Learning Robust Control Policies for Inverted Pose on Miniature Blimp Robots
作者: Yuanlin Yang, Lin Hong, Fumin Zhang
分类: cs.RO
发布日期: 2026-02-27
💡 一句话要点
提出一种鲁棒控制策略学习框架,用于微型飞艇机器人在倒立姿态下的稳定控制。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 微型飞艇机器人 倒立控制 强化学习 领域随机化 TD3算法 Sim-to-Real 鲁棒控制
📋 核心要点
- 微型飞艇机器人倒立姿态控制因其复杂动力学和欠驱动特性而极具挑战,现有方法难以保证鲁棒性。
- 论文提出基于强化学习的控制策略,通过高保真仿真、领域随机化和改进TD3算法提升策略的鲁棒性。
- 实验结果表明,该方法在仿真和真实环境中均能有效实现微型飞艇机器人的倒立姿态控制,优于传统方法。
📝 摘要(中文)
本文提出了一种新颖的框架,用于实现微型飞艇机器人(MBRs)在倒立姿态下的鲁棒控制策略学习。由于MBRs的复杂性和欠驱动特性,开发可靠的控制方法极具挑战。该框架包含三个核心阶段:首先,构建一个高保真三维(3D)仿真环境,并根据真实MBR的运动数据进行校准,以确保准确模拟倒立状态下的动力学。其次,通过领域随机化策略和改进的Twin Delayed Deep Deterministic Policy Gradient(TD3)算法,在仿真环境中训练MBR倒立控制的鲁棒策略。第三,设计一个映射层,以弥合sim-to-real的差距,从而部署学习到的策略。仿真环境中的综合评估表明,与能量整形控制器相比,学习到的策略实现了更高的成功率。实验结果证实,带有映射层的学习策略使MBR能够在真实环境中实现并保持完全倒立的姿态。
🔬 方法详解
问题定义:微型飞艇机器人(MBR)的倒立姿态控制是一个具有挑战性的问题,因为MBR具有复杂的非线性动力学和欠驱动特性。传统的控制方法,例如能量整形控制器,在面对真实环境中的扰动和不确定性时,难以保证控制策略的鲁棒性和稳定性。因此,需要一种能够适应环境变化并实现稳定倒立姿态控制的策略。
核心思路:本文的核心思路是利用强化学习,在高保真仿真环境中训练MBR的控制策略,并通过领域随机化来提高策略的鲁棒性。通过学习,智能体能够自主地探索和学习最优的控制策略,从而克服传统控制方法的局限性。同时,为了解决仿真环境与真实环境之间的差异,设计了一个映射层,将学习到的策略迁移到真实机器人上。
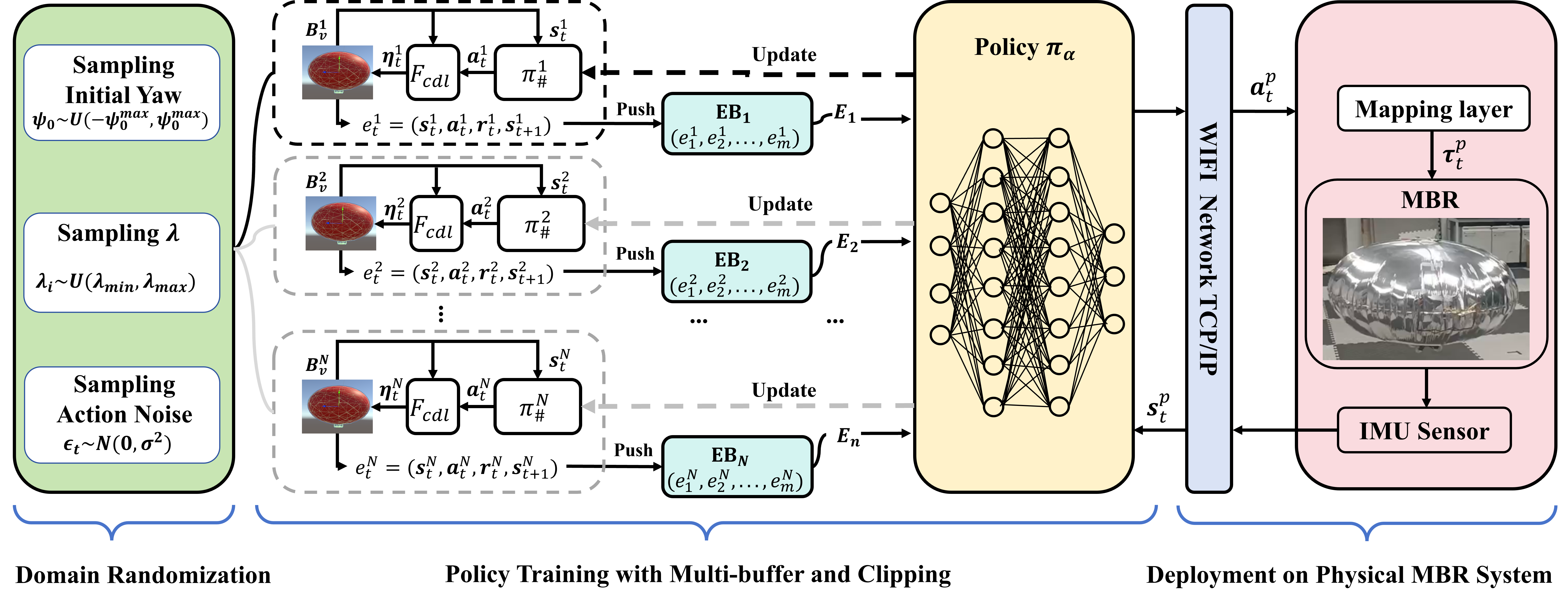
技术框架:该框架主要包含三个阶段:1) 高保真仿真环境构建:构建一个精确的3D仿真环境,并使用真实MBR的运动数据进行校准,以确保仿真环境能够准确地模拟倒立状态下的动力学特性。2) 鲁棒策略训练:在仿真环境中,使用改进的TD3算法训练MBR的倒立控制策略。为了提高策略的鲁棒性,采用了领域随机化策略,即在训练过程中随机改变仿真环境的参数,例如质量、摩擦系数等。3) Sim-to-Real迁移:设计一个映射层,将学习到的策略迁移到真实机器人上。该映射层用于补偿仿真环境与真实环境之间的差异,例如传感器噪声、执行器误差等。
关键创新:该论文的关键创新在于:1) 提出了一种基于强化学习的MBR倒立控制策略学习框架,该框架能够自动地学习最优的控制策略,无需人工设计复杂的控制规则。2) 采用了领域随机化策略,显著提高了策略的鲁棒性,使其能够适应真实环境中的扰动和不确定性。3) 设计了一个映射层,有效地解决了Sim-to-Real迁移问题,使得学习到的策略能够在真实机器人上成功部署。
