Towards Dexterous Embodied Manipulation via Deep Multi-Sensory Fusion and Sparse Expert Scaling
作者: Yirui Sun, Guangyu Zhuge, Keliang Liu, Jie Gu, Zhihao xia, Qionglin Ren, Chunxu tian, Zhongxue Ga
分类: cs.RO
发布日期: 2026-02-23
💡 一句话要点
DeMUSE:融合多模态信息与稀疏专家模型,实现灵巧的具身操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身操作 多模态融合 稀疏混合专家 扩散Transformer 力觉反馈
📋 核心要点
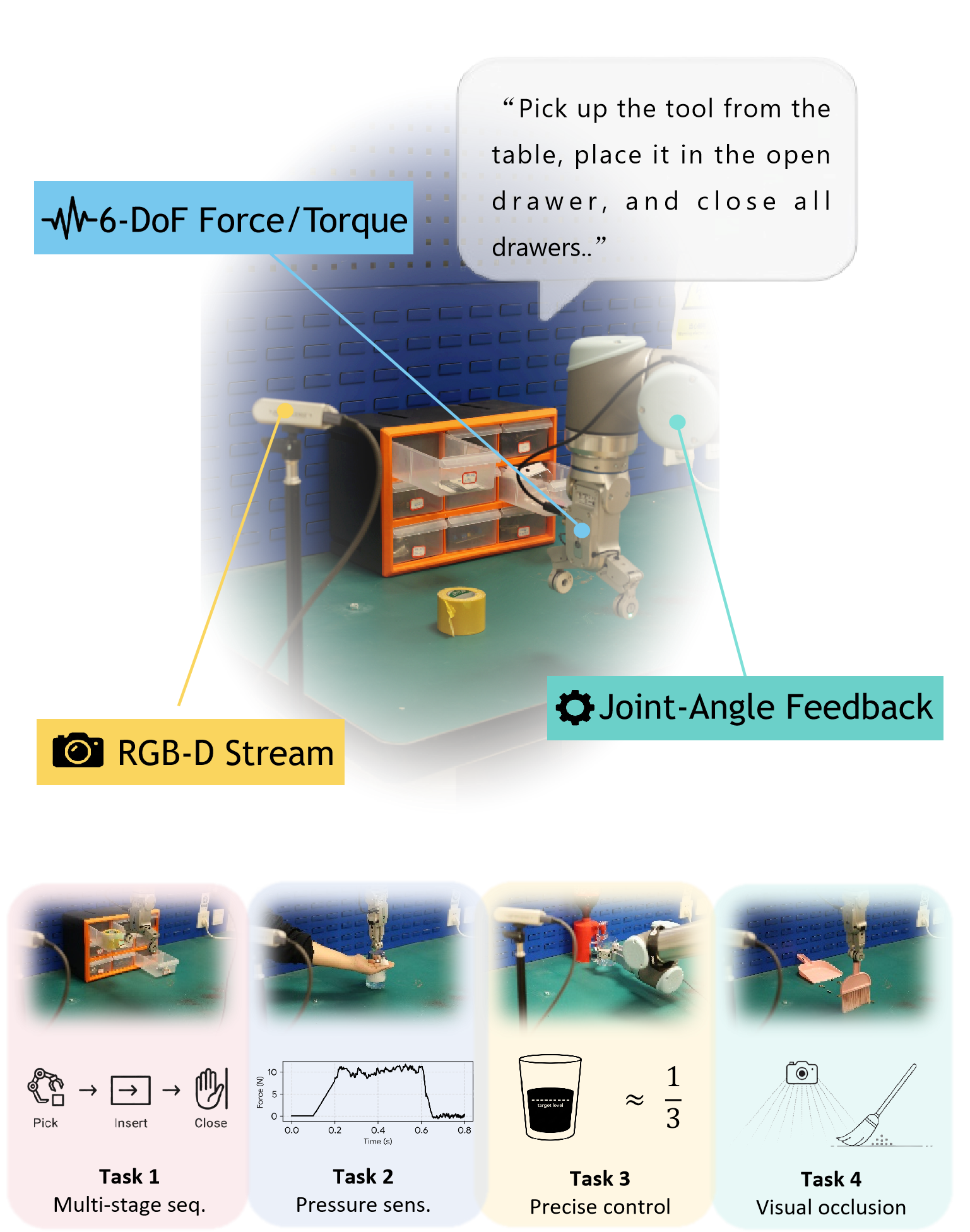
- 现有基于视觉的具身操作方法忽略了力反馈和几何反馈,限制了复杂任务的性能。
- DeMUSE框架通过扩散Transformer融合RGB、深度和力觉信息,并使用AdaMN进行模态特征校准。
- DeMUSE采用稀疏混合专家模型提升模型容量,并通过联合去噪目标保证物理一致性,在真实世界任务中表现出色。
📝 摘要(中文)
本文提出了一种名为DeMUSE的深度多模态统一稀疏专家框架,旨在实现灵巧的具身操作。该框架利用扩散Transformer将RGB图像、深度信息和六轴力传感器数据整合为统一的序列化流。采用自适应模态特定归一化(AdaMN)来重新校准模态感知特征,缓解表征不平衡并协调多传感器信号的异构分布。为了促进高效扩展,该架构利用具有共享专家的稀疏混合专家(MoE)模型,增加模型容量以学习物理先验,同时保持实时控制所需的低推理延迟。联合去噪目标同步合成环境演化和动作序列,以确保物理一致性。DeMUSE在模拟和真实世界试验中分别实现了83.2%和72.5%的成功率,展示了最先进的性能,验证了深度多传感器融合对于复杂物理交互的必要性。
🔬 方法详解
问题定义:现有具身操作方法主要依赖视觉信息,忽略了力觉和几何信息的关键作用,导致在复杂物理交互任务中表现不佳。这些方法难以有效整合异构多模态数据,并且模型容量有限,难以学习复杂的物理先验知识。
核心思路:DeMUSE的核心思路是深度融合多模态传感器数据(RGB、深度、力觉),并利用稀疏混合专家模型来扩展模型容量,从而更好地学习物理世界的复杂性。通过自适应模态特定归一化(AdaMN)来解决多模态数据分布差异的问题,并通过联合去噪目标来保证动作序列的物理一致性。
