TOPReward: Token Probabilities as Hidden Zero-Shot Rewards for Robotics
作者: Shirui Chen, Cole Harrison, Ying-Chun Lee, Angela Jin Yang, Zhongzheng Ren, Lillian J. Ratliff, Jiafei Duan, Dieter Fox, Ranjay Krishna
分类: cs.RO, cs.AI, cs.LG
发布日期: 2026-02-22
💡 一句话要点
TOPReward:利用Token概率作为机器人零样本奖励,提升强化学习效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人强化学习 视觉语言模型 零样本学习 奖励函数设计 任务进度估计
📋 核心要点
- 现有VLA模型在机器人强化学习中面临样本效率低和奖励稀疏的挑战,缺乏可泛化的过程奖励模型。
- TOPReward利用预训练VLM的token logits提取任务进度,避免了直接输出进度值带来的数值误差。
- 实验表明,TOPReward在多个机器人平台和任务上显著优于现有方法,并可用于成功检测和行为克隆。
📝 摘要(中文)
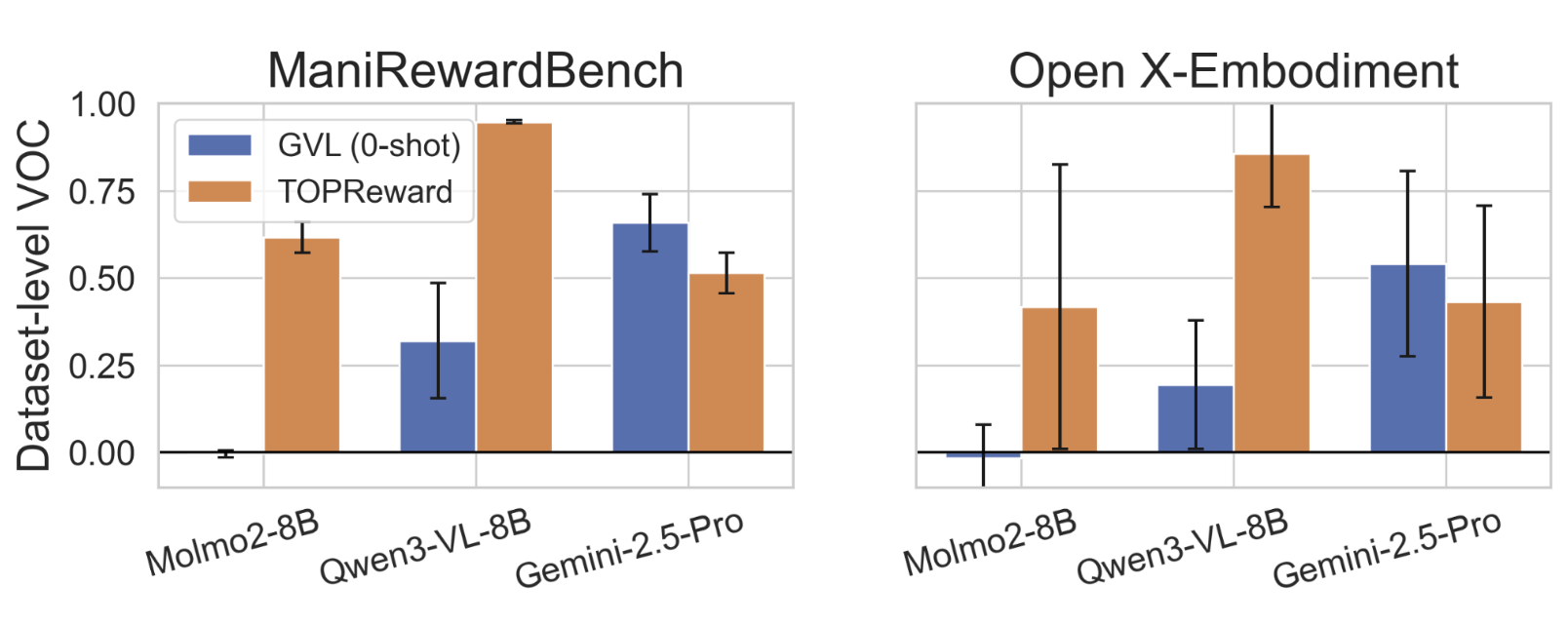
视觉-语言-动作(VLA)模型在预训练方面取得了快速进展,但其在强化学习(RL)中的应用仍然受到真实世界环境中样本效率低和奖励稀疏的限制。开发可泛化的过程奖励模型对于提供弥合这一差距所需的细粒度反馈至关重要,但现有的时间价值函数通常无法泛化到其训练领域之外。我们引入了TOPReward,这是一种新颖的、基于概率的时间价值函数,它利用预训练视频视觉-语言模型(VLM)的潜在世界知识来估计机器人任务的进度。与先前直接提示VLM输出进度值(容易出现数值错误)的方法不同,TOPReward直接从VLM的内部token logits中提取任务进度。在超过130个不同的真实世界任务和多个机器人平台(例如,Franka、YAM、SO-100/101)上的零样本评估中,TOPReward在Qwen3-VL上实现了0.947的平均价值顺序相关性(VOC),显著优于最先进的GVL基线,后者在同一开源模型上实现了接近于零的相关性。我们进一步证明,TOPReward可以作为下游应用的多功能工具,包括成功检测和奖励对齐的行为克隆。
🔬 方法详解
问题定义:论文旨在解决机器人强化学习中奖励函数设计的问题,特别是如何利用预训练的视觉-语言模型(VLM)来提供更有效、更泛化的奖励信号。现有方法,例如直接让VLM输出任务进度,容易产生数值误差,导致奖励信号不准确,难以训练机器人策略。
