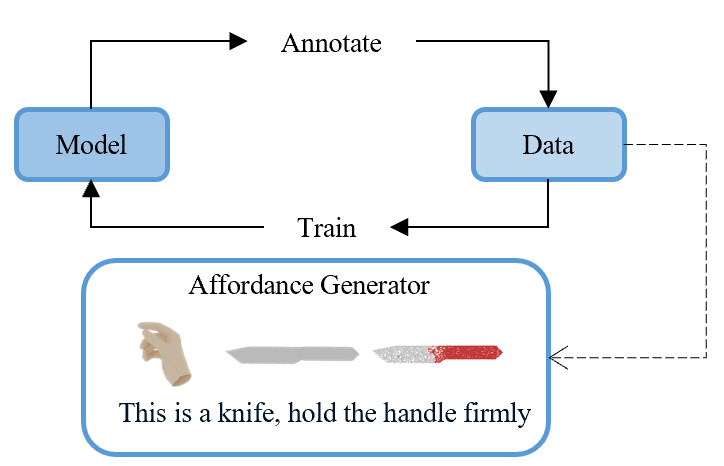
技术框架:AffordGrasp框架主要包含以下几个模块:1) 数据增强模块,通过自动标注流程,为手-物交互数据集添加细粒度的结构化语言标签。2) 可供性感知的潜在表示模块,用于编码手部姿态与对象之间的交互关系。3) 双重条件扩散模型,以对象几何形状和文本指令为条件,生成抓取姿态。4) 分布调整模块,用于增强物理接触一致性和语义对齐。
关键创新:AffordGrasp的关键创新在于:1) 提出了一个可扩展的自动标注流程,能够有效地生成细粒度的结构化语言标签,用于描述手-物交互意图。2) 将可供性感知的潜在表示融入到扩散模型中,使得模型能够更好地理解手部姿态与对象之间的交互关系。3) 提出了分布调整模块,进一步提升了抓取姿态的物理可行性和语义一致性。
关键设计:在扩散模型中,采用了双重条件作用机制,分别以对象几何形状和文本指令作为条件。损失函数包括扩散模型的标准损失函数,以及用于增强物理接触一致性和语义对齐的损失函数。具体网络结构细节未知,但推测使用了Transformer或类似结构来处理文本指令,并使用卷积神经网络或图神经网络来处理3D对象几何形状。
🖼️ 关键图片


📊 实验亮点
AffordGrasp在HO-3D、OakInk、GRAB和AffordPose四个数据集上进行了评估,实验结果表明,AffordGrasp在抓取质量、语义准确性和多样性方面均显著优于现有方法。具体的性能提升数据未知,但摘要中强调了“substantial improvements”,表明提升幅度较大。该方法能够生成更符合人类意图且物理上可行的抓取姿态。
🎯 应用场景
AffordGrasp在增强现实(AR)、虚拟现实(VR)和具身智能(Embodied AI)等领域具有广泛的应用前景。它可以用于生成更自然、更智能的人机交互界面,例如,在VR游戏中,用户可以通过自然语言指令控制虚拟角色的手部动作,实现更逼真的交互体验。此外,该技术还可以应用于机器人操作领域,帮助机器人更好地理解人类的意图,完成复杂的抓取任务。
📄 摘要(原文)
Generating human grasping poses that accurately reflect both object geometry and user-specified interaction semantics is essential for natural hand-object interactions in AR/VR and embodied AI. However, existing semantic grasping approaches struggle with the large modality gap between 3D object representations and textual instructions, and often lack explicit spatial or semantic constraints, leading to physically invalid or semantically inconsistent grasps. In this work, we present AffordGrasp, a diffusion-based framework that produces physically stable and semantically faithful human grasps with high precision. We first introduce a scalable annotation pipeline that automatically enriches hand-object interaction datasets with fine-grained structured language labels capturing interaction intent. Building upon these annotations, AffordGrasp integrates an affordance-aware latent representation of hand poses with a dual-conditioning diffusion process, enabling the model to jointly reason over object geometry, spatial affordances, and instruction semantics. A distribution adjustment module further enforces physical contact consistency and semantic alignment. We evaluate AffordGrasp across four instruction-augmented benchmarks derived from HO-3D, OakInk, GRAB, and AffordPose, and observe substantial improvements over state-of-the-art methods in grasp quality, semantic accuracy, and diversity.