Squint: Fast Visual Reinforcement Learning for Sim-to-Real Robotics
作者: Abdulaziz Almuzairee, Henrik I. Christensen
分类: cs.RO, cs.CV, cs.LG
发布日期: 2026-02-24
备注: For website and code, see https://aalmuzairee.github.io/squint
💡 一句话要点
Squint:面向Sim-to-Real机器人的快速视觉强化学习方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉强化学习 机器人控制 Sim-to-Real 软演员-评论家 并行模拟
📋 核心要点
- 视觉强化学习在机器人控制中面临高维图像带来的训练复杂性和存储开销问题,导致训练速度慢。
- Squint通过并行模拟、分布式评论家等技术加速视觉强化学习,旨在实现比现有方法更快的实际训练时间。
- 在SO-101任务集上,Squint仅用15分钟在单个GPU上完成训练,并在Sim-to-Real迁移中表现出良好的性能。
📝 摘要(中文)
视觉强化学习在机器人领域具有吸引力,但成本高昂。离线强化学习方法样本效率高但速度慢;在线强化学习方法并行性好但浪费样本。最近的研究表明,对于基于状态的控制,离线方法在实际运行时间上比在线方法训练更快。然而,将其扩展到视觉领域仍然具有挑战性,因为高维输入图像使训练动态复杂化,并引入了大量的存储和编码开销。为了解决这些挑战,我们提出了一种视觉软演员-评论家方法Squint,它比之前的视觉离线和在线方法实现了更快的实际训练时间。Squint通过并行模拟、分布式评论家、分辨率调整、层归一化、调整后的更新数据比率和优化的实现来实现这一点。我们在SO-101任务集(ManiSkill3中包含大量领域随机化的八个操作任务的新套件)上进行了评估,并展示了到真实SO-101机器人的Sim-to-Real迁移。我们在一块RTX 3090 GPU上训练策略15分钟,大多数任务在6分钟内收敛。
🔬 方法详解
问题定义:论文旨在解决视觉强化学习在机器人控制中训练速度慢的问题。现有的离线强化学习方法虽然样本效率高,但训练速度慢;在线强化学习方法虽然可以并行化,但样本利用率低。此外,高维图像输入增加了训练的复杂性和存储开销,使得视觉强化学习的训练更加耗时。
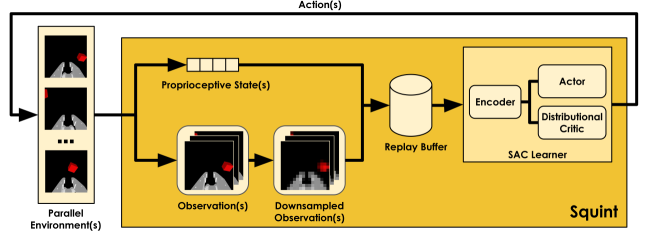
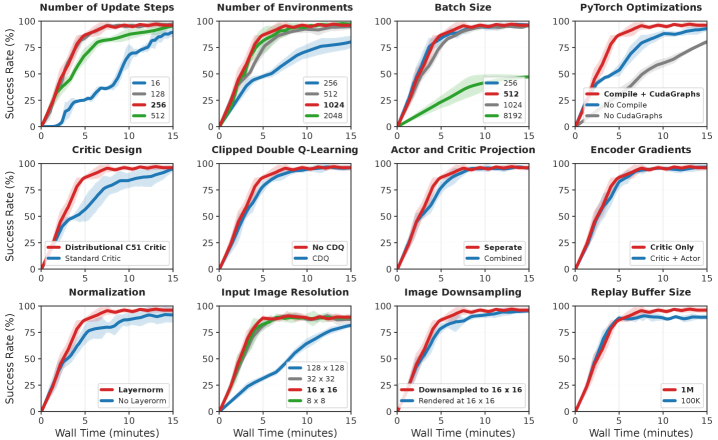
核心思路:论文的核心思路是通过一系列优化策略来加速视觉强化学习的训练过程,使其在实际运行时间上优于现有的在线和离线方法。这些策略包括并行模拟、分布式评论家、分辨率调整、层归一化、调整后的更新数据比率和优化的实现。通过这些策略,Squint能够更有效地利用数据,减少计算开销,从而加速训练。
技术框架:Squint基于Soft Actor-Critic (SAC) 算法,并针对视觉输入进行了优化。整体框架包括以下几个主要模块:1) 并行模拟环境:通过并行运行多个模拟环境来加速数据收集。2) 分布式评论家:使用多个评论家来估计状态-动作值的分布,从而提高训练的稳定性。3) 演员网络和评论家网络:使用深度神经网络来表示策略和值函数。4) 优化器:使用Adam优化器来更新网络参数。
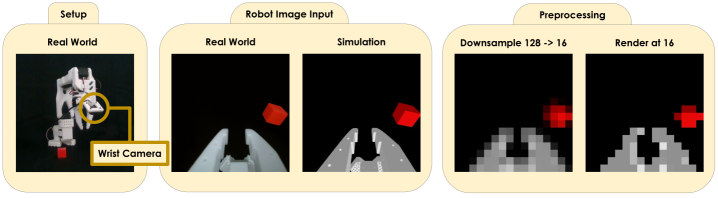
关键创新:Squint的关键创新在于其综合运用多种优化策略来加速视觉强化学习的训练。这些策略包括:1) 分辨率调整(Resolution Squinting):通过降低输入图像的分辨率来减少计算开销。2) 调整更新数据比率:优化更新策略的频率,以平衡样本效率和训练速度。3) 优化的实现:通过代码优化来减少计算时间。与现有方法的本质区别在于,Squint更加注重实际运行时间,并针对视觉输入进行了专门的优化。
