Seeing Farther and Smarter: Value-Guided Multi-Path Reflection for VLM Policy Optimization
作者: Yanting Yang, Shenyuan Gao, Qingwen Bu, Li Chen, Dimitris N. Metaxas
分类: cs.RO, cs.CV, cs.LG
发布日期: 2026-02-22
备注: ICRA 2026
💡 一句话要点
提出值引导的多路径反射方法,优化VLM在复杂机器人操作任务中的策略。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 视觉语言模型 机器人操作 反射规划 多路径探索 状态值评估 集束搜索 策略优化
📋 核心要点
- 现有基于反射规划的VLM方法在机器人操作任务中,存在状态值学习效率低、仅考虑单一未来路径以及推理延迟高等问题。
- 论文提出一种值引导的多路径反射框架,解耦状态评估与动作生成,显式建模动作计划的优势,并使用集束搜索探索多个未来路径。
- 实验结果表明,该方法在多阶段机器人操作任务中,成功率提升24.6%,推理时间减少56.5%,显著优于现有方法。
📝 摘要(中文)
解决复杂、长时程机器人操作任务需要对物理交互的深刻理解、对长期后果的推理以及精确的高级规划。视觉-语言模型(VLM)为此提供了一个通用的感知-推理-行动框架。然而,先前使用反射规划来指导VLM纠正动作的方法存在显著局限性。这些方法依赖于从嘈杂的预测中低效且常常不准确地隐式学习状态值,仅评估单一的贪婪未来,并遭受显著的推理延迟。为了解决这些限制,我们提出了一种新颖的测试时计算框架,该框架将状态评估与动作生成分离,为鲁棒决策提供更直接和细粒度的监督信号。我们的方法显式地建模了动作计划的优势,通过其到目标的距离减少来量化,并使用可扩展的评论器来估计。为了解决单轨迹评估的随机性,我们采用集束搜索来探索多个未来路径,并在解码期间聚合它们以建模其预期的长期回报,从而实现更鲁棒的动作生成。此外,我们引入了一种轻量级的、基于置信度的触发器,允许在直接预测可靠时提前退出,仅在必要时调用反射。在各种未见过的多阶段机器人操作任务上的大量实验表明,成功率比最先进的基线提高了24.6%,同时显著减少了56.5%的推理时间。
🔬 方法详解
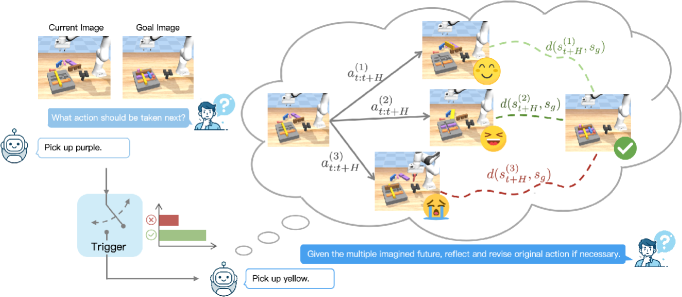
问题定义:现有基于视觉-语言模型(VLM)的机器人操作方法,特别是依赖反射规划的方法,在处理复杂、长时程任务时面临挑战。这些方法通常通过隐式学习状态值来指导动作纠正,但由于预测的噪声和仅考虑单一贪婪未来,导致学习效率低下且不准确。此外,推理延迟也是一个显著的问题,限制了其在实际应用中的可行性。
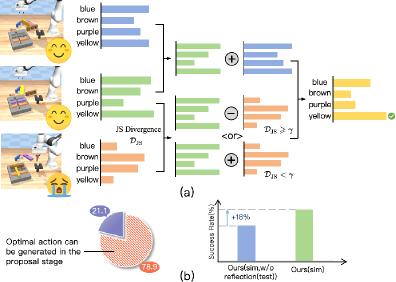
核心思路:论文的核心思路是将状态评估与动作生成解耦,从而为决策提供更直接和细粒度的监督信号。通过显式建模动作计划的优势(即减少到目标的距离),并使用可扩展的评论器进行估计,可以更准确地评估动作的价值。此外,采用集束搜索探索多个未来路径,并聚合它们的长期回报,可以提高动作生成的鲁棒性。
技术框架:该框架包含以下主要模块:1) VLM动作生成器:负责根据当前状态生成初始动作序列。2) 状态值评估器(Critic):用于评估每个状态的价值,即距离目标的远近。3) 多路径探索模块:使用集束搜索探索多个可能的未来轨迹。4) 动作选择模块:根据状态值评估和多路径探索的结果,选择最优的动作序列。5) 置信度触发器:当VLM的预测足够可靠时,允许提前退出反射过程,减少计算量。
关键创新:该方法最重要的创新点在于将状态评估与动作生成解耦,并显式建模动作计划的优势。这与以往依赖隐式学习状态值的方法不同,提供了更直接和细粒度的监督信号。此外,多路径探索和置信度触发器的引入进一步提高了方法的鲁棒性和效率。
关键设计:论文使用可扩展的评论器来估计状态值,具体实现细节未知。集束搜索的宽度(beam size)是一个关键参数,需要在探索的广度和计算复杂度之间进行权衡。置信度触发器的阈值也需要根据具体任务进行调整,以平衡准确性和效率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在各种未见过的多阶段机器人操作任务上,成功率比最先进的基线提高了24.6%,同时显著减少了56.5%的推理时间。这些结果表明,该方法在提高机器人操作性能和效率方面具有显著优势。
🎯 应用场景
该研究成果可广泛应用于各种复杂机器人操作任务,例如自动化装配、物流分拣、家庭服务机器人等。通过提高机器人的决策能力和鲁棒性,可以实现更高效、更可靠的自动化操作,降低人工成本,提高生产效率。未来,该方法有望扩展到更广泛的机器人应用领域,例如自动驾驶、医疗机器人等。
📄 摘要(原文)
Solving complex, long-horizon robotic manipulation tasks requires a deep understanding of physical interactions, reasoning about their long-term consequences, and precise high-level planning. Vision-Language Models (VLMs) offer a general perceive-reason-act framework for this goal. However, previous approaches using reflective planning to guide VLMs in correcting actions encounter significant limitations. These methods rely on inefficient and often inaccurate implicit learning of state-values from noisy foresight predictions, evaluate only a single greedy future, and suffer from substantial inference latency. To address these limitations, we propose a novel test-time computation framework that decouples state evaluation from action generation. This provides a more direct and fine-grained supervisory signal for robust decision-making. Our method explicitly models the advantage of an action plan, quantified by its reduction in distance to the goal, and uses a scalable critic to estimate. To address the stochastic nature of single-trajectory evaluation, we employ beam search to explore multiple future paths and aggregate them during decoding to model their expected long-term returns, leading to more robust action generation. Additionally, we introduce a lightweight, confidence-based trigger that allows for early exit when direct predictions are reliable, invoking reflection only when necessary. Extensive experiments on diverse, unseen multi-stage robotic manipulation tasks demonstrate a 24.6% improvement in success rate over state-of-the-art baselines, while significantly reducing inference time by 56.5%.