Humanizing Robot Gaze Shifts: A Framework for Natural Gaze Shifts in Humanoid Robots
作者: Jingchao Wei, Jingkai Qin, Yuxiao Cao, Jingcheng Huang, Xiangrui Zeng, Min Li, Zhouping Yin
分类: cs.RO
发布日期: 2026-02-25
备注: submitted to AIM 2026
💡 一句话要点
提出RGS框架,实现人机交互中类人机器人的自然视线转移
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人机交互 类人机器人 视线转移 视觉-语言模型 VQ-VAE 注意力机制 运动生成
📋 核心要点
- 现有类人机器人在人机交互中难以进行自然且符合语境的视线转移,主要挑战在于认知注意机制和仿生运动生成的耦合。
- RGS框架的核心思想是将视觉-语言模型用于视线目标推理,并使用条件VQ-VAE生成类人视线转移运动,从而实现自然的视线转移。
- 实验结果表明,RGS框架能够有效模仿人类的视线目标选择,并生成逼真且多样化的视线转移运动。
📝 摘要(中文)
为了使人机交互中类人机器人能够进行自然的视线转移,本文提出了一种名为Robot Gaze-Shift (RGS)的框架。该框架利用听觉和视觉反馈进行注意力重定向,这对于自然的视线转移至关重要。RGS框架将认知注意力机制和仿生运动生成相结合。首先,RGS采用基于视觉-语言模型(VLM)的视线推理流程,从多模态交互线索中推断出符合语境的视线目标,确保与人类的视线引导规律一致。其次,RGS引入了一个条件向量量化变分自编码器(VQ-VAE)模型,用于生成眼睛-头部协调的视线转移运动,从而产生多样化且类人的视线转移行为。实验验证了RGS能够有效地复制类人目标选择,并生成逼真、多样化的视线转移运动。
🔬 方法详解
问题定义:论文旨在解决类人机器人在人机交互中视线转移不自然的问题。现有的方法通常难以将认知注意力机制和仿生运动生成有效结合,导致机器人的视线转移缺乏上下文感知能力,并且运动不够自然流畅。
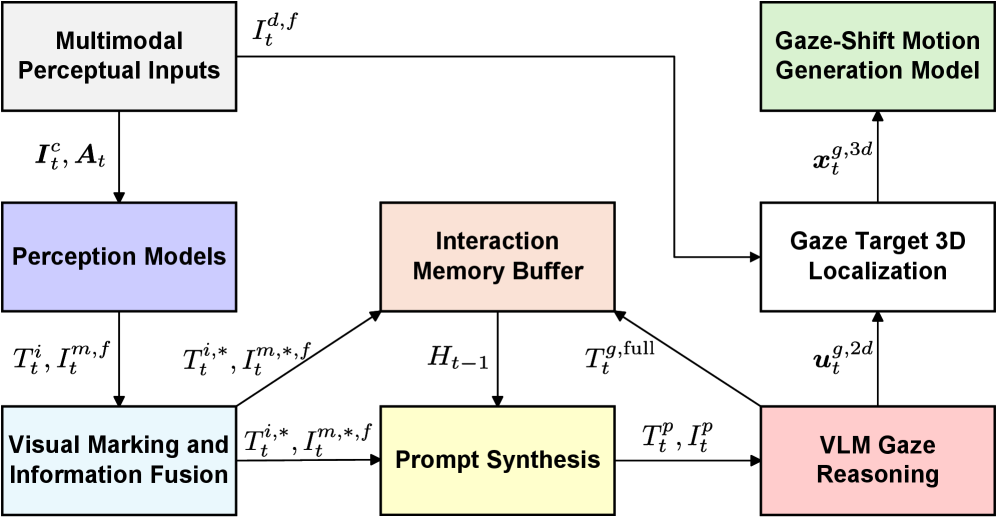
核心思路:论文的核心思路是将视线转移问题分解为两个子问题:视线目标的选择和视线转移运动的生成。通过视觉-语言模型推理出合适的视线目标,然后利用条件VQ-VAE生成类人的视线转移运动。这种解耦的设计使得可以分别优化视线目标选择和运动生成,从而提高整体的自然度和流畅性。
技术框架:RGS框架包含两个主要模块:基于VLM的视线推理模块和基于条件VQ-VAE的视线转移运动生成模块。首先,VLM模块接收多模态输入(视觉和听觉信息),推理出最合适的视线目标。然后,条件VQ-VAE模块根据视线目标生成眼睛和头部协调的运动轨迹。这两个模块构成了一个完整的视线转移pipeline。
关键创新:该论文的关键创新在于将视觉-语言模型应用于视线目标推理,并使用条件VQ-VAE生成类人的视线转移运动。VLM的使用使得机器人能够更好地理解上下文信息,从而选择更合适的视线目标。条件VQ-VAE能够生成多样化的运动轨迹,避免了传统方法中运动过于僵硬的问题。
关键设计:条件VQ-VAE模型的关键设计在于使用向量量化(VQ)来学习离散的运动基元,并使用变分自编码器(VAE)来生成连续的运动轨迹。条件信息(视线目标)被用于指导VAE的生成过程,从而使得生成的运动轨迹能够准确地指向目标。损失函数包括重构损失、KL散度和量化损失,用于保证运动轨迹的质量和多样性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,RGS框架能够有效地复制人类的视线目标选择行为,并且生成的视线转移运动更加自然和多样化。通过主观评价实验,验证了RGS生成的视线转移运动在自然度方面优于其他基线方法。具体而言,用户认为RGS生成的运动更符合人类的习惯,并且更具有吸引力。
🎯 应用场景
该研究成果可应用于各种人机交互场景,例如服务机器人、教育机器人和娱乐机器人。通过使机器人能够进行自然的视线转移,可以提高人机交互的效率和舒适度,增强用户的信任感和亲近感。未来,该技术还可以应用于虚拟现实和增强现实等领域,创造更加沉浸式的用户体验。
📄 摘要(原文)
Leveraging auditory and visual feedback for attention reorientation is essential for natural gaze shifts in social interaction. However, enabling humanoid robots to perform natural and context-appropriate gaze shifts in unconstrained human--robot interaction (HRI) remains challenging, as it requires the coupling of cognitive attention mechanisms and biomimetic motion generation. In this work, we propose the Robot Gaze-Shift (RGS) framework, which integrates these two components into a unified pipeline. First, RGS employs a vision--language model (VLM)-based gaze reasoning pipeline to infer context-appropriate gaze targets from multimodal interaction cues, ensuring consistency with human gaze-orienting regularities. Second, RGS introduces a conditional Vector Quantized-Variational Autoencoder (VQ-VAE) model for eye--head coordinated gaze-shift motion generation, producing diverse and human-like gaze-shift behaviors. Experiments validate that RGS effectively replicates human-like target selection and generates realistic, diverse gaze-shift motions.