关键设计:Squint的关键设计包括:1) 使用层归一化来提高训练的稳定性。2) 调整更新数据比率,以平衡样本效率和训练速度。3) 使用Adam优化器,并调整学习率等超参数。4) 针对不同的任务,调整输入图像的分辨率,以平衡计算开销和性能。
🖼️ 关键图片
📊 实验亮点
Squint在SO-101任务集上取得了显著的成果。在单个RTX 3090 GPU上,Squint仅用15分钟就完成了策略训练,并且大多数任务在6分钟内收敛。实验结果表明,Squint比之前的视觉离线和在线方法实现了更快的实际训练时间,并且成功地将训练好的策略迁移到真实的SO-101机器人上。
🎯 应用场景
Squint具有广泛的应用前景,可用于各种机器人控制任务,例如物体抓取、装配、导航等。该方法可以加速机器人的训练过程,降低开发成本,并提高机器人的性能。此外,Squint还可以应用于其他视觉强化学习领域,例如游戏AI、自动驾驶等,具有重要的实际价值和未来影响。
📄 摘要(原文)
Visual reinforcement learning is appealing for robotics but expensive -- off-policy methods are sample-efficient yet slow; on-policy methods parallelize well but waste samples. Recent work has shown that off-policy methods can train faster than on-policy methods in wall-clock time for state-based control. Extending this to vision remains challenging, where high-dimensional input images complicate training dynamics and introduce substantial storage and encoding overhead. To address these challenges, we introduce Squint, a visual Soft Actor Critic method that achieves faster wall-clock training than prior visual off-policy and on-policy methods. Squint achieves this via parallel simulation, a distributional critic, resolution squinting, layer normalization, a tuned update-to-data ratio, and an optimized implementation. We evaluate on the SO-101 Task Set, a new suite of eight manipulation tasks in ManiSkill3 with heavy domain randomization, and demonstrate sim-to-real transfer to a real SO-101 robot. We train policies for 15 minutes on a single RTX 3090 GPU, with most tasks converging in under 6 minutes.