Temporal Action Representation Learning for Tactical Resource Control and Subsequent Maneuver Generation
作者: Hoseong Jung, Sungil Son, Daesol Cho, Jonghae Park, Changhyun Choi, H. Jin Kim
分类: cs.RO, cs.AI
发布日期: 2026-02-21
备注: ICRA 2026, 8 pages
💡 一句话要点
提出TART框架,通过时序动作表征学习实现战术资源控制和后续机动生成
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 时序动作表征学习 战术资源控制 机动生成 对比学习 混合动作空间
📋 核心要点
- 现有混合动作空间方法未能充分捕捉资源使用与机动之间的因果关系,忽略了战术决策的多模态特性。
- TART框架利用对比学习,基于互信息目标捕捉资源-机动交互中的时间依赖关系,学习战术表征。
- 实验表明,TART在迷宫导航和空战模拟中均优于现有混合动作基线,能有效利用资源并生成上下文感知的机动。
📝 摘要(中文)
自主机器人系统需要推理资源控制及其对后续机动的影响,尤其是在能量预算或感知受限的情况下。基于学习的控制在处理复杂动力学方面有效,并将问题表示为统一离散资源使用和连续机动的混合动作空间。然而,先前关于混合动作空间的工作没有充分捕捉资源使用和机动之间的因果依赖关系,也忽略了战术决策的多模态性质,这两者在快速演变的场景中至关重要。本文提出了TART,一个用于战术资源控制和后续机动生成的时间动作表征学习框架。TART利用基于互信息目标的对比学习,旨在捕捉资源-机动交互中固有的时间依赖关系。这些学习到的表征被量化为离散码本条目,以调节策略,捕捉重复出现的战术模式,并实现多模态和时间连贯的行为。我们在两个资源部署至关重要的领域评估了TART:(i)迷宫导航任务,其中有限的离散动作预算提供了增强的移动性,以及(ii)高保真空战模拟器,其中F-16智能体协调飞行机动操作武器和防御系统。在两个领域中,TART始终优于混合动作基线,证明了其在利用有限资源和产生上下文感知的后续机动方面的有效性。
🔬 方法详解
问题定义:论文旨在解决自主机器人系统中,如何在资源受限的情况下,进行有效的战术资源控制,并生成合理的后续机动策略的问题。现有方法,特别是基于混合动作空间的方法,未能充分建模资源使用和机动之间的时序依赖关系,并且忽略了战术决策的多模态特性,导致在复杂动态环境中表现不佳。
核心思路:论文的核心思路是通过学习资源使用和机动之间的时序关系,得到一种有效的动作表征。这种表征能够捕捉战术决策的多模态特性,并用于指导后续的机动生成。通过对比学习,模型可以学习到哪些资源使用模式会导致哪些机动,从而做出更明智的决策。
