Spatially anchored Tactile Awareness for Robust Dexterous Manipulation
作者: Jialei Huang, Yang Ye, Yuanqing Gong, Xuezhou Zhu, Yang Gao, Kaifeng Zhang
分类: cs.RO
发布日期: 2026-02-28
💡 一句话要点
提出SaTA框架,通过空间锚定的触觉感知实现鲁棒的灵巧操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱七:动作重定向 (Motion Retargeting)
关键词: 灵巧操作 触觉感知 空间锚定 机器人学习 几何推理
📋 核心要点
- 现有视觉-触觉学习方法在亚毫米级精度任务中表现不足,无法有效利用触觉信号的空间关系。
- SaTA框架通过正向运动学将触觉特征锚定到手部运动学框架,实现精确几何推理,无需物体模型或姿态估计。
- 在USB-C插拔、灯泡安装和卡片滑动等任务中,SaTA显著优于基线方法,成功率提升高达30%。
📝 摘要(中文)
灵巧操作需要精确的几何推理,但现有的视觉-触觉学习方法难以胜任传统基于模型方法能够轻松处理的亚毫米级精度任务。我们发现一个关键限制:虽然触觉传感器提供了丰富的接触信息,但当前的学习框架未能有效利用触觉信号的感知丰富性及其与手部运动学的空间关系。我们认为,理想的触觉表示应该在稳定的参考系中明确地锚定接触测量,同时保留详细的感知信息,使策略不仅能够检测接触的发生,还能在手部坐标系中精确地推断物体几何形状。我们引入SaTA(用于灵巧操作的空间锚定触觉感知),这是一个端到端策略框架,通过正向运动学将触觉特征明确地锚定到手部的运动学框架中,从而在不需要物体模型或显式姿态估计的情况下实现精确的几何推理。我们的关键见解是,空间接地的触觉表示允许策略不仅检测接触的发生,还能精确地推断手部坐标系中的物体几何形状。我们在具有挑战性的灵巧操作任务上验证了SaTA,包括自由空间中的双手USB-C插拔(需要亚毫米级的对准精度)、需要精确螺纹啮合和旋转控制的灯泡安装,以及需要精细的力调节和角度精度的卡片滑动。由于其严格的精度要求,这些任务对基于学习的方法提出了重大挑战。在多个基准测试中,SaTA显著优于强大的视觉-触觉基线,成功率提高了30%,同时任务完成时间减少了27%。
🔬 方法详解
问题定义:现有基于视觉-触觉的灵巧操作方法难以达到亚毫米级别的精度,无法满足一些高精度操作任务的需求。这些方法通常难以有效利用触觉传感器提供的丰富空间信息,以及触觉信息与手部运动学之间的关系。现有方法要么依赖于复杂的物体模型,要么需要进行精确的姿态估计,限制了其泛化能力和鲁棒性。
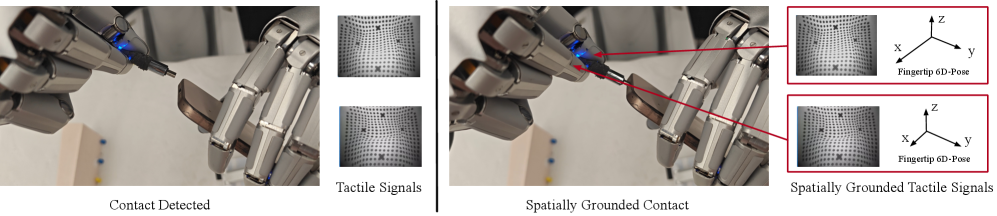
核心思路:SaTA的核心思路是将触觉特征与手部的运动学框架进行空间锚定。通过正向运动学,将触觉传感器的测量结果转换到手部的坐标系中,从而建立触觉信息与手部姿态之间的明确对应关系。这种空间锚定的触觉表示能够让策略更精确地推断物体几何形状,并进行更精细的运动控制。
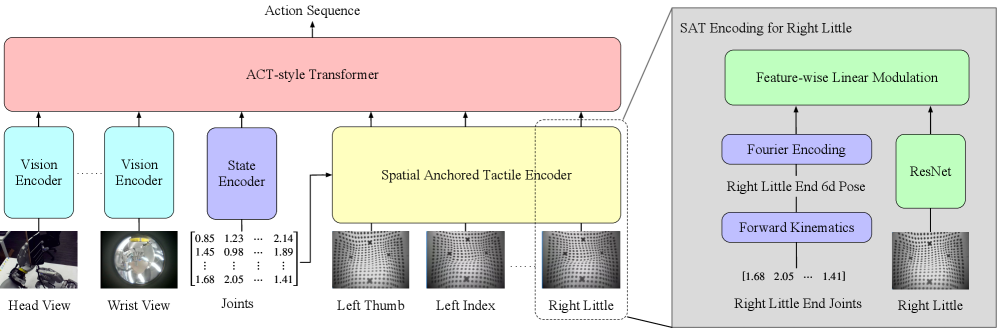
技术框架:SaTA是一个端到端的策略学习框架。它主要包含以下几个模块:1) 触觉数据采集模块:负责从触觉传感器获取原始数据。2) 空间锚定模块:利用手部的运动学信息,将触觉数据转换到手部坐标系中。3) 策略学习模块:使用深度神经网络学习从空间锚定的触觉特征到动作的映射关系。整个框架通过端到端的方式进行训练,无需人工设计特征或进行中间步骤的优化。
关键创新:SaTA最重要的创新点在于其空间锚定的触觉表示方法。与以往的方法不同,SaTA明确地将触觉信息与手部的运动学信息联系起来,从而能够更有效地利用触觉传感器的空间信息。这种空间锚定的表示方法使得策略能够更精确地推断物体几何形状,并进行更精细的运动控制,而无需依赖于物体模型或姿态估计。
关键设计:SaTA使用深度神经网络作为策略学习器。网络的输入是空间锚定的触觉特征,输出是手部的动作指令。损失函数通常采用强化学习中的策略梯度方法,例如PPO或SAC。为了提高训练的稳定性和效率,可以使用一些技巧,例如经验回放、目标网络等。具体的网络结构和超参数需要根据具体的任务进行调整。
🖼️ 关键图片

📊 实验亮点
SaTA在多个具有挑战性的灵巧操作任务上进行了验证,包括USB-C插拔、灯泡安装和卡片滑动。实验结果表明,SaTA显著优于现有的视觉-触觉基线方法,成功率提高了高达30%,任务完成时间减少了27%。这些结果表明,SaTA能够有效地利用触觉传感器的空间信息,实现高精度和鲁棒性的灵巧操作。
🎯 应用场景
