AdaWorldPolicy: World-Model-Driven Diffusion Policy with Online Adaptive Learning for Robotic Manipulation
作者: Ge Yuan, Qiyuan Qiao, Jing Zhang, Dong Xu
分类: cs.RO, cs.AI
发布日期: 2026-02-23
备注: Homepage: https://AdaWorldPolicy.github.io
💡 一句话要点
AdaWorldPolicy:基于世界模型的自适应扩散策略,用于机器人操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 世界模型 扩散策略 在线学习 自适应控制 力/力矩反馈 动态环境
📋 核心要点
- 现有机器人操作策略难以有效预测物理结果并适应真实环境中的动态变化。
- AdaWorldPolicy利用世界模型提供监督信号,结合在线自适应学习和力/力矩反馈,提升动态环境下的操作能力。
- 实验表明,AdaWorldPolicy在模拟和真实机器人任务中均取得了领先性能,并能适应超出分布的场景。
📝 摘要(中文)
本文提出了一种统一的框架,即基于世界模型的自适应扩散策略(AdaWorldPolicy),旨在增强动态条件下的机器人操作能力,并最大限度地减少人工干预。核心思想是,世界模型提供强大的监督信号,从而能够在动态环境中进行在线自适应学习,并可以通过力/力矩反馈来缓解动态力的变化。AdaWorldPolicy集成了世界模型、动作专家和力预测器,所有这些都实现为互连的Flow Matching Diffusion Transformers (DiT)。它们通过多模态自注意力层互连,从而实现深度特征交换以进行联合学习,同时保留其独特的模块化特性。此外,还提出了一种新颖的在线自适应学习(AdaOL)策略,该策略在动作生成模式和未来想象模式之间动态切换,以驱动所有三个模块的反应式更新。这创建了一个强大的闭环机制,可以适应视觉和物理领域的变化,且开销最小。在模拟和真实机器人基准测试中,AdaWorldPolicy均实现了最先进的性能,并具有动态适应超出分布场景的能力。
🔬 方法详解
问题定义:现有的机器人操作策略在动态环境中面临挑战,难以准确预测物理交互结果,并且对真实世界的领域偏移适应性较差。尤其是在需要与环境进行复杂物理交互的任务中,如何有效地利用数据进行策略学习,并快速适应新的环境变化是一个关键问题。
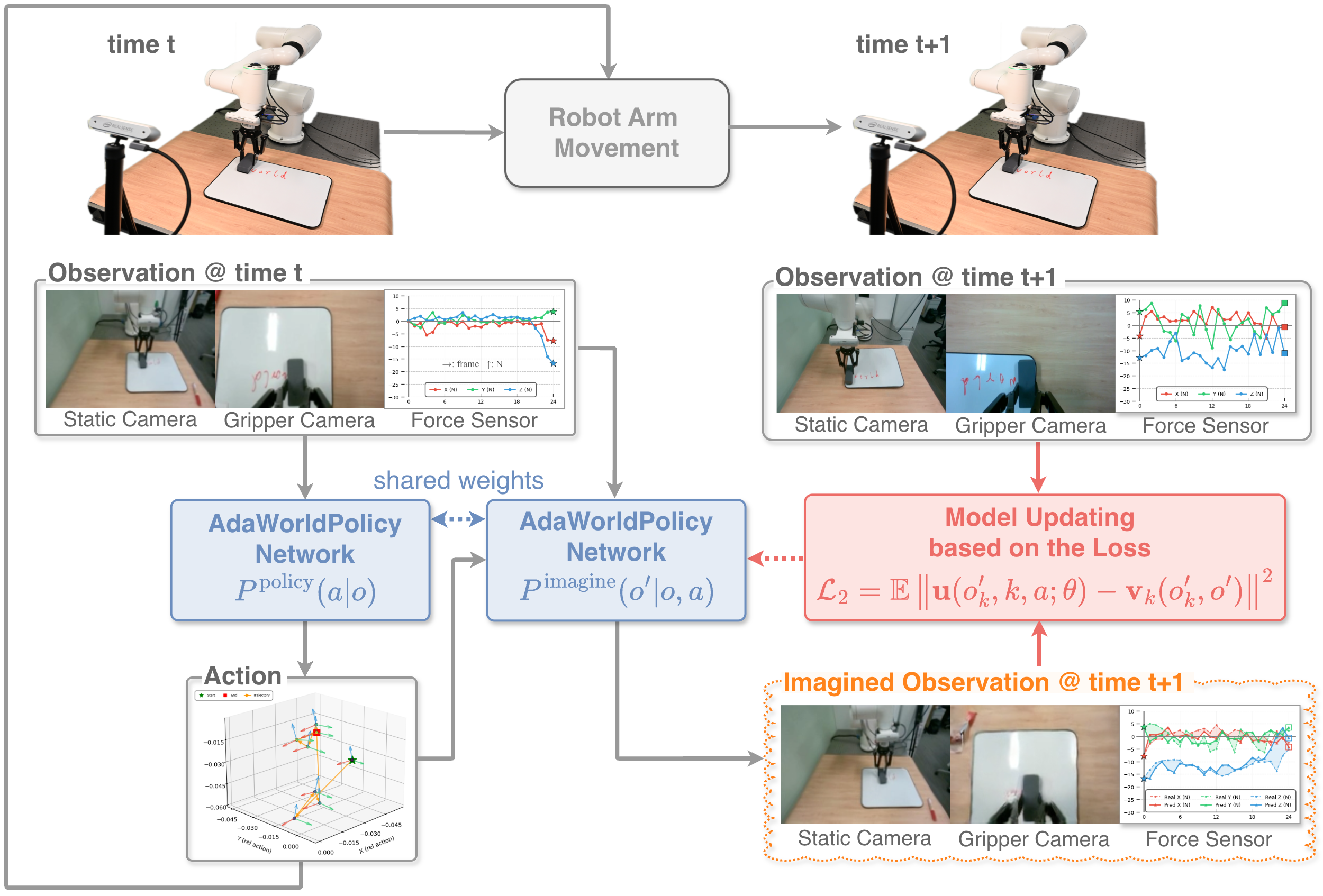
核心思路:AdaWorldPolicy的核心思路是利用世界模型来提供丰富的监督信号,从而实现策略的在线自适应学习。通过世界模型,策略可以预测未来的状态,并根据预测结果进行调整,从而更好地适应动态环境。同时,结合力/力矩反馈,可以进一步提高策略的鲁棒性。
