Notes-to-Self: Scratchpad Augmented VLAs for Memory Dependent Manipulation Tasks
作者: Sanjay Haresh, Daniel Dijkman, Apratim Bhattacharyya, Roland Memisevic
分类: cs.RO
发布日期: 2026-02-24
备注: To appear at ICRA 2026
💡 一句话要点
提出基于语言暂存器的VLA模型,解决记忆依赖操作任务中的长时序问题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作 机器人操作 长期记忆 语言暂存器 非马尔可夫 任务规划 深度学习
📋 核心要点
- 现有VLA模型在处理需要记忆和长期规划的复杂操作任务时表现不足,缺乏对任务状态的有效记忆。
- 该论文提出一种新的VLA架构,通过引入语言暂存器来存储和更新任务相关信息,从而增强模型的记忆能力。
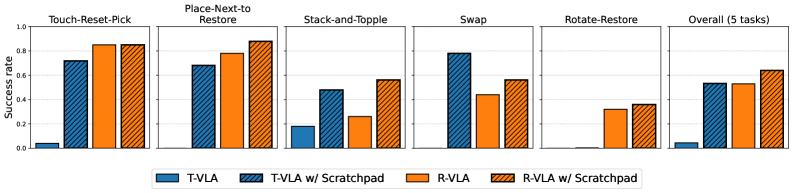
- 实验表明,该方法在多个记忆依赖任务上显著提高了泛化性能,包括模拟环境和真实世界的机器人操作。
📝 摘要(中文)
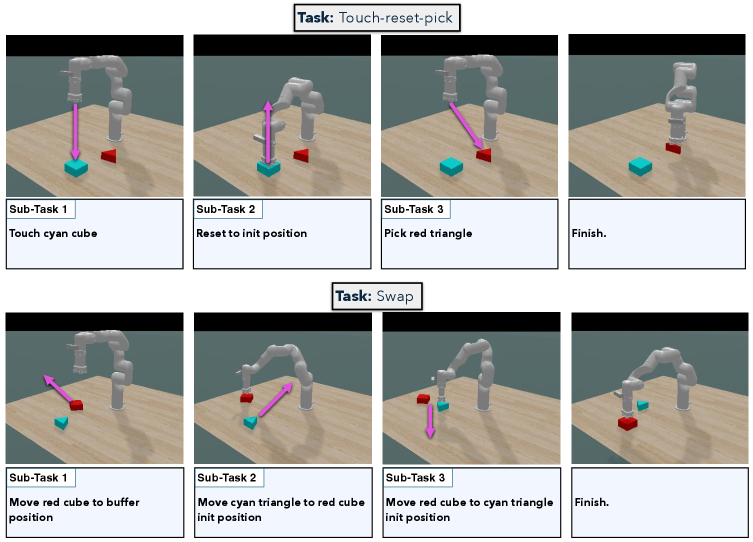
许多灵巧操作任务本质上是非马尔可夫的,但视觉-语言-动作(VLA)领域对此关注不足。现有的VLA模型虽然成功地将互联网规模的语义理解引入机器人技术,但主要是“无状态”的,难以处理记忆依赖的长时序任务。本文探索了一种通过引入语言暂存器来赋予VLA空间和时间记忆的方法。暂存器可以记忆特定于任务的信息,例如对象位置,并允许模型跟踪计划以及计划中子目标的进展。我们在ClevrSkills环境中记忆依赖任务的分割、MemoryBench以及具有挑战性的真实世界抓取放置任务上评估了该方法。结果表明,对于非循环和循环模型,引入语言暂存器可以显著提高这些任务的泛化能力。
🔬 方法详解
问题定义:现有的视觉-语言-动作(VLA)模型在处理需要长期记忆和规划的操作任务时面临挑战。这些模型通常是“无状态”的,无法有效地记住过去的信息,导致在非马尔可夫环境中表现不佳。例如,在需要记住物体位置或执行一系列步骤的任务中,传统VLA模型难以做出正确的决策。
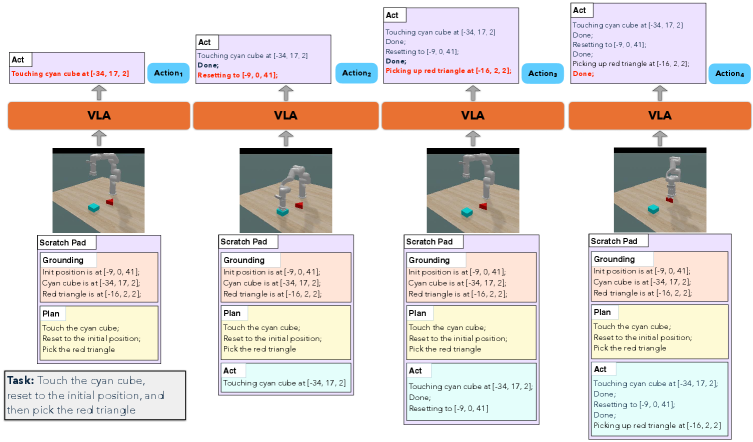
核心思路:该论文的核心思路是引入一个语言暂存器(language scratchpad),作为VLA模型的外部记忆模块。这个暂存器可以存储和更新任务相关的空间和时间信息,例如物体的位置、任务的进度等。通过利用暂存器,模型可以更好地跟踪任务状态,从而做出更明智的决策。
技术框架:该方法的核心是构建一个带有语言暂存器的VLA模型。整体框架包括以下几个主要模块:1) 视觉输入编码器:将输入的图像转换为视觉特征向量。2) 语言输入编码器:将输入的指令转换为语言特征向量。3) 语言暂存器:用于存储和更新任务相关信息的记忆模块。4) 动作预测模块:根据视觉特征、语言特征和暂存器中的信息,预测下一步的动作。模型通过循环更新暂存器中的信息,从而实现长期记忆和规划。
关键创新:该论文的关键创新在于将语言暂存器引入VLA模型,从而赋予模型长期记忆能力。与传统的循环神经网络(RNN)或Transformer等方法相比,语言暂存器可以更清晰地表示任务状态,并且更容易进行解释和调试。此外,该方法还能够处理空间信息,例如物体的位置,这对于操作任务至关重要。
