Human-to-Robot Interaction: Learning from Video Demonstration for Robot Imitation
作者: Thanh Nguyen Canh, Thanh-Tuan Tran, Haolan Zhang, Ziyan Gao, Nak Young Chong, Xiem HoangVan
分类: cs.RO
发布日期: 2026-02-22
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出一种模块化人机交互模仿学习框架,从视频演示中学习机器人操作技能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting)
关键词: 人机交互 模仿学习 视频理解 机器人操作 深度强化学习
📋 核心要点
- 现有方法难以从视频中提取适合机器人执行的精确指令,且端到端架构泛化性差。
- 该方法采用模块化框架,解耦视频理解和机器人模仿,提升泛化能力。
- 实验表明,该方法在动作分类和机器人操作任务上均取得了显著的性能提升。
📝 摘要(中文)
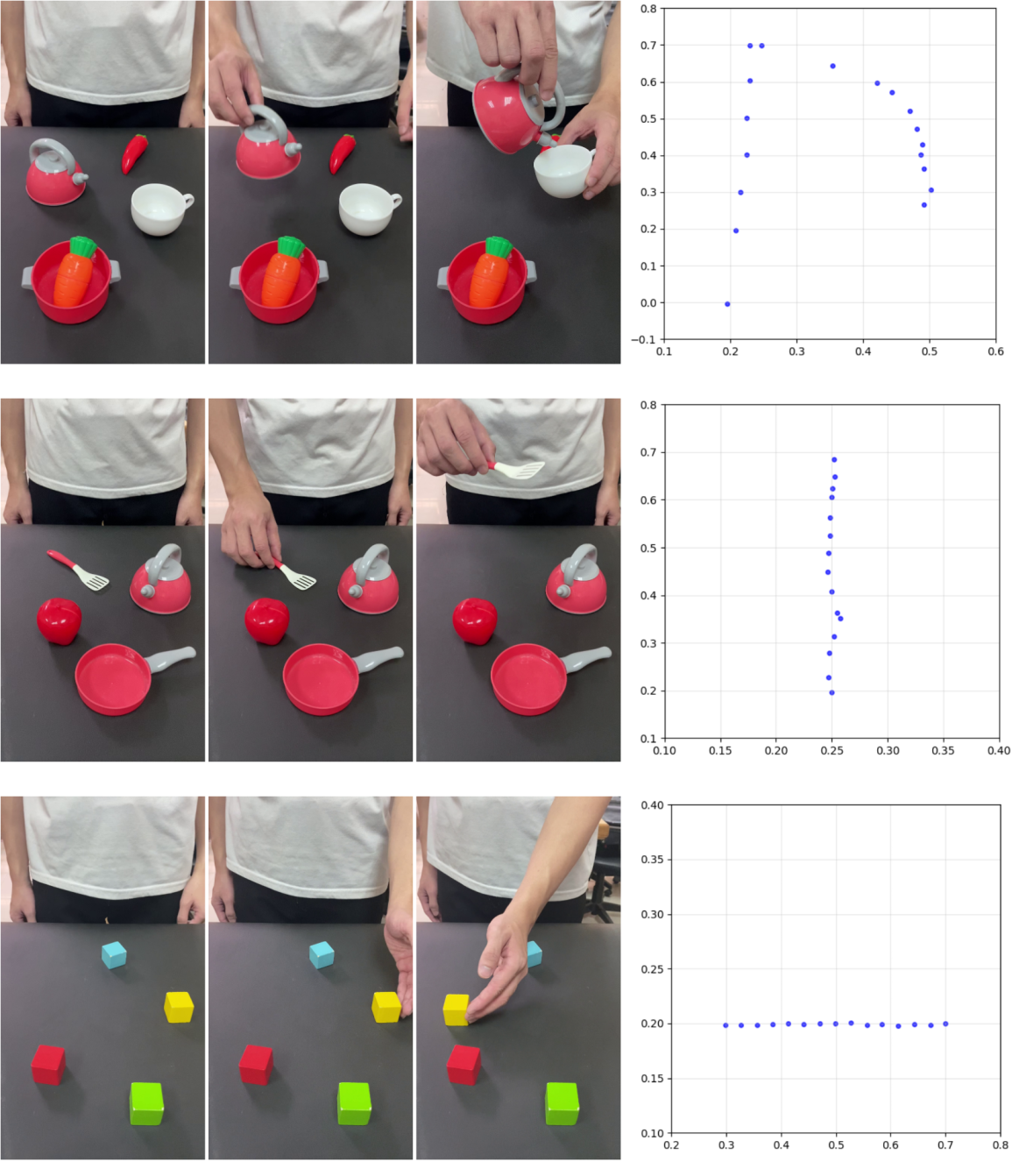
本文提出了一种新颖的“人到机器人”模仿学习流程,使机器人能够直接从非结构化视频演示中学习操作技能,灵感来源于人类通过观看和模仿进行学习的能力。现有方法直接从视频演示中提取操作指令,但面临两个关键挑战:(1) 通用视频字幕模型优先考虑全局场景特征而非任务相关对象,产生不适合精确机器人执行的描述;(2) 将视觉理解与策略学习相结合的端到端架构需要大量的配对数据集,并且难以跨对象和场景泛化。为了解决这些限制,该方法采用模块化框架,将学习过程解耦为两个不同的阶段:(1) 视频理解,结合时间移位模块 (TSM) 和视觉-语言模型 (VLM) 来提取动作并识别交互对象;(2) 机器人模仿,采用基于 TD3 的深度强化学习来执行演示的操作。在 PyBullet 模拟环境中使用 UR5e 机械臂以及在真实世界实验中使用 UF850 机械臂,针对四个基本动作(到达、拾取、移动和放置)验证了该方法。
🔬 方法详解
问题定义:论文旨在解决机器人如何直接从人类视频演示中学习操作技能的问题。现有方法,特别是端到端的方法,存在两个主要痛点:一是视频理解模型难以关注任务相关的对象,二是端到端架构需要大量数据且泛化能力弱。
核心思路:论文的核心思路是将学习过程解耦为视频理解和机器人模仿两个模块。视频理解模块负责从视频中提取动作和交互对象的信息,机器人模仿模块则利用这些信息通过强化学习来学习执行相应的操作。这种解耦的设计使得每个模块可以独立优化,从而提高整体的性能和泛化能力。
技术框架:整体框架包含两个主要模块:视频理解模块和机器人模仿模块。视频理解模块首先使用时间移位模块 (TSM) 来提取视频中的时序特征,然后结合视觉-语言模型 (VLM) 来识别动作和交互对象。机器人模仿模块则使用 TD3 (Twin Delayed Deep Deterministic Policy Gradient) 算法进行强化学习,根据视频理解模块提取的信息来学习执行相应的操作。
