The Price Is Not Right: Neuro-Symbolic Methods Outperform VLAs on Structured Long-Horizon Manipulation Tasks with Significantly Lower Energy Consumption
作者: Timothy Duggan, Pierrick Lorang, Hong Lu, Matthias Scheutz
分类: cs.RO
发布日期: 2026-02-22
备注: Accepted at the 2026 IEEE International Conference on Robotics & Automation (ICRA 2026)
💡 一句话要点
神经符号方法在长时程操作任务中优于VLA,且能耗显著降低
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 神经符号推理 机器人操作 长时程规划 视觉语言动作模型 PDDL 能量效率 汉诺塔
📋 核心要点
- 现有VLA模型在结构化长时程操作任务中表现不佳,且能耗高昂,限制了其应用。
- 提出一种结合PDDL符号规划和学习型低级控制的神经符号架构,提升任务性能和能效。
- 实验表明,该神经符号模型在汉诺塔任务中显著优于VLA模型,且能耗更低。
📝 摘要(中文)
视觉-语言-动作(VLA)模型最近被认为是实现通用机器人策略的一种途径,它能够解释自然语言和视觉输入以生成操作动作。然而,它们在结构化、长时程操作任务中的有效性和效率仍不清楚。本文对一个微调后的开放权重VLA模型π0和一个神经符号架构进行了正面经验比较,该架构结合了基于PDDL的符号规划和学习到的低级控制。我们在模拟的汉诺塔操作任务的结构化变体上评估了这两种方法,同时测量了训练和执行期间的任务性能和能耗。在3块任务中,神经符号模型达到了95%的成功率,而性能最佳的VLA模型为34%。神经符号模型还推广到未见过的4块变体(78%的成功率),而两个VLA模型都未能完成任务。在训练过程中,VLA微调消耗的能量几乎比神经符号方法高两个数量级。这些结果突出了端到端基础模型方法和结构化推理架构在长时程机器人操作中的重要权衡,强调了显式符号结构在提高可靠性、数据效率和能源效率方面的作用。
🔬 方法详解
问题定义:论文旨在解决VLA模型在结构化、长时程机器人操作任务中表现不佳,且训练和推理能耗过高的问题。现有VLA模型通常需要大量数据进行训练,并且难以泛化到未见过的任务变体,同时,端到端的训练方式导致其能耗显著增加。
核心思路:论文的核心思路是将符号推理和深度学习相结合,利用符号规划器进行高层决策,并使用学习到的低级控制器执行具体动作。这种方法可以利用符号推理的结构化特性来提高任务的可靠性和泛化能力,同时降低对大量训练数据的需求。
技术框架:该神经符号架构包含两个主要模块:一个基于PDDL的符号规划器和一个学习到的低级控制器。首先,符号规划器接收任务目标和当前环境状态,生成一个高层动作序列。然后,低级控制器将这些高层动作转化为具体的机器人控制指令,驱动机器人执行动作。整个流程是分层的,高层规划负责任务分解和目标设定,低层控制负责动作执行和环境交互。
关键创新:该方法最重要的创新点在于将符号规划和深度学习有效结合,利用符号规划的结构化推理能力来指导深度学习模型的训练和推理。这种结合方式可以显著提高模型的泛化能力和数据效率,同时降低能耗。与端到端的VLA模型相比,该方法更加模块化和可解释。
关键设计:符号规划器使用PDDL语言描述任务和环境,并使用现成的规划器求解器生成动作序列。低级控制器可以使用各种深度学习模型,例如强化学习或模仿学习模型,来学习从高层动作到低层控制指令的映射。论文中具体使用的低级控制器的网络结构和训练方法未明确说明,属于未知信息。
🖼️ 关键图片
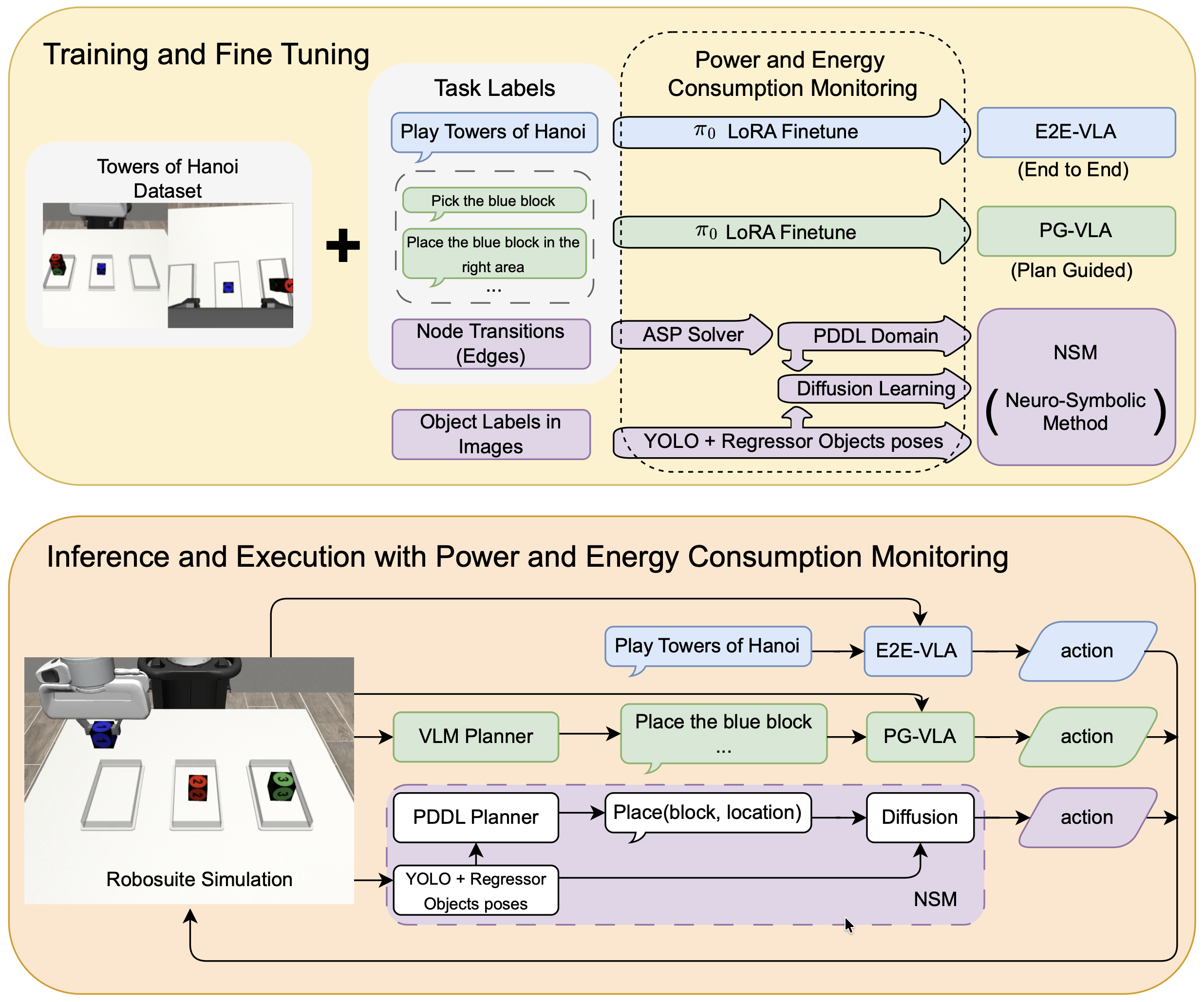

📊 实验亮点