关键设计:语言暂存器采用文本形式存储信息,例如“object A is at (x, y)”。模型使用自然语言处理技术来解析和更新暂存器中的信息。损失函数包括动作预测损失和暂存器更新损失,用于训练模型预测正确的动作并更新暂存器中的信息。具体实现细节(如编码器类型、暂存器更新策略等)可能因具体任务而异。
🖼️ 关键图片
📊 实验亮点
实验结果表明,引入语言暂存器可以显著提高VLA模型在记忆依赖任务上的泛化性能。在ClevrSkills环境的记忆依赖任务上,该方法相比基线模型取得了显著的性能提升。在MemoryBench和真实世界的抓取放置任务上,该方法也表现出良好的性能。具体数据提升幅度未知,但论文强调了“显著提高”。
🎯 应用场景
该研究成果可应用于各种需要长期记忆和规划的机器人操作任务,例如装配、清洁、烹饪等。通过赋予机器人更强的记忆能力,可以使其更好地适应复杂和动态的环境,从而提高其自主性和效率。此外,该方法还可以应用于虚拟助手、智能家居等领域,提升人机交互的自然性和智能化水平。
📄 摘要(原文)
Many dexterous manipulation tasks are non-markovian in nature, yet little attention has been paid to this fact in the recent upsurge of the vision-language-action (VLA) paradigm. Although they are successful in bringing internet-scale semantic understanding to robotics, existing VLAs are primarily "stateless" and struggle with memory-dependent long horizon tasks. In this work, we explore a way to impart both spatial and temporal memory to a VLA by incorporating a language scratchpad. The scratchpad makes it possible to memorize task-specific information, such as object positions, and it allows the model to keep track of a plan and progress towards subgoals within that plan. We evaluate this approach on a split of memory-dependent tasks from the ClevrSkills environment, on MemoryBench, as well as on a challenging real-world pick-and-place task. We show that incorporating a language scratchpad significantly improves generalization on these tasks for both non-recurrent and recurrent models.