NovaPlan: Zero-Shot Long-Horizon Manipulation via Closed-Loop Video Language Planning
作者: Jiahui Fu, Junyu Nan, Lingfeng Sun, Hongyu Li, Jianing Qian, Jennifer L. Barry, Kris Kitani, George Konidaris
分类: cs.RO, cs.AI, cs.CV
发布日期: 2026-02-23
备注: 25 pages, 15 figures. Project webpage: https://nova-plan.github.io/
💡 一句话要点
NovaPlan:基于闭环视频语言规划的零样本长时程操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 长时程操作 视觉语言模型 机器人控制 零样本学习 闭环规划 运动学先验 任务分解
📋 核心要点
- 现有方法在长时程机器人操作任务中,缺乏将高层语义推理与底层物理交互有效结合的能力,导致泛化性差。
- NovaPlan通过闭环视觉语言模型和视频规划,结合几何约束的机器人执行,实现了零样本长时程操作。
- 实验表明,NovaPlan在复杂组装任务和错误恢复方面表现出色,无需任何预训练或演示数据。
📝 摘要(中文)
解决长时程任务需要机器人将高层次的语义推理与低层次的物理交互相结合。虽然视觉语言模型(VLMs)和视频生成模型可以分解任务并想象结果,但它们通常缺乏真实世界执行所需的物理基础。我们提出了NovaPlan,一个分层框架,它统一了闭环VLM和视频规划与几何基础的机器人执行,用于零样本长时程操作。在高层次上,VLM规划器将任务分解为子目标,并在闭环中监控机器人执行,使系统能够通过自主重新规划从单步失败中恢复。为了计算低层次的机器人动作,我们从生成的视频中提取并利用任务相关的对象关键点和人类手部姿势作为运动学先验,并采用切换机制来选择更好的一个作为机器人动作的参考,即使在严重遮挡或深度不准确的情况下也能保持稳定的执行。我们在三个长时程任务和功能操作基准(FMB)上证明了NovaPlan的有效性。我们的结果表明,NovaPlan可以执行复杂的组装任务,并表现出灵巧的错误恢复行为,而无需任何先前的演示或训练。
🔬 方法详解
问题定义:论文旨在解决长时程机器人操作任务中,视觉语言模型缺乏物理基础,难以直接应用于真实世界的问题。现有方法通常需要大量的训练数据或人工设计的策略,泛化能力有限,难以应对复杂环境和任务变化。
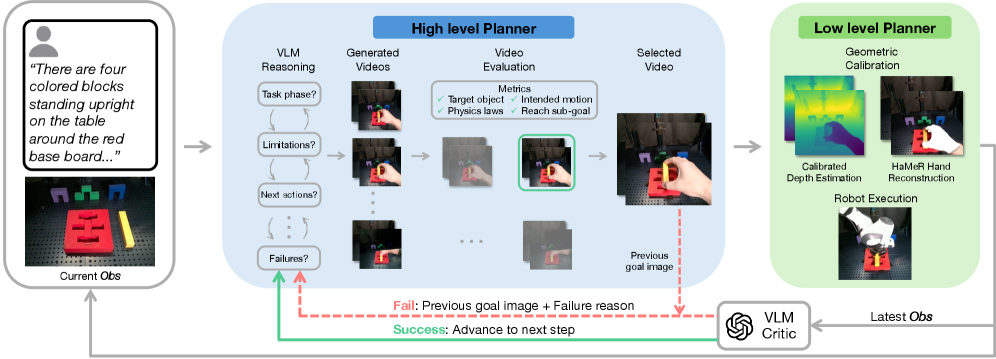
核心思路:NovaPlan的核心思路是将高层次的语义规划(由视觉语言模型实现)与低层次的物理执行(由几何约束的机器人控制实现)相结合。通过闭环反馈,系统可以监控执行过程,并在出现错误时进行自主重新规划,从而提高鲁棒性和泛化能力。
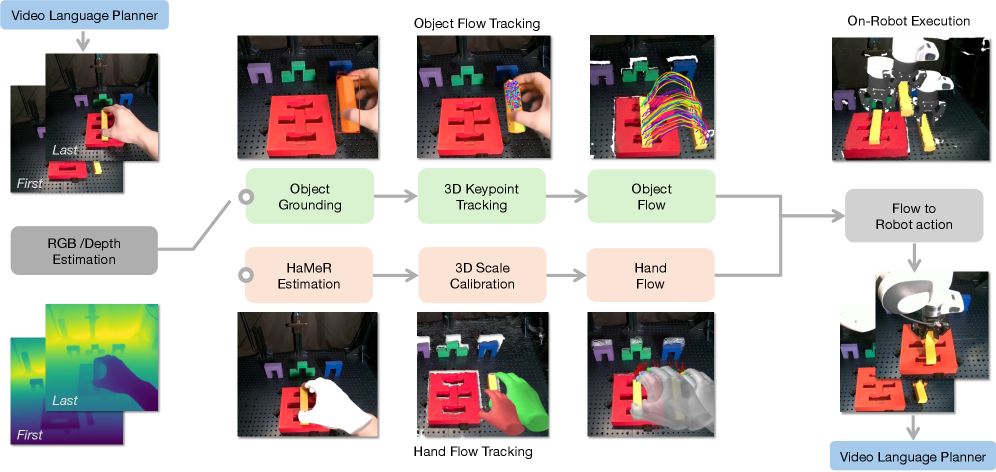
技术框架:NovaPlan的整体框架是一个分层结构。在高层,视觉语言模型(VLM)作为规划器,将长时程任务分解为一系列子目标,并监控机器人执行情况。在低层,系统从生成的视频中提取对象关键点和人类手部姿势作为运动学先验,用于计算机器人动作。一个切换机制用于选择更可靠的先验信息,以应对遮挡或深度误差。
关键创新:NovaPlan的关键创新在于将视觉语言模型的语义理解能力与几何约束的机器人控制相结合,实现了零样本的长时程操作。通过闭环反馈和自主重新规划,系统能够有效地处理执行过程中的不确定性和错误。
关键设计:论文的关键设计包括:1) 使用视觉语言模型进行任务分解和监控;2) 从生成的视频中提取对象关键点和手部姿势作为运动学先验;3) 设计切换机制,根据可靠性选择合适的先验信息;4) 采用几何约束的机器人控制方法,确保执行的稳定性和准确性。具体的参数设置、损失函数和网络结构等细节在论文中进行了详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
