HALO: A Unified Vision-Language-Action Model for Embodied Multimodal Chain-of-Thought Reasoning
作者: Quanxin Shou, Fangqi Zhu, Shawn Chen, Puxin Yan, Zhengyang Yan, Yikun Miao, Xiaoyi Pang, Zicong Hong, Ruikai Shi, Hao Huang, Jie Zhang, Song Guo
分类: cs.RO
发布日期: 2026-02-24
💡 一句话要点
提出HALO,用于具身多模态链式思考推理的统一视觉-语言-动作模型
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 机器人操作 链式思考 多模态推理 具身智能
📋 核心要点
- 现有VLA模型在长时程任务和分布外场景中表现不佳,缺乏多模态推理和对动作影响的预测能力。
- HALO模型通过文本任务推理、视觉子目标预测和EM-CoT增强的动作预测,实现具身多模态链式思考推理。
- 实验表明,HALO在模拟和真实环境中均优于基线模型,并在环境随机化下表现出强大的泛化能力。
📝 摘要(中文)
视觉-语言-动作(VLA)模型在机器人操作方面表现出强大的性能,但由于缺乏用于多模态推理和预测动作下世界如何演变的显式机制,因此在长时程或分布外场景中常常表现不佳。最近的研究在VLA模型中引入了文本链式思考或视觉子目标预测来进行推理,但仍然无法提供统一的类人推理框架,以进行联合文本推理、视觉预测和动作预测。为此,我们提出了HALO,一种统一的VLA模型,它通过文本任务推理、用于细粒度指导的视觉子目标预测和EM-CoT增强的动作预测的顺序过程,实现具身多模态链式思考(EM-CoT)推理。我们使用混合Transformer(MoT)架构实例化HALO,该架构将语义推理、视觉预测和动作预测解耦为专门的专家,同时允许无缝的跨专家协作。为了实现大规模的HALO学习,我们引入了一个自动化的流水线来合成EM-CoT训练数据,以及精心设计的训练方案。大量的实验表明:(1)HALO在模拟和真实环境中都取得了优异的性能,在RoboTwin基准测试中超过了基线策略pi_0 34.1%;(2)所提出的训练方案和EM-CoT设计的所有组件都有助于提高任务成功率;(3)HALO在我们提出的EM-CoT推理下,在激进的、未见过的环境随机化下表现出强大的泛化能力。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型在机器人操作任务中,尤其是在长时程或分布外场景下,面临着推理能力不足的问题。它们缺乏明确的机制来进行多模态推理,无法有效地预测动作对环境的影响,导致任务完成效果不佳。现有方法虽然尝试引入文本链式思考或视觉子目标预测,但未能提供一个统一的、类似人类的推理框架,将文本推理、视觉预测和动作预测整合起来。
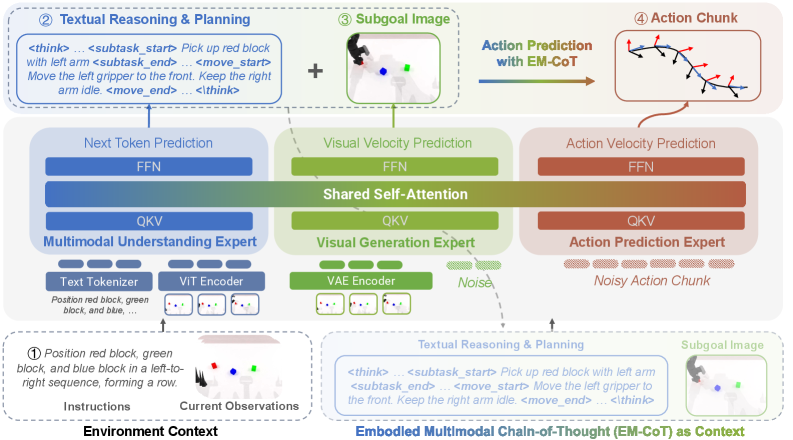
核心思路:HALO的核心思路是构建一个统一的视觉-语言-动作模型,通过模拟人类的链式思考过程,实现更强的推理能力。具体来说,它将任务分解为文本任务推理、视觉子目标预测和动作预测三个阶段,并通过具身多模态链式思考(EM-CoT)将它们连接起来。这种设计允许模型在执行动作之前,先理解任务目标,预测动作的视觉效果,从而做出更明智的决策。
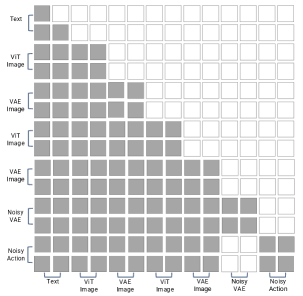
技术框架:HALO模型采用混合Transformer(MoT)架构。该架构将语义推理、视觉预测和动作预测解耦为三个专门的专家模块,每个模块负责处理特定类型的信息。同时,MoT架构允许这些专家模块之间进行无缝的跨专家协作,从而实现信息的有效传递和融合。整体流程包括:首先,文本任务推理模块理解任务目标;然后,视觉子目标预测模块预测执行动作后的视觉效果;最后,EM-CoT增强的动作预测模块根据前两个模块的输出,预测下一步的动作。
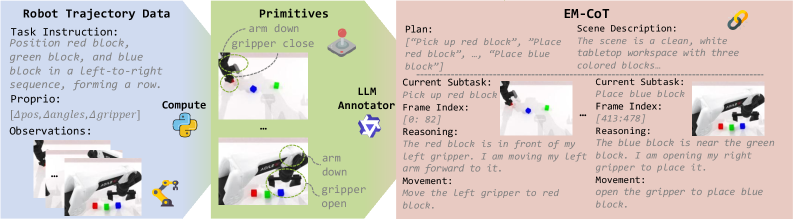
关键创新:HALO的关键创新在于其统一的具身多模态链式思考(EM-CoT)框架。该框架将文本推理、视觉预测和动作预测整合到一个统一的模型中,允许模型在执行动作之前进行更全面的推理。此外,HALO还引入了一个自动化的流水线来合成EM-CoT训练数据,从而实现大规模的模型训练。与现有方法相比,HALO能够更好地理解任务目标,预测动作的影响,并做出更明智的决策。
