ActionReasoning: Robot Action Reasoning in 3D Space with LLM for Robotic Brick Stacking
作者: Guangming Wang, Qizhen Ying, Yixiong Jing, Olaf Wysocki, Brian Sheil
分类: cs.RO
发布日期: 2026-02-24
备注: 8 pages, 5 figures, accepted by the 2026 IEEE International Conference on Robotics and Automation
💡 一句话要点
ActionReasoning:利用LLM进行3D空间机器人动作推理,实现积木堆叠
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 大型语言模型 动作推理 物理约束 多智能体系统
📋 核心要点
- 现有机器人系统依赖定制规划器,泛化能力不足,难以应对复杂环境。
- ActionReasoning利用LLM进行显式动作推理,生成物理一致的机器人操作决策。
- 实验表明,该框架能稳定放置积木,并降低了对领域特定编码的依赖。
📝 摘要(中文)
传统的机器人系统通常依赖于为受限环境设计的定制规划器。虽然这些系统在受限环境中有效,但缺乏泛化能力,限制了具身人工智能和通用机器人的可扩展性。最近的数据驱动的视觉-语言-动作(VLA)方法旨在从大规模模拟和真实世界数据中学习策略。然而,物理世界的连续动作空间大大超过了语言token的表征能力,使得仅靠扩展数据是否能产生通用机器人智能尚不清楚。为了解决这个差距,我们提出了ActionReasoning,一个LLM驱动的框架,它执行显式的动作推理,以产生物理一致的、先验引导的机器人操作决策。ActionReasoning利用了大型语言模型(LLM)中已经编码的物理先验和真实世界知识,并在多智能体架构中对其进行结构化。我们在一个可处理的积木堆叠案例研究中实例化了这个框架,其中环境状态被假定为已经被精确测量。然后,环境状态被序列化并传递给一个多智能体LLM框架,该框架生成具有物理意识的动作计划。实验表明,所提出的多智能体LLM框架能够实现稳定的积木放置,同时将工作从低级领域特定编码转移到高级工具调用和提示,突出了其更广泛的泛化潜力。这项工作介绍了一种有前景的方法,通过将物理推理与LLM集成,来桥接机器人操作中的感知和执行。
🔬 方法详解
问题定义:现有机器人系统在复杂环境中泛化能力不足,主要原因是其依赖于为特定任务和环境设计的定制规划器。这些规划器难以适应新的环境和任务,限制了机器人的通用性和可扩展性。此外,数据驱动的VLA方法虽然有潜力,但物理世界的连续动作空间远超语言token的表达能力,单纯依靠数据扩展难以实现通用机器人智能。
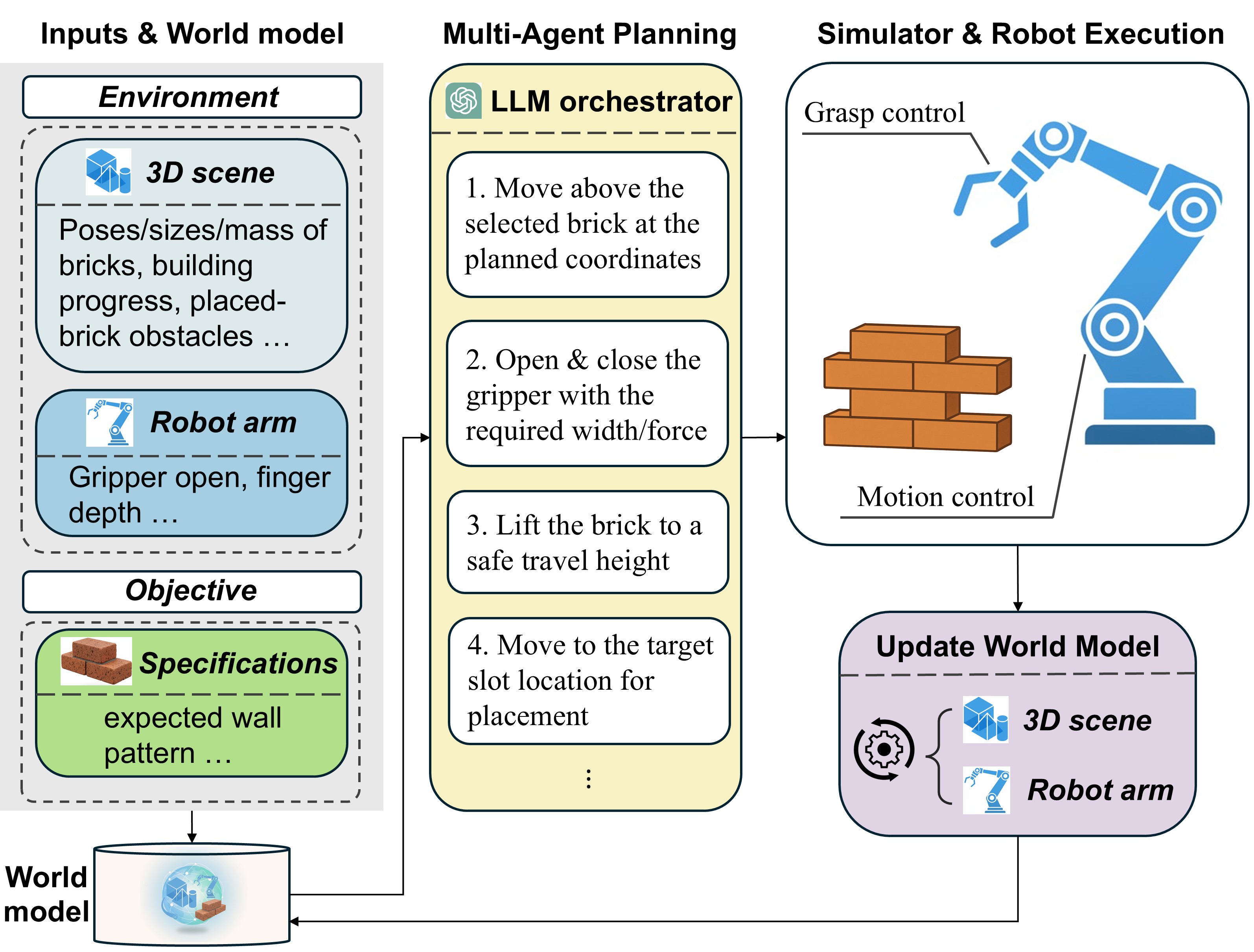
核心思路:ActionReasoning的核心思路是利用大型语言模型(LLM)中蕴含的物理先验知识和常识,通过显式的动作推理来指导机器人操作。该方法将复杂的机器人控制问题分解为一系列可解释的步骤,并利用LLM生成符合物理规律的动作计划,从而提高机器人的泛化能力和鲁棒性。
技术框架:ActionReasoning采用多智能体架构,主要包含以下几个模块:1) 环境状态感知模块:负责获取当前环境的状态信息,例如积木的位置和姿态。2) LLM推理模块:接收环境状态信息,利用LLM进行动作推理,生成动作计划。该模块是核心,通过prompt工程,引导LLM输出符合物理规律的动作序列。3) 动作执行模块:将LLM生成的动作计划转化为具体的机器人控制指令,控制机器人执行动作。4) 状态更新模块:根据机器人执行的动作,更新环境状态信息,为下一步的动作推理提供依据。
关键创新:ActionReasoning的关键创新在于将LLM的推理能力与机器人操作相结合,通过显式的动作推理来指导机器人行为。与传统的端到端学习方法相比,ActionReasoning具有更强的可解释性和泛化能力。此外,该方法将低级领域特定编码转移到高级工具调用和prompt工程,降低了开发成本和难度。
关键设计:ActionReasoning的关键设计包括:1) 环境状态的序列化表示:将3D空间中的物体位置和姿态信息转化为LLM可以理解的文本序列。2) 多智能体架构:将LLM分解为多个智能体,每个智能体负责不同的任务,例如动作规划、物理约束检查等。3) Prompt工程:设计合适的prompt,引导LLM生成符合物理规律的动作序列。具体的prompt设计需要根据任务的特点进行调整,例如可以包含物理规则、目标描述、以及历史动作等信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,ActionReasoning能够实现稳定的积木放置,并且能够将工作从低级领域特定编码转移到高级工具调用和提示。这表明ActionReasoning具有良好的泛化能力和可扩展性。虽然论文没有提供具体的性能数据和对比基线,但其提出的方法为机器人操作提供了一种新的思路,具有重要的研究价值。
