Cooperative-Competitive Team Play of Real-World Craft Robots
作者: Rui Zhao, Xihui Li, Yizheng Zhang, Yuzhen Liu, Zhong Zhang, Yufeng Zhang, Cheng Zhou, Zhengyou Zhang, Lei Han
分类: cs.RO, cs.AI
发布日期: 2026-02-24
备注: Accepted by 2026 IEEE International Conference on Robotics and Automation (ICRA 2026), Vienna, Austria
💡 一句话要点
提出基于强化学习的协同-竞争机器人团队控制方法,并解决Sim2Real迁移问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 Sim2Real 机器人集群控制 协同-竞争 域适应 Out of Distribution State Initialization 分布式学习
📋 核心要点
- 多智能体强化学习在机器人集群控制中面临训练效率和策略迁移的挑战。
- 提出基于强化学习的协同-竞争策略训练方法,并引入OODSI解决Sim2Real迁移问题。
- 实验表明,OODSI能有效提升Sim2Real性能20%,并在真实机器人环境中验证了方法的有效性。
📝 摘要(中文)
近年来,多智能体深度强化学习(RL)在开发智能游戏智能体方面取得了显著进展。然而,如何使用多智能体RL有效训练集群机器人,以及如何将学习到的策略迁移到实际应用中,仍然是开放的研究问题。本文首先开发了一个全面的机器人系统,包括仿真、分布式学习框架和物理机器人组件。然后,我们提出并评估了专为在该平台上高效训练合作和竞争策略而设计的强化学习技术。为了解决多智能体Sim2Real迁移的挑战,我们引入了Out of Distribution State Initialization (OODSI)来减轻Sim2Real差距的影响。在实验中,OODSI将Sim2Real性能提高了20%。我们通过多机器人汽车竞争游戏和现实环境中的合作任务的实验,证明了我们方法的有效性。
🔬 方法详解
问题定义:现有方法在多智能体强化学习中,难以高效地训练集群机器人,并且学习到的策略难以直接迁移到真实环境中,存在较大的Sim2Real差距。尤其是在协同和竞争并存的复杂任务中,如何平衡训练效率和泛化能力是一个挑战。
核心思路:本文的核心思路是设计一种强化学习框架,能够同时处理协同和竞争任务,并通过Out of Distribution State Initialization (OODSI)方法来缩小仿真环境和真实环境之间的差距,从而提高策略的迁移能力。
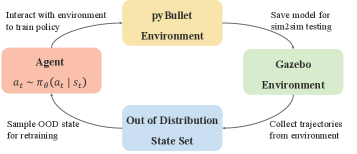
技术框架:该框架包含三个主要部分:1) 仿真环境,用于快速生成训练数据;2) 分布式学习框架,用于加速训练过程;3) 物理机器人系统,用于验证学习到的策略。OODSI作为一种数据增强方法,在训练过程中引入超出仿真环境分布的状态,迫使智能体学习更鲁棒的策略。
关键创新:最重要的技术创新点是OODSI方法,它通过在训练初期引入与真实环境更接近的、但仿真环境中未出现的初始状态,来提高智能体对真实环境的适应性。这与传统的域适应方法不同,OODSI更侧重于状态空间的探索,而非特征空间的对齐。
关键设计:OODSI的具体实现方式是,在每个episode开始时,以一定的概率从一个预先定义的、超出仿真环境状态分布的集合中随机选择一个状态作为初始状态。这个集合可以通过真实环境的数据收集得到。损失函数采用标准的强化学习损失函数,例如PPO或SAC。网络结构的选择取决于具体的任务,可以是MLP或CNN等。
🖼️ 关键图片


📊 实验亮点
实验结果表明,OODSI方法能够显著提高Sim2Real的性能,在多机器人汽车竞争游戏中,OODSI将Sim2Real性能提高了20%。此外,该方法还在真实的机器人协同任务中得到了验证,证明了其在实际应用中的有效性。这些结果表明,OODSI是一种有效的解决Sim2Real问题的技术。
🎯 应用场景
该研究成果可应用于多机器人协同作业、自动驾驶、智能交通等领域。例如,在仓库物流中,多个机器人可以协同完成货物的搬运和分拣任务;在自动驾驶中,多个车辆可以协同规划行驶路线,提高交通效率和安全性。该研究为实现复杂环境下的多智能体自主控制提供了新的思路。
📄 摘要(原文)
Multi-agent deep Reinforcement Learning (RL) has made significant progress in developing intelligent game-playing agents in recent years. However, the efficient training of collective robots using multi-agent RL and the transfer of learned policies to real-world applications remain open research questions. In this work, we first develop a comprehensive robotic system, including simulation, distributed learning framework, and physical robot components. We then propose and evaluate reinforcement learning techniques designed for efficient training of cooperative and competitive policies on this platform. To address the challenges of multi-agent sim-to-real transfer, we introduce Out of Distribution State Initialization (OODSI) to mitigate the impact of the sim-to-real gap. In the experiments, OODSI improves the Sim2Real performance by 20%. We demonstrate the effectiveness of our approach through experiments with a multi-robot car competitive game and a cooperative task in real-world settings.