NovaPlan在三个长时程任务和功能操作基准(FMB)上进行了评估,结果表明,该方法能够成功执行复杂的组装任务,并展现出强大的错误恢复能力。值得注意的是,NovaPlan无需任何预训练或演示数据,实现了零样本学习,这大大降低了部署成本和难度。具体的性能指标和对比基线数据在论文中进行了详细展示(未知)。
🎯 应用场景
NovaPlan具有广泛的应用前景,例如智能制造、家庭服务机器人、医疗辅助机器人等领域。它可以用于执行复杂的装配任务、物品整理任务以及其他需要长期规划和精细操作的任务。该研究有望推动机器人技术的进一步发展,使机器人能够更好地适应复杂多变的环境,并为人类提供更智能、更便捷的服务。
📄 摘要(原文)
Solving long-horizon tasks requires robots to integrate high-level semantic reasoning with low-level physical interaction. While vision-language models (VLMs) and video generation models can decompose tasks and imagine outcomes, they often lack the physical grounding necessary for real-world execution. We introduce NovaPlan, a hierarchical framework that unifies closed-loop VLM and video planning with geometrically grounded robot execution for zero-shot long-horizon manipulation. At the high level, a VLM planner decomposes tasks into sub-goals and monitors robot execution in a closed loop, enabling the system to recover from single-step failures through autonomous re-planning. To compute low-level robot actions, we extract and utilize both task-relevant object keypoints and human hand poses as kinematic priors from the generated videos, and employ a switching mechanism to choose the better one as a reference for robot actions, maintaining stable execution even under heavy occlusion or depth inaccuracy. We demonstrate the effectiveness of NovaPlan on three long-horizon tasks and the Functional Manipulation Benchmark (FMB). Our results show that NovaPlan can perform complex assembly tasks and exhibit dexterous error recovery behaviors without any prior demonstrations or training. Project page: https://nova-plan.github.io/