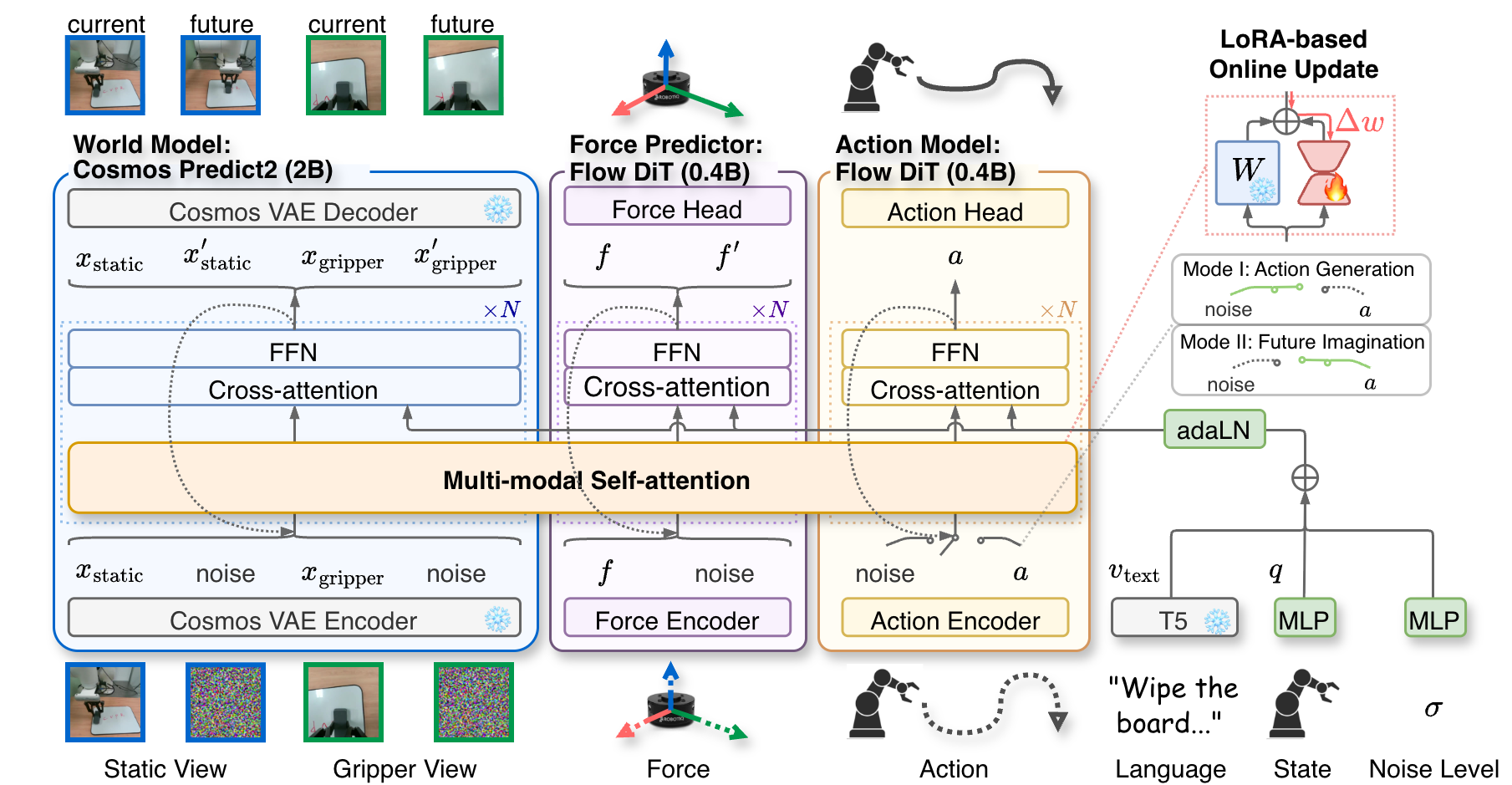
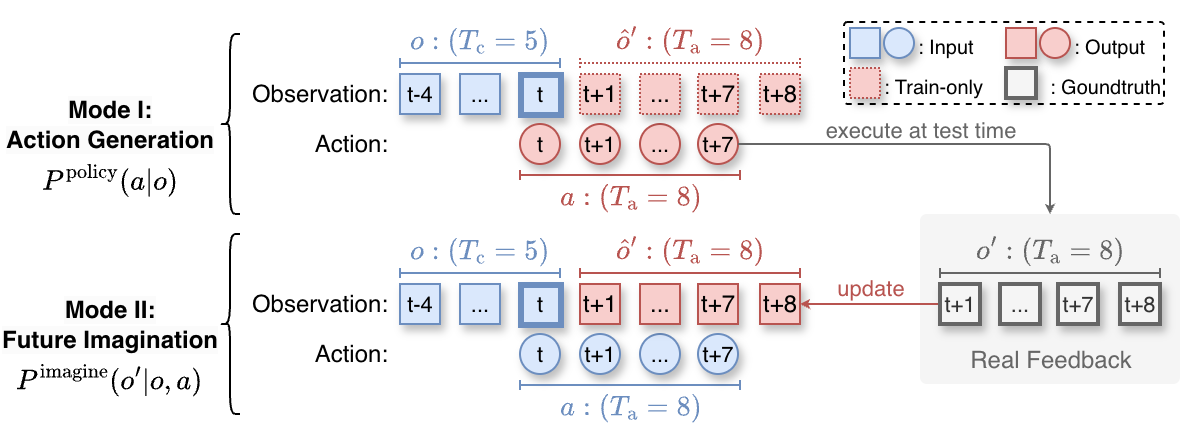
技术框架:AdaWorldPolicy包含三个主要模块:世界模型、动作专家和力预测器。这三个模块都基于Flow Matching Diffusion Transformers (DiT)实现,并通过多模态自注意力层进行连接,实现深度特征的交换和联合学习。在线自适应学习(AdaOL)策略则负责在动作生成模式和未来想象模式之间动态切换,驱动三个模块的更新。整体流程是一个闭环控制系统,能够根据环境反馈不断调整策略。
关键创新:该论文的关键创新在于将世界模型、扩散策略和在线自适应学习相结合,构建了一个统一的框架。通过世界模型提供监督信号,实现了策略的在线自适应学习,从而提高了策略在动态环境中的适应性。此外,AdaOL策略的动态切换机制也提高了学习效率。
关键设计:世界模型、动作专家和力预测器均采用Flow Matching Diffusion Transformers (DiT)架构,利用其强大的生成能力和建模能力。多模态自注意力层用于融合来自不同模块的信息。AdaOL策略通过动态调整动作生成模式和未来想象模式的比例,平衡了探索和利用。具体的损失函数设计和参数设置在论文中有详细描述,但摘要中未提及具体细节。
🖼️ 关键图片
📊 实验亮点
AdaWorldPolicy在模拟和真实机器人基准测试中均取得了最先进的性能。具体而言,该方法在动态适应超出分布场景的能力方面表现突出,表明其具有很强的泛化能力。论文中提供了与现有方法的具体性能对比数据,但摘要中未提及具体的数值提升。
🎯 应用场景
AdaWorldPolicy在机器人操作领域具有广泛的应用前景,例如自动化装配、物流分拣、医疗手术等。该方法能够提高机器人在复杂动态环境中的操作能力,减少人工干预,并降低部署成本。未来,该方法可以进一步扩展到其他机器人任务,如导航、抓取等,并与其他感知技术相结合,实现更智能化的机器人系统。
📄 摘要(原文)
Effective robotic manipulation requires policies that can anticipate physical outcomes and adapt to real-world environments. Effective robotic manipulation requires policies that can anticipate physical outcomes and adapt to real-world environments. In this work, we introduce a unified framework, World-Model-Driven Diffusion Policy with Online Adaptive Learning (AdaWorldPolicy) to enhance robotic manipulation under dynamic conditions with minimal human involvement. Our core insight is that world models provide strong supervision signals, enabling online adaptive learning in dynamic environments, which can be complemented by force-torque feedback to mitigate dynamic force shifts. Our AdaWorldPolicy integrates a world model, an action expert, and a force predictor-all implemented as interconnected Flow Matching Diffusion Transformers (DiT). They are interconnected via the multi-modal self-attention layers, enabling deep feature exchange for joint learning while preserving their distinct modularity characteristics. We further propose a novel Online Adaptive Learning (AdaOL) strategy that dynamically switches between an Action Generation mode and a Future Imagination mode to drive reactive updates across all three modules. This creates a powerful closed-loop mechanism that adapts to both visual and physical domain shifts with minimal overhead. Across a suite of simulated and real-robot benchmarks, our AdaWorldPolicy achieves state-of-the-art performance, with dynamical adaptive capacity to out-of-distribution scenarios.