IG-RFT: An Interaction-Guided RL Framework for VLA Models in Long-Horizon Robotic Manipulation
作者: Zhian Su, Weijie Kong, Haonan Dong, Huixu Dong
分类: cs.RO
发布日期: 2026-02-24
💡 一句话要点
提出IG-RFT,用于长时程机器人操作中VLA模型的交互引导强化学习微调
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 强化学习 机器人操作 长时程任务 交互引导 离线强化学习 人机协作
📋 核心要点
- VLA模型在长时程机器人任务中面临泛化性挑战,主要原因是真实世界数据分布偏移和高质量演示数据不足。
- 论文提出IG-RFT框架,通过交互引导的强化学习微调VLA模型,提升探索效率和训练稳定性。
- 实验表明,IG-RFT在真实世界长时程任务中显著优于SFT和离线RL基线,成功率提升明显。
📝 摘要(中文)
视觉-语言-动作(VLA)模型在通用机器人策略方面展现出巨大潜力,但由于分布偏移和高质量演示数据的稀缺,它们难以泛化到新的真实世界领域中的长时程复杂任务。强化学习(RL)为策略改进提供了一条有希望的途径,但将其应用于真实世界的VLA微调面临着探索效率、训练稳定性和样本成本方面的挑战。为了解决这些问题,我们提出了一种新颖的交互引导强化微调系统IG-RFT,专为基于流的VLA模型设计。首先,为了促进有效的策略优化,我们引入了交互引导优势加权回归(IG-AWR),这是一种RL算法,可根据机器人的交互状态动态调节探索强度。此外,为了解决稀疏或特定于任务的奖励的局限性,我们设计了一种新颖的混合密集奖励函数,该函数集成了轨迹级奖励和子任务级奖励。最后,我们构建了一个三阶段RL系统,包括SFT、离线RL和人机协作RL,用于微调VLA模型。在四个具有挑战性的长时程任务上的大量真实世界实验表明,IG-RFT实现了平均85.0%的成功率,显著优于SFT(18.8%)和标准离线RL基线(40.0%)。消融研究证实了IG-AWR和混合奖励塑造的关键贡献。总之,我们的工作建立并验证了一种用于真实世界机器人操作中VLA模型的新型强化微调系统。