关键设计:HALO的关键设计包括:1) 使用混合Transformer(MoT)架构,将不同类型的推理任务解耦为专门的专家模块;2) 引入具身多模态链式思考(EM-CoT)框架,将文本推理、视觉预测和动作预测整合到一个统一的模型中;3) 开发自动化的流水线来合成EM-CoT训练数据,从而实现大规模的模型训练。具体的参数设置、损失函数和网络结构等细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片
📊 实验亮点
HALO在RoboTwin基准测试中,任务成功率超过基线策略pi_0 34.1%,表明其在机器人操作任务中具有显著的性能优势。此外,实验还表明,HALO的各个组成部分,包括训练方案和EM-CoT设计,都有助于提高任务成功率。HALO在环境随机化的情况下表现出强大的泛化能力,证明了其在实际应用中的潜力。
🎯 应用场景
HALO模型具有广泛的应用前景,可应用于机器人操作、自动驾驶、智能家居等领域。例如,在机器人操作中,HALO可以帮助机器人更好地理解任务目标,预测动作的影响,从而完成更复杂的任务。在自动驾驶中,HALO可以帮助车辆更好地理解交通规则,预测其他车辆的行驶轨迹,从而提高驾驶安全性。在智能家居中,HALO可以帮助设备更好地理解用户的意图,提供更智能的服务。
📄 摘要(原文)
Vision-Language-Action (VLA) models have shown strong performance in robotic manipulation, but often struggle in long-horizon or out-of-distribution scenarios due to the lack of explicit mechanisms for multimodal reasoning and anticipating how the world will evolve under action. Recent works introduce textual chain-of-thought or visual subgoal prediction within VLA models to reason, but still fail to offer a unified human-like reasoning framework for joint textual reasoning, visual foresight, and action prediction. To this end, we propose HALO, a unified VLA model that enables embodied multimodal chain-of-thought (EM-CoT) reasoning through a sequential process of textual task reasoning, visual subgoal prediction for fine-grained guidance, and EM-CoT-augmented action prediction. We instantiate HALO with a Mixture-of-Transformers (MoT) architecture that decouples semantic reasoning, visual foresight, and action prediction into specialized experts while allowing seamless cross-expert collaboration. To enable HALO learning at scale, we introduce an automated pipeline to synthesize EM-CoT training data along with a carefully crafted training recipe. Extensive experiments demonstrate that: (1) HALO achieves superior performance in both simulated and real-world environments, surpassing baseline policy pi_0 by 34.1% on RoboTwin benchmark; (2) all proposed components of the training recipe and EM-CoT design help improve task success rate; and (3) HALO exhibits strong generalization capabilities under aggressive unseen environmental randomization with our proposed EM-CoT reasoning.