关键设计:在TD3算法中,作者可能修改了奖励函数,使其更适合倒立控制任务。例如,奖励函数可能包含以下几个部分:1) 姿态奖励:鼓励机器人保持倒立姿态。2) 速度惩罚:惩罚机器人的过大速度。3) 控制力惩罚:惩罚过大的控制力。此外,领域随机化的具体参数范围以及映射层的具体实现方式(例如,使用神经网络进行映射)也是关键的设计细节,但论文摘要中未明确说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
仿真实验表明,所提出的学习策略在倒立控制任务中取得了比能量整形控制器更高的成功率。真实环境实验验证了该策略的有效性,微型飞艇机器人能够成功实现并保持完全倒立的姿态。具体的成功率提升幅度以及与其它基线方法的对比数据,摘要中未给出,属于未知信息。
🎯 应用场景
该研究成果可应用于微型飞艇机器人在复杂环境下的自主导航、空中检测、以及需要倒立姿态才能完成的特殊任务。例如,在狭窄空间内进行管道检测,或在灾难救援中进行倒立姿态下的目标搜索。该技术有望提升微型飞艇机器人的灵活性和适应性,拓展其应用范围。
📄 摘要(原文)
The ability to achieve and maintain inverted poses is essential for unlocking the full agility of miniature blimp robots (MBRs). However, developing reliable control methods for MBRs remains challenging due to their complex and underactuated dynamics. To address this challenge, we propose a novel framework that enables robust control policy learning for inverted pose on MBRs. The proposed framework operates through three core stages: First, a high-fidelity three-dimensional (3D) simulation environment was constructed, which was calibrated against real-world MBR motion data to ensure accurate replication of inverted-state dynamics. Second, a robust policy for MBR inverted control was trained within the simulation environment via a domain randomization strategy and a modified Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm. Third, a mapping layer was designed to bridge the sim-to-real gap for the learned policy deployment. Comprehensive evaluations in the simulation environment demonstrate that the learned policy achieves a higher success rate compared to the energy-shaping controller. Furthermore, experimental results confirm that the learned policy with a mapping layer enables an MBR to achieve and maintain a fully upside-down pose in real-world settings.