BFA++: Hierarchical Best-Feature-Aware Token Prune for Multi-View Vision Language Action Model
作者: Haosheng Li, Weixin Mao, Zihan Lan, Hongwei Xiong, Hongan Wang, Chenyang Si, Ziwei Liu, Xiaoming Deng, Hua Chen
分类: cs.RO, cs.CV
发布日期: 2026-02-24
备注: 9 pages, 10 figures
💡 一句话要点
BFA++:面向多视角VLA模型的分层最佳特征感知Token剪枝
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 Token剪枝 多视角学习 机器人操作 分层剪枝
📋 核心要点
- VLA模型面临多视角输入带来的海量视觉tokens挑战,现有token剪枝方法忽略视角关系和任务动态性,导致性能下降。
- BFA++提出分层token剪枝策略,通过视角内预测器抑制空间噪声,视角间预测器减少跨视角冗余,保留关键视觉信息。
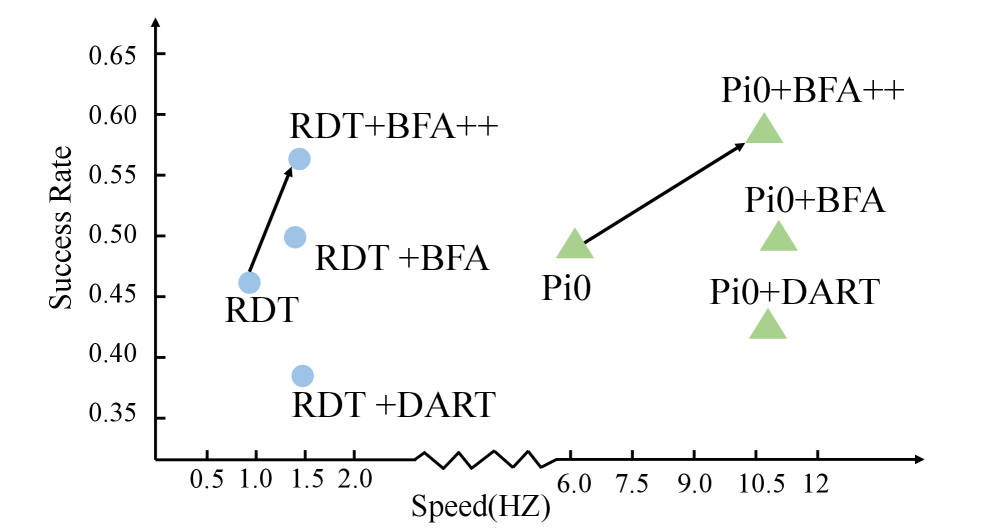
- 实验表明,BFA++在RoboTwin和真实机器人任务中,显著提升了操作成功率(约10%),并实现了1.5-1.8倍的推理加速。
📝 摘要(中文)
视觉-语言-动作(VLA)模型通过利用大型视觉语言模型(VLMs)来联合解释指令和视觉输入,取得了显著突破。然而,视觉tokens的大量增加,特别是来自多视角输入,对实时机器人操作提出了严峻挑战。现有的VLM加速技术,如token剪枝,当直接应用于VLA模型时,通常会导致性能下降,因为它们忽略了不同视角之间的关系,并且未能考虑到机器人操作的动态和任务特定特性。为了解决这个问题,我们提出了BFA++,一个专门为VLA模型设计的动态token剪枝框架。BFA++引入了一种由两级重要性预测器指导的分层剪枝策略:一个视角内预测器突出显示每个图像中的任务相关区域以抑制空间噪声,而一个视角间预测器识别不同操作阶段的关键相机视角以减少跨视角冗余。这种设计实现了高效的token选择,同时保留了必要的视觉线索,从而提高了计算效率和操作成功率。在RoboTwin基准和真实机器人任务上的评估表明,BFA++始终优于现有方法。BFA++在π0和RDT模型上分别提高了约10%的成功率,实现了1.8倍和1.5倍的加速。我们的结果表明,上下文敏感和任务感知的token剪枝是一种比完全视觉处理更有效的策略,从而在实际机器人系统中实现更快的推理和更高的操作精度。
🔬 方法详解
问题定义:VLA模型在处理多视角视觉输入时,面临着计算量巨大的问题。现有的token剪枝方法直接应用于VLA模型时,由于忽略了不同视角之间的关系以及机器人操作的动态性和任务相关性,导致性能显著下降。因此,如何在VLA模型中高效地进行token剪枝,同时保持甚至提升操作性能,是一个亟待解决的问题。
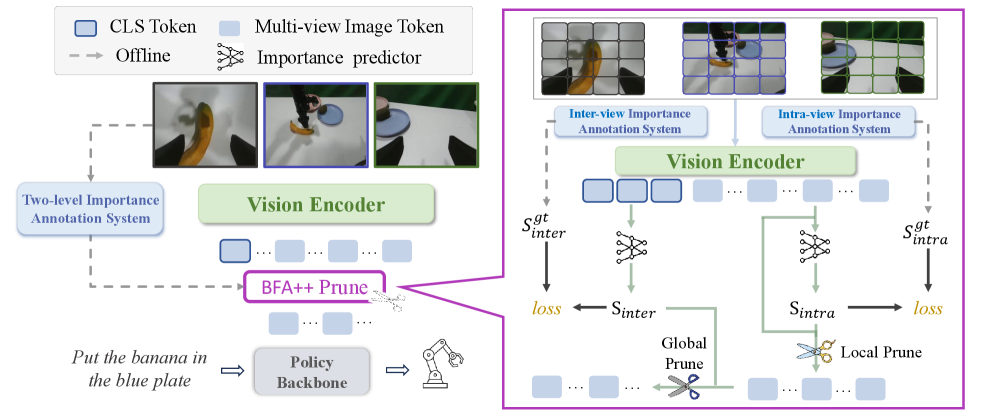
核心思路:BFA++的核心思路是设计一种分层的、任务感知的token剪枝策略。通过在视角内和视角间两个层级上进行重要性预测,从而有选择性地保留对当前任务至关重要的视觉tokens,同时去除冗余和噪声信息。这种方法能够更好地适应VLA模型的特点,提高计算效率和操作成功率。
技术框架:BFA++框架包含两个主要模块:视角内重要性预测器和视角间重要性预测器。首先,视角内预测器针对每个相机视角的图像,预测每个token的重要性,从而突出显示任务相关的区域,抑制空间噪声。然后,视角间预测器评估不同相机视角的重要性,从而在不同的操作阶段选择最关键的视角,减少跨视角冗余。最后,根据两个层级的重要性预测结果,对视觉tokens进行剪枝,并将剪枝后的tokens输入到VLA模型中进行后续处理。
关键创新:BFA++的关键创新在于其分层的token剪枝策略,以及任务感知的重要性预测机制。与传统的token剪枝方法不同,BFA++充分考虑了多视角VLA模型的特点,通过视角内和视角间两个层级的重要性预测,实现了更精细化的token选择。这种分层和任务感知的策略能够更好地保留关键视觉信息,提高操作性能。
关键设计:视角内重要性预测器可以使用卷积神经网络或Transformer等结构,其目标是预测每个视觉token的重要性得分。视角间重要性预测器可以基于注意力机制或强化学习等方法,其目标是评估不同相机视角对当前任务的贡献程度。损失函数的设计需要同时考虑剪枝后的模型性能和计算效率,可以使用交叉熵损失、KL散度等。具体的网络结构、参数设置和损失函数需要根据具体的VLA模型和任务进行调整。
🖼️ 关键图片