关键创新:该方法最重要的创新点在于其模块化的设计,将视频理解和机器人模仿解耦。这种解耦使得每个模块可以独立优化,并且可以利用现有的先进技术,例如 TSM 和 VLM,来提高视频理解的准确性。此外,使用 TD3 算法进行强化学习也提高了机器人模仿的效率和稳定性。
关键设计:在视频理解模块中,TSM 用于捕捉视频中的时序信息,VLM 用于识别动作和交互对象。在机器人模仿模块中,TD3 算法使用两个 Critic 网络来减少 Q-value 的高估,并使用目标策略平滑来提高策略的稳定性。具体的参数设置和网络结构在论文中进行了详细描述,但摘要中未提供具体数值。
🖼️ 关键图片
📊 实验亮点
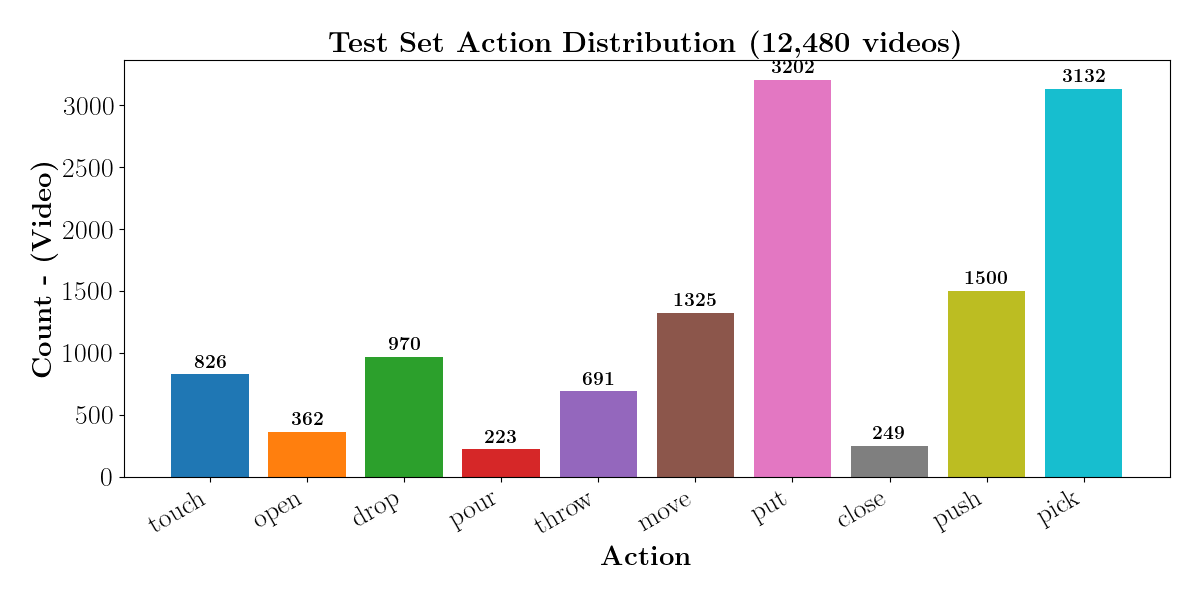
在视频理解方面,该方法在标准对象上的动作分类准确率达到 89.97%,BLEU-4 得分为 0.351,在新对象上的 BLEU-4 得分为 0.265,分别比最佳基线提高了 76.4% 和 128.4%。在机器人操作方面,该框架在所有动作上的平均成功率为 87.5%,其中到达任务的成功率为 100%,复杂的拾取和放置操作的成功率高达 90%。
🎯 应用场景
该研究成果可应用于自动化生产线、家庭服务机器人、医疗辅助机器人等领域。通过观看人类演示视频,机器人可以快速学习新的操作技能,降低了机器人编程的复杂度和成本。未来,该技术有望实现更智能、更灵活的人机协作。
📄 摘要(原文)
Learning from Demonstration (LfD) offers a promising paradigm for robot skill acquisition. Recent approaches attempt to extract manipulation commands directly from video demonstrations, yet face two critical challenges: (1) general video captioning models prioritize global scene features over task-relevant objects, producing descriptions unsuitable for precise robotic execution, and (2) end-to-end architectures coupling visual understanding with policy learning require extensive paired datasets and struggle to generalize across objects and scenarios. To address these limitations, we propose a novel ``Human-to-Robot'' imitation learning pipeline that enables robots to acquire manipulation skills directly from unstructured video demonstrations, inspired by the human ability to learn by watching and imitating. Our key innovation is a modular framework that decouples the learning process into two distinct stages: (1) Video Understanding, which combines Temporal Shift Modules (TSM) with Vision-Language Models (VLMs) to extract actions and identify interacted objects, and (2) Robot Imitation, which employs TD3-based deep reinforcement learning to execute the demonstrated manipulations. We validated our approach in PyBullet simulation environments with a UR5e manipulator and in a real-world experiment with a UF850 manipulator across four fundamental actions: reach, pick, move, and put. For video understanding, our method achieves 89.97% action classification accuracy and BLEU-4 scores of 0.351 on standard objects and 0.265 on novel objects, representing improvements of 76.4% and 128.4% over the best baseline, respectively. For robot manipulation, our framework achieves an average success rate of 87.5% across all actions, with 100% success on reaching tasks and up to 90% on complex pick-and-place operations. The project website is available at https://thanhnguyencanh.github.io/LfD4hri.