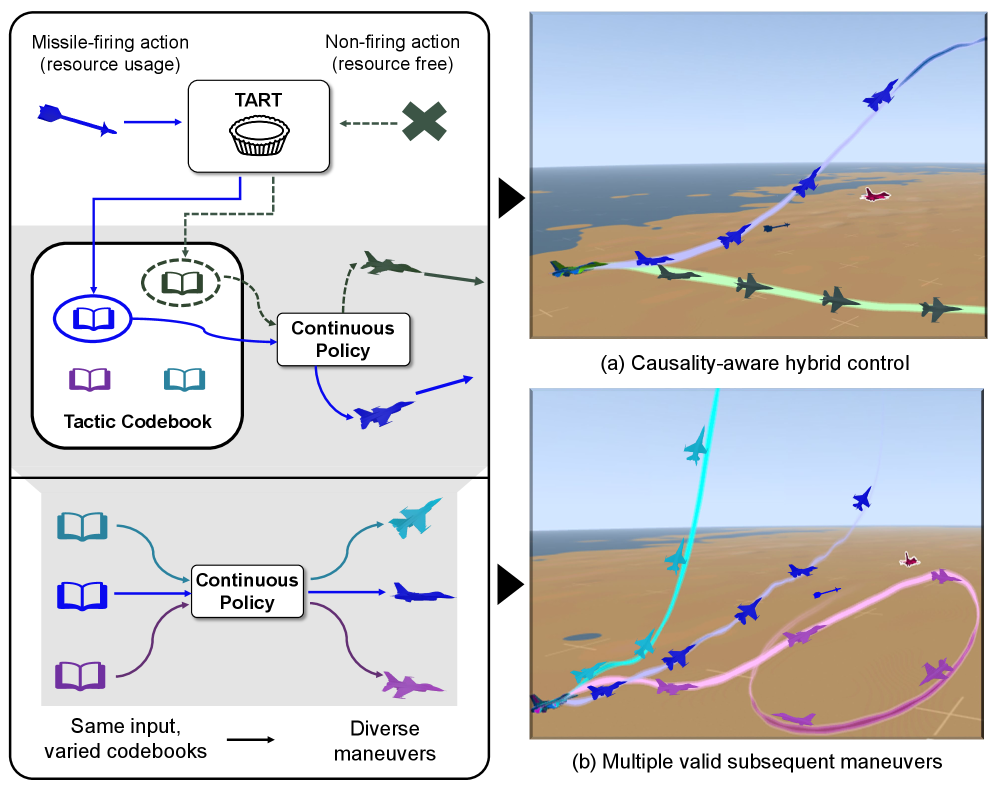
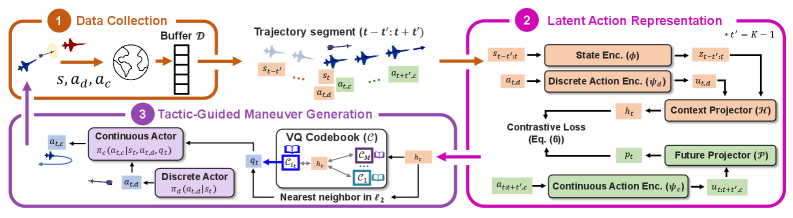
技术框架:TART框架主要包含以下几个模块:1) 动作编码器:将资源控制和机动动作编码成向量表示。2) 时序关系建模:利用对比学习,学习动作序列中资源使用和机动之间的时序依赖关系。3) 码本量化:将学习到的动作表征量化为离散的码本条目,每个条目代表一种战术模式。4) 策略网络:使用量化后的码本条目作为条件,生成后续的机动策略。
关键创新:TART的关键创新在于利用对比学习来显式地建模资源使用和机动之间的时序依赖关系。通过最大化互信息,模型能够学习到更具表达力的动作表征,从而更好地捕捉战术决策的多模态特性。此外,码本量化的引入使得模型能够识别和利用重复出现的战术模式,提高决策效率。
关键设计:对比学习的目标函数基于互信息最大化,鼓励模型学习到能够预测未来动作的表征。码本大小是一个重要的超参数,需要根据具体任务进行调整。策略网络可以使用各种常见的强化学习算法,如PPO或DDPG。论文中具体使用的网络结构和参数设置未明确给出,属于未知信息。
🖼️ 关键图片
📊 实验亮点
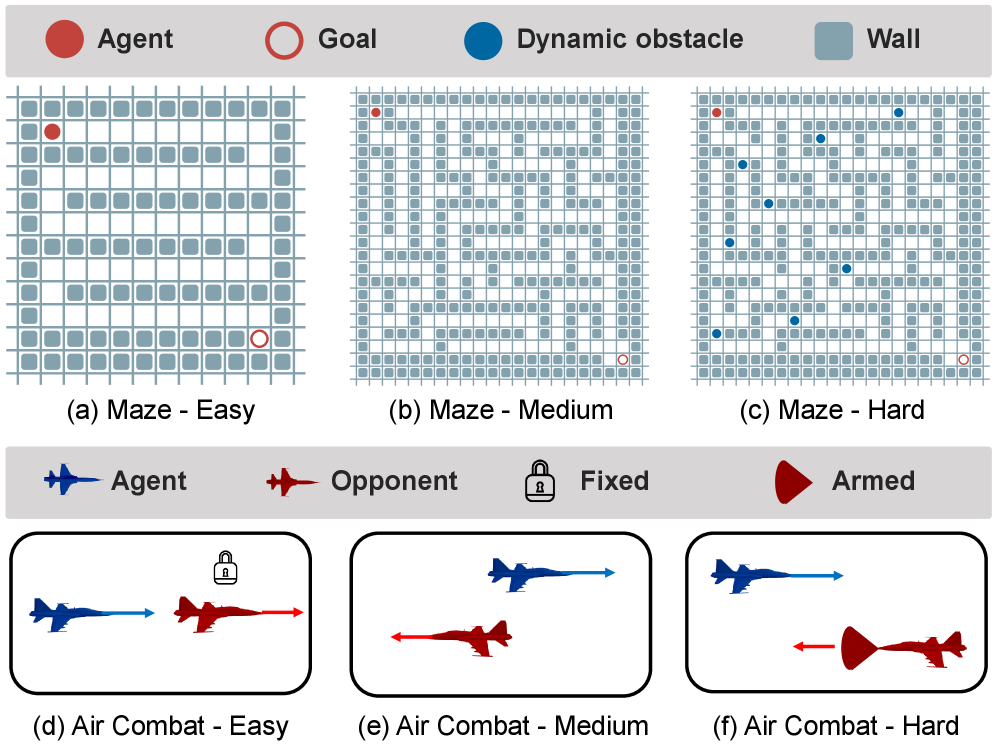
TART在迷宫导航和高保真空战模拟器两个领域进行了评估。在迷宫导航任务中,TART能够更好地利用有限的移动性增强动作,从而更快地找到目标。在高保真空战模拟器中,TART能够协调武器和防御系统的使用,并生成有效的飞行机动,从而在对抗中取得优势。具体性能提升数据未知,但论文强调TART在两个领域均优于混合动作基线。
🎯 应用场景
该研究成果可应用于各种资源受限的自主机器人系统,例如无人机集群协同作战、移动机器人路径规划、以及智能制造中的资源调度等。通过学习资源控制和机动之间的关系,机器人可以更好地利用有限的资源,并在复杂环境中做出更明智的决策,从而提高任务完成效率和鲁棒性。
📄 摘要(原文)
Autonomous robotic systems should reason about resource control and its impact on subsequent maneuvers, especially when operating with limited energy budgets or restricted sensing. Learning-based control is effective in handling complex dynamics and represents the problem as a hybrid action space unifying discrete resource usage and continuous maneuvers. However, prior works on hybrid action space have not sufficiently captured the causal dependencies between resource usage and maneuvers. They have also overlooked the multi-modal nature of tactical decisions, both of which are critical in fast-evolving scenarios. In this paper, we propose TART, a Temporal Action Representation learning framework for Tactical resource control and subsequent maneuver generation. TART leverages contrastive learning based on a mutual information objective, designed to capture inherent temporal dependencies in resource-maneuver interactions. These learned representations are quantized into discrete codebook entries that condition the policy, capturing recurring tactical patterns and enabling multi-modal and temporally coherent behaviors. We evaluate TART in two domains where resource deployment is critical: (i) a maze navigation task where a limited budget of discrete actions provides enhanced mobility, and (ii) a high-fidelity air combat simulator in which an F-16 agent operates weapons and defensive systems in coordination with flight maneuvers. Across both domains, TART consistently outperforms hybrid-action baselines, demonstrating its effectiveness in leveraging limited resources and producing context-aware subsequent maneuvers.