SaTA框架在需要高精度和鲁棒性的灵巧操作任务中具有广泛的应用前景,例如精密装配、医疗手术、以及在未知或复杂环境下的机器人操作。该技术可以应用于自动化生产线,提高生产效率和产品质量。在医疗领域,可以辅助医生进行微创手术,提高手术精度和安全性。在服务机器人领域,可以使机器人更好地适应复杂环境,完成各种任务。
📄 摘要(原文)
Dexterous manipulation requires precise geometric reasoning, yet existing visuo-tactile learning methods struggle with sub-millimeter precision tasks that are routine for traditional model-based approaches. We identify a key limitation: while tactile sensors provide rich contact information, current learning frameworks fail to effectively leverage both the perceptual richness of tactile signals and their spatial relationship with hand kinematics. We believe an ideal tactile representation should explicitly ground contact measurements in a stable reference frame while preserving detailed sensory information, enabling policies to not only detect contact occurrence but also precisely infer object geometry in the hand's coordinate system. We introduce SaTA (Spatially-anchored Tactile Awareness for dexterous manipulation), an end-to-end policy framework that explicitly anchors tactile features to the hand's kinematic frame through forward kinematics, enabling accurate geometric reasoning without requiring object models or explicit pose estimation. Our key insight is that spatially grounded tactile representations allow policies to not only detect contact occurrence but also precisely infer object geometry in the hand's coordinate system. We validate SaTA on challenging dexterous manipulation tasks, including bimanual USB-C mating in free space, a task demanding sub-millimeter alignment precision, as well as light bulb installation requiring precise thread engagement and rotational control, and card sliding that demands delicate force modulation and angular precision. These tasks represent significant challenges for learning-based methods due to their stringent precision requirements. Across multiple benchmarks, SaTA significantly outperforms strong visuo-tactile baselines, improving success rates by up to 30 percentage while reducing task completion times by 27 percentage.