🎯 应用场景
ActionReasoning具有广泛的应用前景,可应用于工业自动化、家庭服务、医疗机器人等领域。例如,在工业自动化中,可以利用ActionReasoning实现复杂零件的装配和搬运;在家庭服务中,可以利用ActionReasoning实现家务清洁和物品整理;在医疗机器人中,可以利用ActionReasoning辅助医生进行手术操作。该研究有望推动机器人技术的发展,使其能够更好地服务于人类。
📄 摘要(原文)
Classical robotic systems typically rely on custom planners designed for constrained environments. While effective in restricted settings, these systems lack generalization capabilities, limiting the scalability of embodied AI and general-purpose robots. Recent data-driven Vision-Language-Action (VLA) approaches aim to learn policies from large-scale simulation and real-world data. However, the continuous action space of the physical world significantly exceeds the representational capacity of linguistic tokens, making it unclear if scaling data alone can yield general robotic intelligence. To address this gap, we propose ActionReasoning, an LLM-driven framework that performs explicit action reasoning to produce physics-consistent, prior-guided decisions for robotic manipulation. ActionReasoning leverages the physical priors and real-world knowledge already encoded in Large Language Models (LLMs) and structures them within a multi-agent architecture. We instantiate this framework on a tractable case study of brick stacking, where the environment states are assumed to be already accurately measured. The environmental states are then serialized and passed to a multi-agent LLM framework that generates physics-aware action plans. The experiments demonstrate that the proposed multi-agent LLM framework enables stable brick placement while shifting effort from low-level domain-specific coding to high-level tool invocation and prompting, highlighting its potential for broader generalization. This work introduces a promising approach to bridging perception and execution in robotic manipulation by integrating physical reasoning with LLMs.