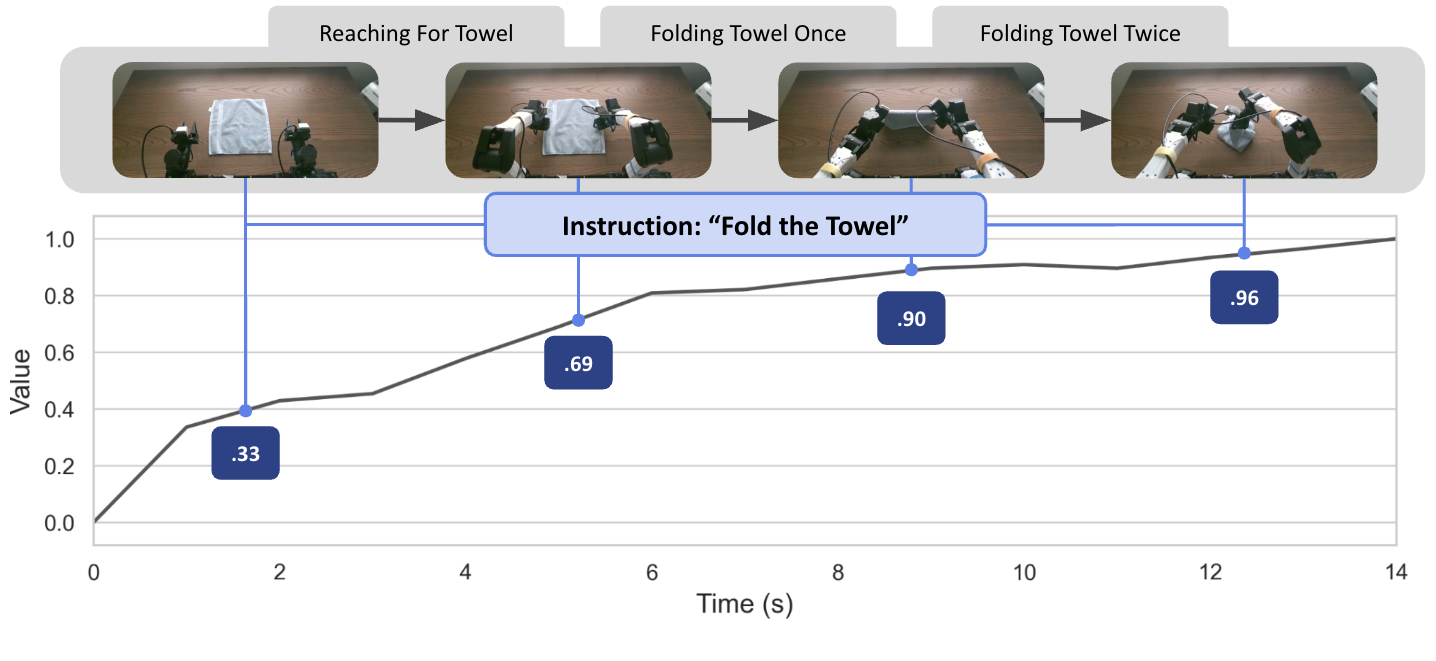
核心思路:TOPReward的核心思路是利用VLM内部的token logits来估计任务进度。作者认为,VLM在预训练过程中已经学习了丰富的世界知识,这些知识蕴含在token的概率分布中。通过分析这些概率分布,可以更准确地推断出任务的完成程度,从而生成更可靠的奖励信号。
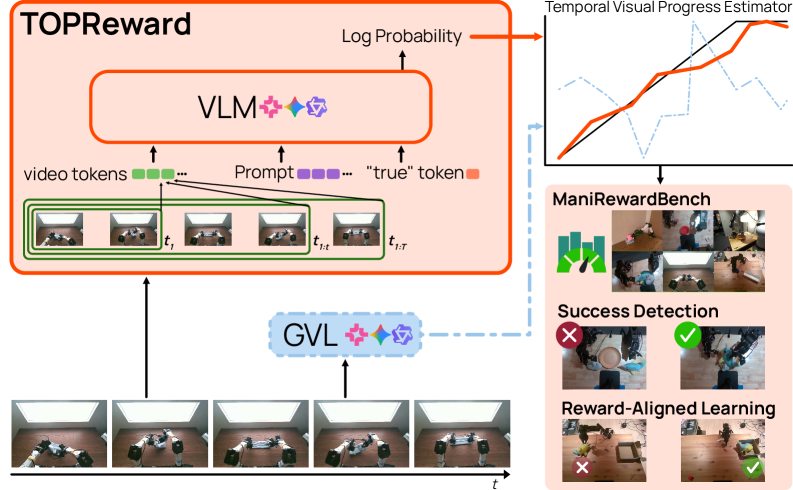
技术框架:TOPReward的整体框架包括以下几个主要步骤:1)输入视频帧序列和任务描述文本;2)使用预训练的VLM(例如Qwen3-VL)处理视频和文本,得到每个token的logits;3)根据任务描述,选择与任务相关的token;4)计算这些token的概率,并将其作为任务进度的估计;5)使用任务进度估计生成奖励信号,用于训练机器人策略。
关键创新:TOPReward最重要的创新在于它利用了VLM内部的token概率分布,而不是直接使用VLM的输出值。这种方法避免了数值误差,并且能够更好地利用VLM的预训练知识。此外,TOPReward是一种零样本方法,不需要针对特定任务进行训练,具有很强的泛化能力。
关键设计:TOPReward的关键设计包括:1)选择合适的VLM模型,例如Qwen3-VL;2)设计有效的token选择策略,以确定与任务相关的token;3)设计合适的概率计算方法,以将token概率转换为任务进度估计;4)设计合适的奖励函数,以鼓励机器人完成任务。
🖼️ 关键图片
📊 实验亮点
TOPReward在超过130个真实世界机器人任务上进行了评估,并在多个机器人平台上取得了显著的性能提升。在Qwen3-VL模型上,TOPReward实现了0.947的平均价值顺序相关性(VOC),显著优于最先进的GVL基线,后者在同一模型上实现了接近于零的相关性。这表明TOPReward能够更准确地估计任务进度,并提供更有效的奖励信号。
🎯 应用场景
TOPReward具有广泛的应用前景,可用于各种机器人任务,例如物体操作、导航和装配。它可以帮助机器人更有效地学习复杂的任务,提高机器人的自主性和适应性。此外,TOPReward还可以用于开发更智能的机器人助手,帮助人们完成各种日常任务,例如家务、医疗护理和工业生产。
📄 摘要(原文)
While Vision-Language-Action (VLA) models have seen rapid progress in pretraining, their advancement in Reinforcement Learning (RL) remains hampered by low sample efficiency and sparse rewards in real-world settings. Developing generalizable process reward models is essential for providing the fine-grained feedback necessary to bridge this gap, yet existing temporal value functions often fail to generalize beyond their training domains. We introduce TOPReward, a novel, probabilistically grounded temporal value function that leverages the latent world knowledge of pretrained video Vision-Language Models (VLMs) to estimate robotic task progress. Unlike prior methods that prompt VLMs to directly output progress values, which are prone to numerical misrepresentation, TOPReward extracts task progress directly from the VLM's internal token logits. In zero-shot evaluations across 130+ distinct real-world tasks and multiple robot platforms (e.g., Franka, YAM, SO-100/101), TOPReward achieves 0.947 mean Value-Order Correlation (VOC) on Qwen3-VL, dramatically outperforming the state-of-the-art GVL baseline which achieves near-zero correlation on the same open-source model. We further demonstrate that TOPReward serves as a versatile tool for downstream applications, including success detection and reward-aligned behavior cloning.