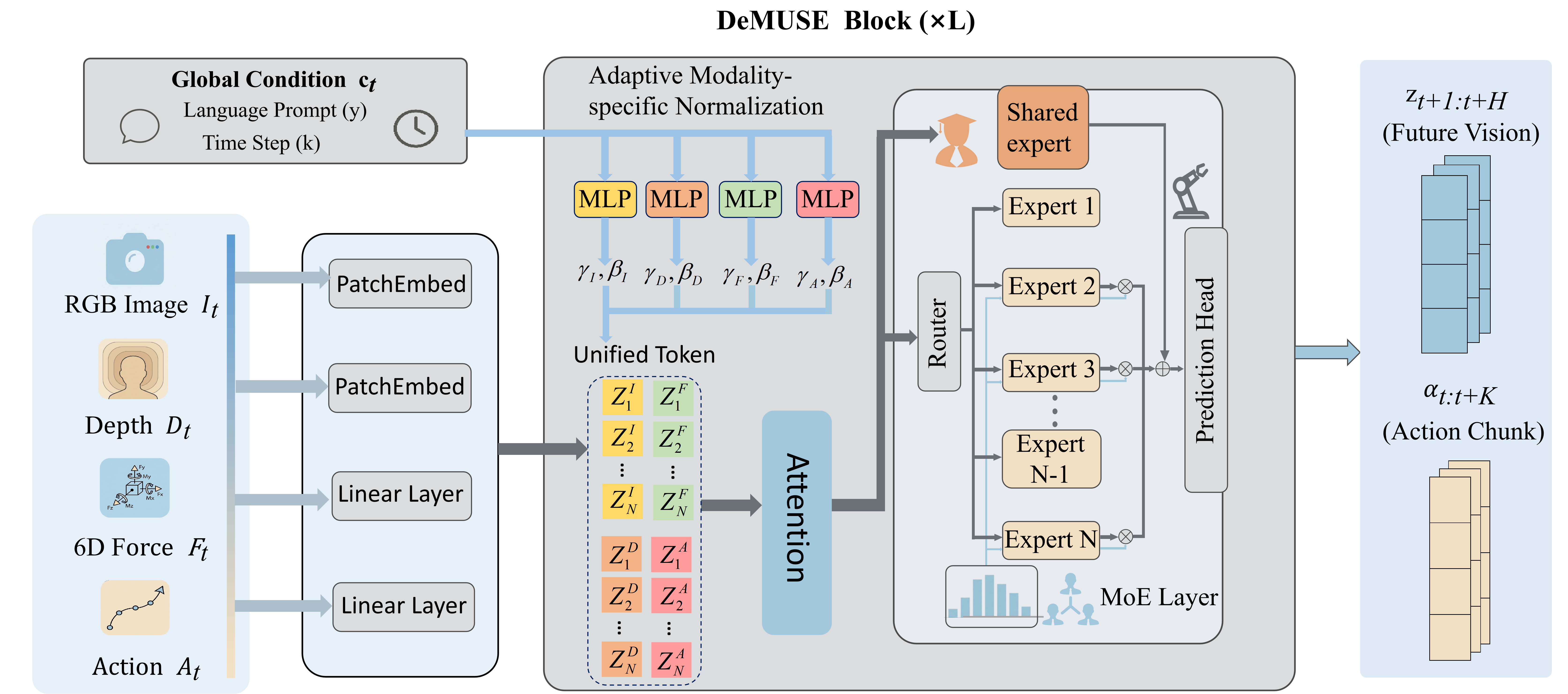
技术框架:DeMUSE框架主要包含以下几个模块:1) 多模态数据输入模块,接收RGB图像、深度信息和六轴力传感器数据;2) 扩散Transformer编码器,将多模态数据编码为统一的序列化特征;3) 自适应模态特定归一化(AdaMN)模块,用于校准模态感知特征;4) 稀疏混合专家(MoE)模型,用于扩展模型容量;5) 扩散Transformer解码器,生成动作序列;6) 联合去噪目标,用于保证物理一致性。
关键创新:DeMUSE的关键创新在于:1) 深度融合多模态传感器数据,充分利用视觉、深度和力觉信息;2) 提出自适应模态特定归一化(AdaMN)方法,有效缓解多模态数据分布差异;3) 采用稀疏混合专家(MoE)模型,在不显著增加推理延迟的情况下,扩展模型容量,学习更复杂的物理先验知识;4) 提出联合去噪目标,保证动作序列的物理一致性。
关键设计:AdaMN模块使用可学习的仿射变换参数对每个模态的特征进行归一化,这些参数根据模态的统计信息自适应调整。稀疏混合专家模型使用门控网络选择激活哪些专家,从而实现高效的模型扩展。联合去噪目标包括环境演化和动作序列的去噪损失,鼓励模型生成物理上合理的动作序列。
🖼️ 关键图片
📊 实验亮点
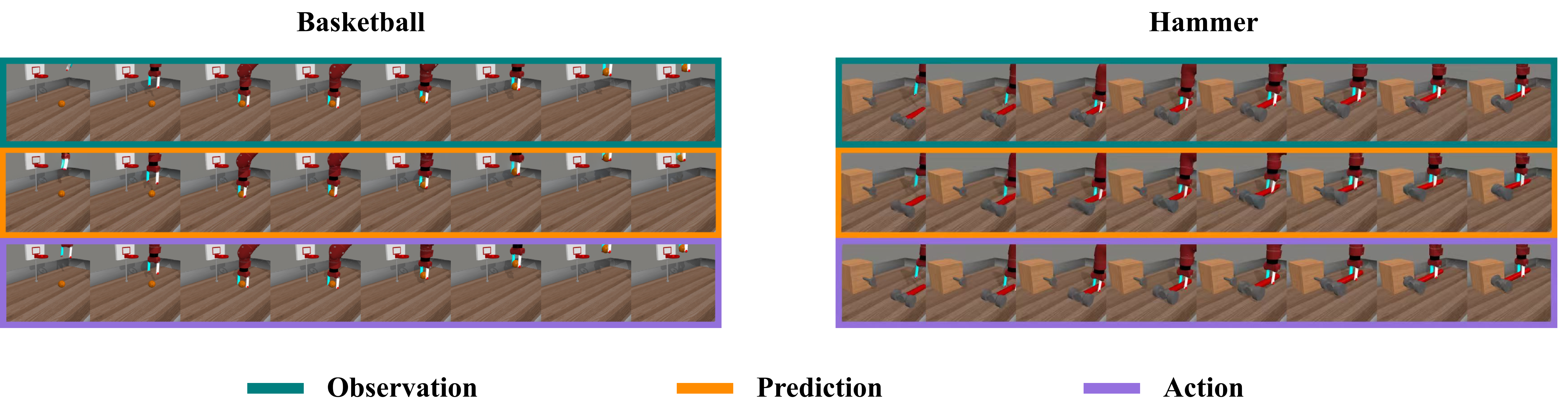
DeMUSE在模拟和真实世界试验中分别实现了83.2%和72.5%的成功率,显著优于现有方法。实验结果表明,深度多传感器融合和稀疏混合专家模型能够有效提升机器人的操作性能。特别是在真实世界试验中的优异表现,验证了DeMUSE框架的实用性和鲁棒性。
🎯 应用场景
DeMUSE框架可应用于各种需要灵巧操作的机器人任务,例如:工业自动化中的精密装配、医疗机器人中的微创手术、家庭服务机器人中的物品整理等。通过融合多模态信息和扩展模型容量,DeMUSE能够提升机器人在复杂环境中的操作能力,使其能够更好地适应真实世界的挑战,具有广阔的应用前景。
📄 摘要(原文)
Realizing dexterous embodied manipulation necessitates the deep integration of heterogeneous multimodal sensory inputs. However, current vision-centric paradigms often overlook the critical force and geometric feedback essential for complex tasks. This paper presents DeMUSE, a Deep Multimodal Unified Sparse Experts framework leveraging a Diffusion Transformer to integrate RGB, depth, and 6-axis force into a unified serialized stream. Adaptive Modality-specific Normalization (AdaMN) is employed to recalibrate modality-aware features, mitigating representation imbalance and harmonizing the heterogeneous distributions of multi-sensory signals. To facilitate efficient scaling, the architecture utilizes a Sparse Mixture-of-Experts (MoE) with shared experts, increasing model capacity for physical priors while maintaining the low inference latency required for real-time control. A Joint denoising objective synchronously synthesizes environmental evolution and action sequences to ensure physical consistency. Achieving success rates of 83.2% and 72.5% in simulation and real-world trials, DeMUSE demonstrates state-of-the-art performance, validating the necessity of deep multi-sensory integration for complex physical interactions.