Self-Correcting VLA: Online Action Refinement via Sparse World Imagination
作者: Chenyv Liu, Wentao Tan, Lei Zhu, Fengling Li, Jingjing Li, Guoli Yang, Heng Tao Shen
分类: cs.RO, cs.AI, cs.CV
发布日期: 2026-02-25
🔗 代码/项目: GITHUB
💡 一句话要点
提出自校正VLA模型,通过稀疏世界想象实现机器人动作在线优化。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作 机器人操作 世界模型 强化学习 稀疏想象 在线优化 动作细化
📋 核心要点
- 传统VLA模型依赖数据先验,缺乏对物理动态的鲁棒理解,而强化学习依赖外部奖励,与智能体内部状态隔离。
- SC-VLA通过稀疏世界想象引导动作优化,利用辅助预测头预测任务进度和轨迹,约束策略编码短期物理演化。
- 实验表明,SC-VLA在机器人操作任务中表现出色,任务吞吐量更高,步数更少,成功率也优于现有方法。
📝 摘要(中文)
标准的视觉-语言-动作(VLA)模型依赖于拟合统计数据先验,限制了其对底层物理动态的鲁棒理解。强化学习通过探索增强了物理基础,但通常依赖于与智能体内部状态隔离的外部奖励信号。世界动作模型已成为一种有前途的范例,它集成了想象和控制以实现预测性规划。然而,它们依赖于隐式上下文建模,缺乏用于自我改进的显式机制。为了解决这些问题,我们提出了自校正VLA(SC-VLA),它通过内在引导动作细化来实现自我改进,通过稀疏想象。我们首先通过集成辅助预测头来预测当前任务进度和未来轨迹趋势,从而设计稀疏世界想象,从而约束策略以编码短期物理演化。然后,我们引入在线动作细化模块来重塑依赖于进度的密集奖励,基于预测的稀疏未来状态调整轨迹方向。在模拟基准和真实世界环境中具有挑战性的机器人操作任务的评估表明,SC-VLA实现了最先进的性能,以最高的任务吞吐量、减少16%的步骤和比最佳基线高9%的成功率,以及在真实世界实验中获得14%的收益。代码可在https://github.com/Kisaragi0/SC-VLA获得。
🔬 方法详解
问题定义:现有VLA模型在理解物理动态方面存在局限性,主要原因是它们依赖于统计数据先验,缺乏对环境物理规律的有效建模。强化学习方法虽然可以通过探索来增强物理基础,但通常依赖于外部奖励信号,这些信号与智能体的内部状态隔离,导致学习效率低下。世界动作模型虽然集成了想象和控制,但缺乏显式的自我改进机制。
核心思路:SC-VLA的核心思路是通过稀疏世界想象来引导动作的在线优化。具体来说,模型通过预测任务进度和未来轨迹趋势,来约束策略的学习,使其能够更好地编码短期的物理演化过程。通过这种方式,模型可以更加准确地预测动作的后果,并根据预测结果来调整动作,从而实现自我改进。
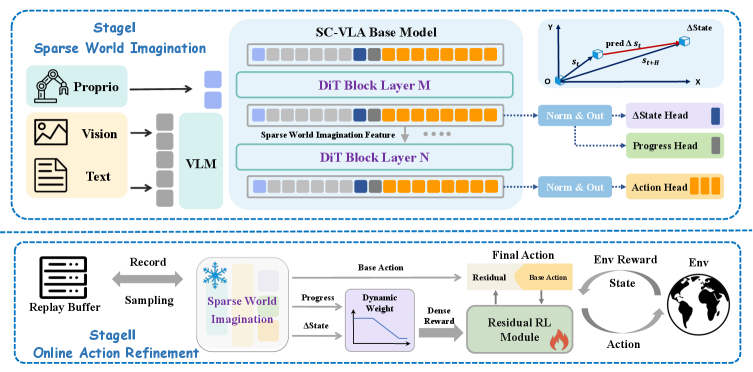
技术框架:SC-VLA的整体框架包含两个主要模块:稀疏世界想象模块和在线动作细化模块。稀疏世界想象模块通过集成辅助预测头来预测当前任务的进度和未来轨迹的趋势。在线动作细化模块则根据稀疏世界想象模块的预测结果,重塑依赖于进度的密集奖励,并基于预测的未来状态调整轨迹的方向。整个框架通过迭代的方式,不断优化动作策略,从而提高任务的完成效率和成功率。
关键创新:SC-VLA最重要的技术创新点在于其稀疏世界想象机制。与传统的密集预测方法不同,SC-VLA只预测任务的关键状态和未来轨迹的趋势,从而降低了计算复杂度,并提高了预测的准确性。此外,SC-VLA还引入了在线动作细化模块,该模块可以根据预测结果动态调整动作策略,从而实现自我改进。
关键设计:在稀疏世界想象模块中,论文设计了辅助预测头来预测任务进度和未来轨迹趋势。这些预测头可以是简单的线性层或更复杂的神经网络。在线动作细化模块则使用预测结果来重塑奖励函数,并使用强化学习算法(如PPO)来优化动作策略。具体的损失函数包括预测损失和强化学习损失。网络结构的选择取决于具体的任务,可以使用卷积神经网络(CNN)来处理图像输入,使用循环神经网络(RNN)来处理序列数据。
🖼️ 关键图片


📊 实验亮点
SC-VLA在模拟和真实世界的机器人操作任务中均取得了显著的性能提升。在模拟环境中,SC-VLA以最高的任务吞吐量、减少16%的步数和比最佳基线高9%的成功率实现了最先进的性能。在真实世界实验中,SC-VLA也获得了14%的性能提升,验证了其在实际应用中的有效性。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,例如物体抓取、装配、导航等。通过提高机器人对物理环境的理解和预测能力,可以显著提升机器人的自主性和适应性,使其能够更好地完成复杂任务。该技术在智能制造、物流、医疗等领域具有广阔的应用前景。
📄 摘要(原文)
Standard vision-language-action (VLA) models rely on fitting statistical data priors, limiting their robust understanding of underlying physical dynamics. Reinforcement learning enhances physical grounding through exploration yet typically relies on external reward signals that remain isolated from the agent's internal states. World action models have emerged as a promising paradigm that integrates imagination and control to enable predictive planning. However, they rely on implicit context modeling, lacking explicit mechanisms for self-improvement. To solve these problems, we propose Self-Correcting VLA (SC-VLA), which achieve self-improvement by intrinsically guiding action refinement through sparse imagination. We first design sparse world imagination by integrating auxiliary predictive heads to forecast current task progress and future trajectory trends, thereby constraining the policy to encode short-term physical evolution. Then we introduce the online action refinement module to reshape progress-dependent dense rewards, adjusting trajectory orientation based on the predicted sparse future states. Evaluations on challenging robot manipulation tasks from simulation benchmarks and real-world settings demonstrate that SC-VLA achieve state-of-the-art performance, yielding the highest task throughput with 16% fewer steps and a 9% higher success rate than the best-performing baselines, alongside a 14% gain in real-world experiments. Code is available at https://github.com/Kisaragi0/SC-VLA.