实验结果表明,该神经符号模型在3块汉诺塔任务中达到了95%的成功率,而性能最佳的VLA模型仅为34%。此外,该神经符号模型能够泛化到未见过的4块汉诺塔任务(78%的成功率),而VLA模型则完全失败。更重要的是,VLA模型的训练能耗几乎比神经符号方法高两个数量级,突显了神经符号方法在能效方面的优势。
🎯 应用场景
该研究成果可应用于各种需要长时程规划和控制的机器人操作任务,例如自动化装配、物流分拣、家庭服务机器人等。通过结合符号推理和深度学习,可以提高机器人的自主性和适应性,使其能够更好地完成复杂任务,并降低部署和维护成本。未来,该方法有望推动机器人技术在工业和服务领域的广泛应用。
📄 摘要(原文)
Vision-Language-Action (VLA) models have recently been proposed as a pathway toward generalist robotic policies capable of interpreting natural language and visual inputs to generate manipulation actions. However, their effectiveness and efficiency on structured, long-horizon manipulation tasks remain unclear. In this work, we present a head-to-head empirical comparison between a fine-tuned open-weight VLA model π0 and a neuro-symbolic architecture that combines PDDL-based symbolic planning with learned low-level control. We evaluate both approaches on structured variants of the Towers of Hanoi manipulation task in simulation while measuring both task performance and energy consumption during training and execution. On the 3-block task, the neuro-symbolic model achieves 95% success compared to 34% for the best-performing VLA. The neuro-symbolic model also generalizes to an unseen 4-block variant (78% success), whereas both VLAs fail to complete the task. During training, VLA fine-tuning consumes nearly two orders of magnitude more energy than the neuro-symbolic approach. These results highlight important trade-offs between end-to-end foundation-model approaches and structured reasoning architectures for long-horizon robotic manipulation, emphasizing the role of explicit symbolic structure in improving reliability, data efficiency, and energy efficiency. Code and models are available at https://price-is-not-right.github.io