🔬 方法详解
问题定义:现有VLA模型在长时程机器人操作任务中,难以泛化到新的真实世界环境。主要痛点在于数据分布偏移、高质量演示数据稀缺,以及强化学习微调过程中的探索效率低、训练不稳定和样本成本高昂。
核心思路:论文的核心思路是通过强化学习(RL)微调VLA模型,并引入交互引导机制来提升RL的效率和稳定性。具体来说,根据机器人的交互状态动态调节探索强度,并设计混合密集奖励函数来克服稀疏奖励的局限性。
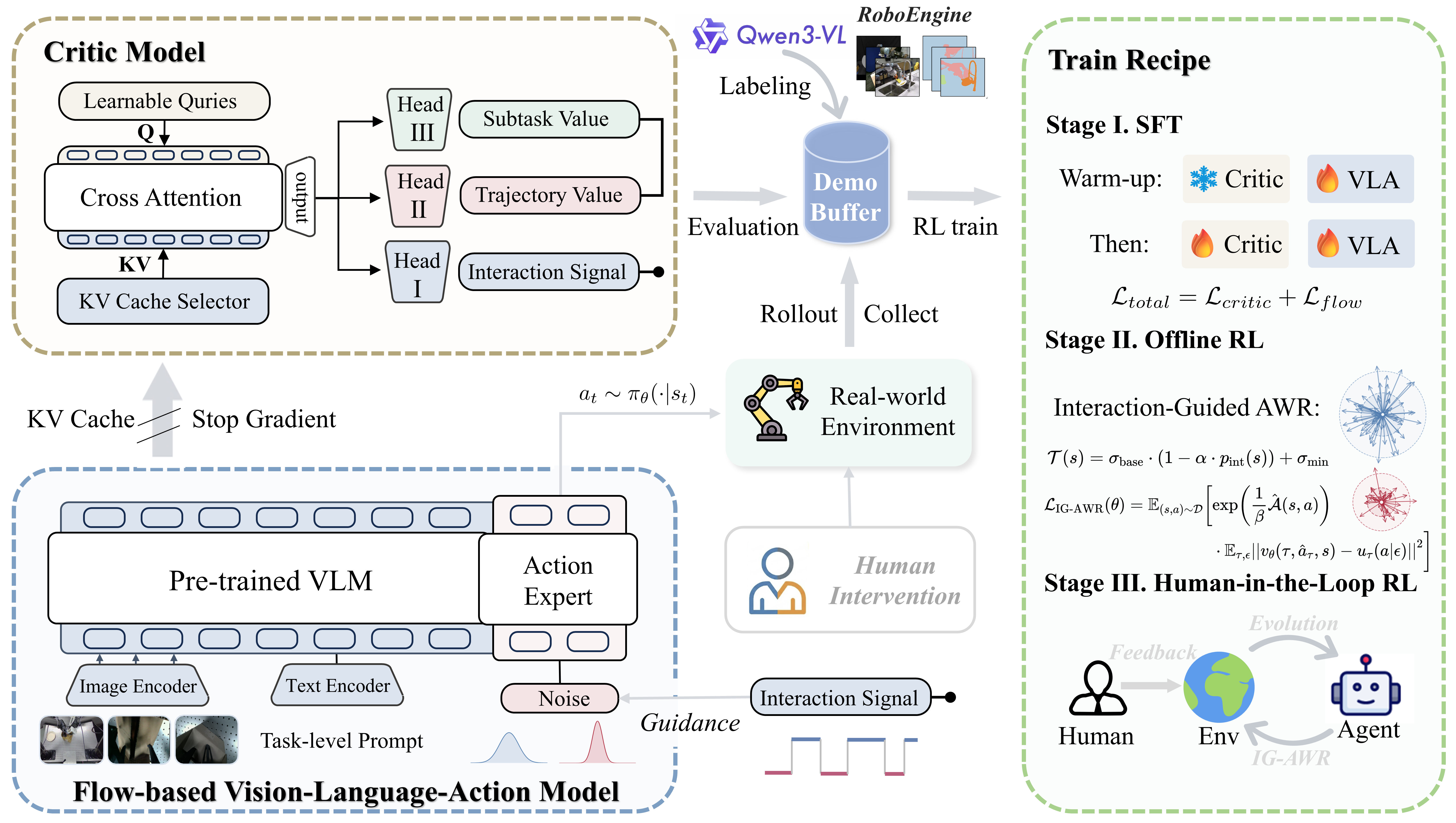
技术框架:IG-RFT框架包含三个主要阶段:1) SFT(Supervised Fine-Tuning):使用少量高质量演示数据对VLA模型进行监督微调,作为RL的初始化策略。2) 离线RL:利用离线数据集进行策略学习,提高样本利用率。3) 人机协作RL:引入人工干预,进一步优化策略,解决探索难题。框架的核心是IG-AWR算法和混合奖励函数。
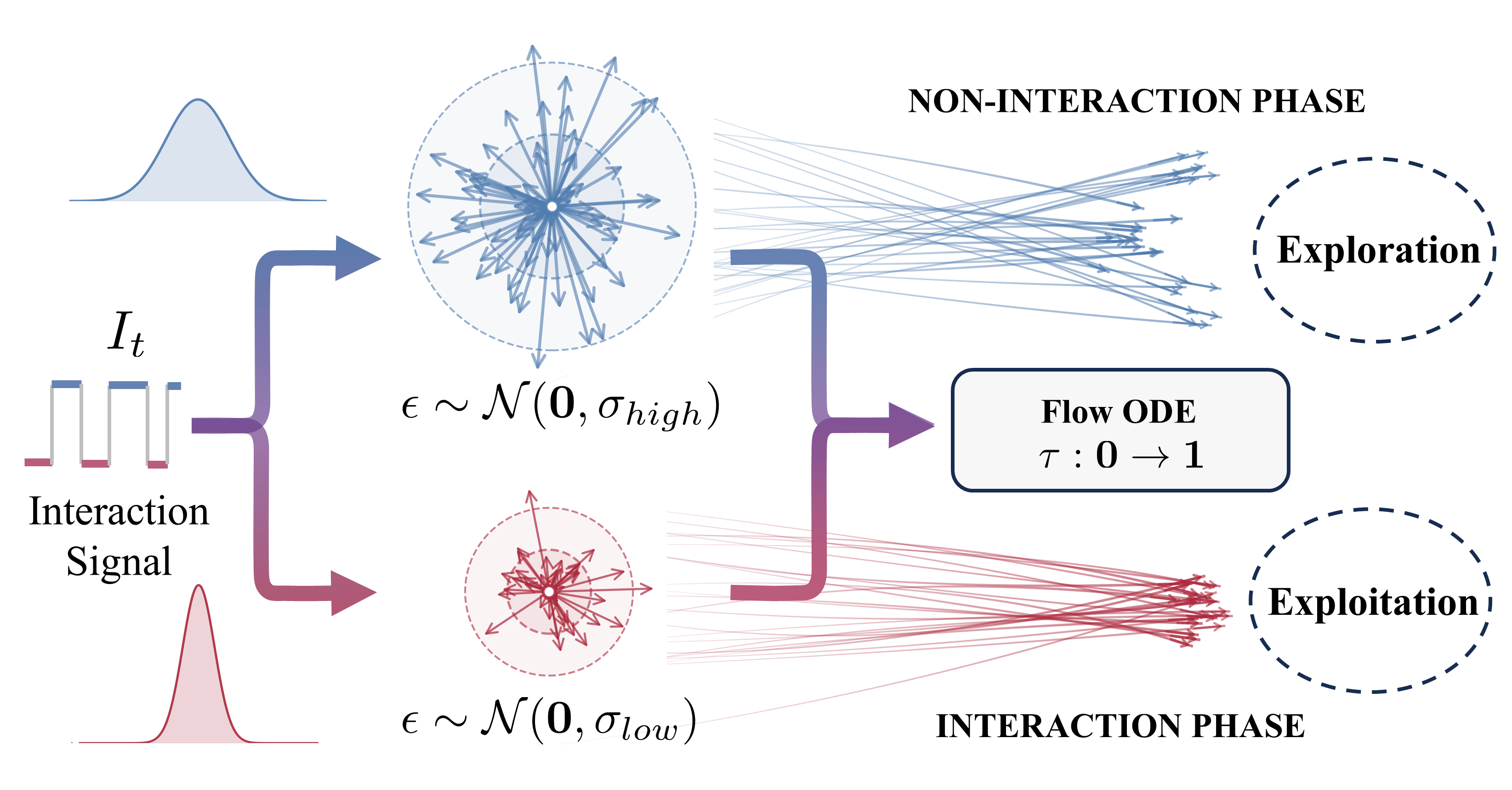
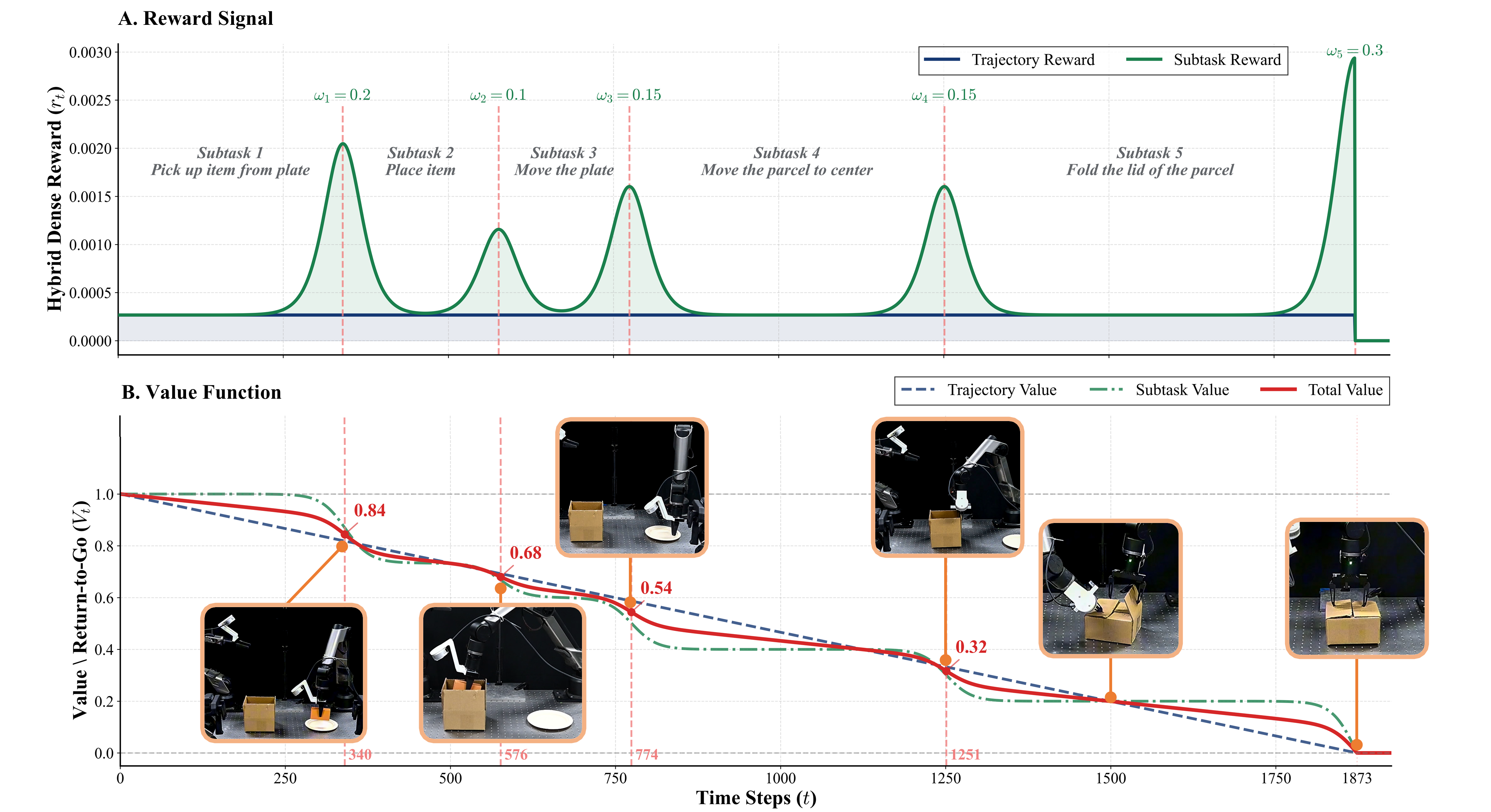
关键创新:论文的关键创新在于提出了交互引导优势加权回归(IG-AWR)算法和混合密集奖励函数。IG-AWR根据机器人的交互状态动态调节探索强度,鼓励机器人探索更有价值的状态空间。混合奖励函数结合了轨迹级奖励和子任务级奖励,克服了稀疏奖励带来的训练难题。
关键设计:IG-AWR算法通过一个动态调整的温度参数来控制探索强度,该参数基于机器人与环境的交互状态进行调整。混合奖励函数由轨迹级别的稀疏奖励和子任务级别的密集奖励组成,其中子任务奖励的设计需要根据具体任务进行调整。三阶段训练策略也至关重要,SFT提供良好的初始化,离线RL提高样本效率,人机协作RL解决探索问题。
🖼️ 关键图片
📊 实验亮点