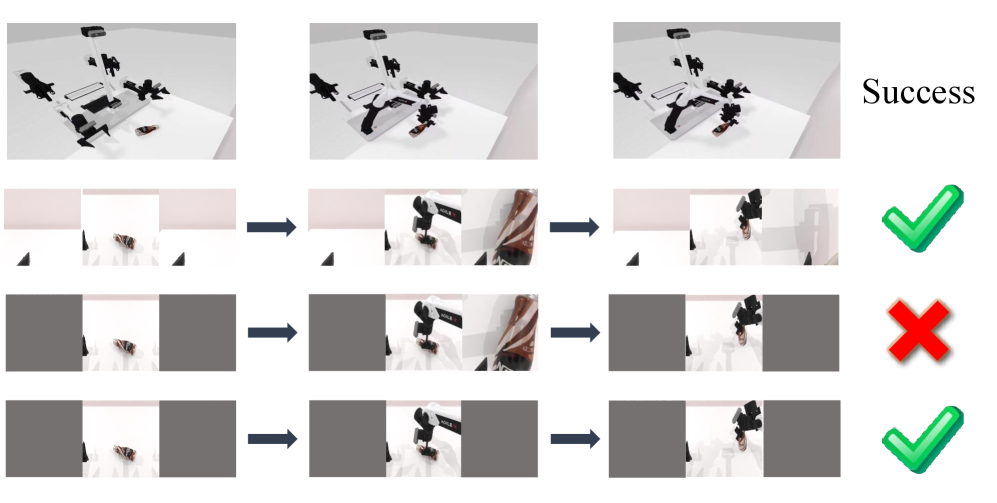
📊 实验亮点
BFA++在RoboTwin基准测试和真实机器人任务中均取得了显著的性能提升。在π0和RDT模型上,BFA++分别提高了约10%的操作成功率,并实现了1.8倍和1.5倍的推理加速。这些结果表明,BFA++是一种有效的VLA模型加速方法,能够显著提高机器人系统的性能。
🎯 应用场景
BFA++在机器人操作领域具有广泛的应用前景,尤其是在需要多视角视觉输入的复杂任务中,如装配、抓取、导航等。该方法可以显著提高机器人系统的实时性和效率,使其能够更好地适应动态环境和复杂任务。此外,BFA++的思想也可以推广到其他多模态任务中,如视频理解、图像描述等,具有重要的研究价值。
📄 摘要(原文)
Vision-Language-Action (VLA) models have achieved significant breakthroughs by leveraging Large Vision Language Models (VLMs) to jointly interpret instructions and visual inputs. However, the substantial increase in visual tokens, particularly from multi-view inputs, poses serious challenges to real-time robotic manipulation. Existing acceleration techniques for VLMs, such as token pruning, often result in degraded performance when directly applied to VLA models, as they overlook the relationships between different views and fail to account for the dynamic and task-specific characteristics of robotic operation. To address this, we propose BFA++, a dynamic token pruning framework designed specifically for VLA models. BFA++ introduces a hierarchical pruning strategy guided by two-level importance predictors: an intra-view predictor highlights task-relevant regions within each image to suppress spatial noise, while an inter-view predictor identifies critical camera views throughout different manipulation phases to reduce cross-view redundancy. This design enables efficient token selection while preserving essential visual cues, resulting in improved computational efficiency and higher manipulation success rates. Evaluations on the RoboTwin benchmark and real-world robotic tasks demonstrate that BFA++ consistently outperforms existing methods. BFA++ improves the success rate by about 10% on both the π0 and RDT models, achieving speedup of 1.8X and 1.5X, respectively. Our results highlight that context-sensitive and task-aware token pruning serves as a more effective strategy than full visual processing, enabling faster inference and improved manipulation accuracy in real-world robotic systems.