在四个具有挑战性的长时程机器人操作任务上,IG-RFT取得了显著的性能提升。平均成功率达到85.0%,显著优于SFT(18.8%)和标准离线RL基线(40.0%)。消融实验证明了IG-AWR算法和混合奖励函数的有效性,表明它们对整体性能提升至关重要。
🎯 应用场景
该研究成果可应用于各种长时程机器人操作任务,例如装配、抓取、导航等。通过提升VLA模型在真实世界环境中的泛化能力,可以降低机器人部署成本,提高自动化水平,并促进机器人技术在制造业、物流、医疗等领域的广泛应用。
📄 摘要(原文)
Vision-Language-Action (VLA) models have demonstrated significant potential for generalist robotic policies; however, they struggle to generalize to long-horizon complex tasks in novel real-world domains due to distribution shifts and the scarcity of high-quality demonstrations. Although reinforcement learning (RL) offers a promising avenue for policy improvement, applying it to real-world VLA fine-tuning faces challenges regarding exploration efficiency, training stability, and sample cost. To address these issues, we propose IG-RFT, a novel Interaction-Guided Reinforced Fine-Tuning system designed for flow-based VLA models. Firstly, to facilitate effective policy optimization, we introduce Interaction-Guided Advantage Weighted Regression (IG-AWR), an RL algorithm that dynamically modulates exploration intensity based on the robot's interaction status. Furthermore, to address the limitations of sparse or task-specific rewards, we design a novel hybrid dense reward function that integrates the trajectory-level reward and the subtask-level reward. Finally, we construct a three-stage RL system comprising SFT, Offline RL, and Human-in-the-Loop RL for fine-tuning VLA models. Extensive real-world experiments on four challenging long-horizon tasks demonstrate that IG-RFT achieves an average success rate of 85.0%, significantly outperforming SFT (18.8%) and standard Offline RL baselines (40.0%). Ablation studies confirm the critical contributions of IG-AWR and hybrid reward shaping. In summary, our work establishes and validates a novel reinforced fine-tuning system for VLA models in real-world robotic manipulation.