OVerSeeC: Open-Vocabulary Costmap Generation from Satellite Images and Natural Language
作者: Rwik Rana, Jesse Quattrociocchi, Dongmyeong Lee, Christian Ellis, Amanda Adkins, Adam Uccello, Garrett Warnell, Joydeep Biswas
分类: cs.RO, cs.CV
发布日期: 2026-02-20
备注: Website : https://amrl.cs.utexas.edu/overseec/
💡 一句话要点
OVerSeeC:基于卫星图像和自然语言的开放词汇代价地图生成
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代价地图生成 开放词汇分割 大型语言模型 自主导航 卫星图像
📋 核心要点
- 现有方法依赖固定本体和静态代价映射,无法适应任务需求变化和未知地形实体。
- OVerSeeC采用模块化框架,利用LLM进行语义理解和代码生成,结合开放词汇分割进行图像理解。
- 实验表明,OVerSeeC能处理新实体,尊重用户偏好,生成与人类轨迹一致的路线,具有鲁棒性。
📝 摘要(中文)
本文提出了一种名为OVerSeeC的零样本模块化框架,用于直接从卫星图像生成全局代价地图,以支持自主导航中的长距离规划。该框架能够处理在测试时以自然语言表达的实体和任务特定的遍历规则。OVerSeeC通过分解问题为解释-定位-合成三个阶段来解决这一挑战:(i)大型语言模型(LLM)提取实体和排序的偏好;(ii)开放词汇分割流程从高分辨率图像中识别这些实体;(iii)LLM利用用户的自然语言偏好和掩码来合成可执行的代价地图代码。实验结果表明,OVerSeeC能够处理新实体,尊重排序和组合偏好,并在不同区域生成与人类绘制轨迹一致的路线,展示了对分布偏移的鲁棒性。这表明基础模型的模块化组合能够实现开放词汇、偏好对齐的代价地图生成,从而支持可扩展的、任务自适应的全局规划。
🔬 方法详解
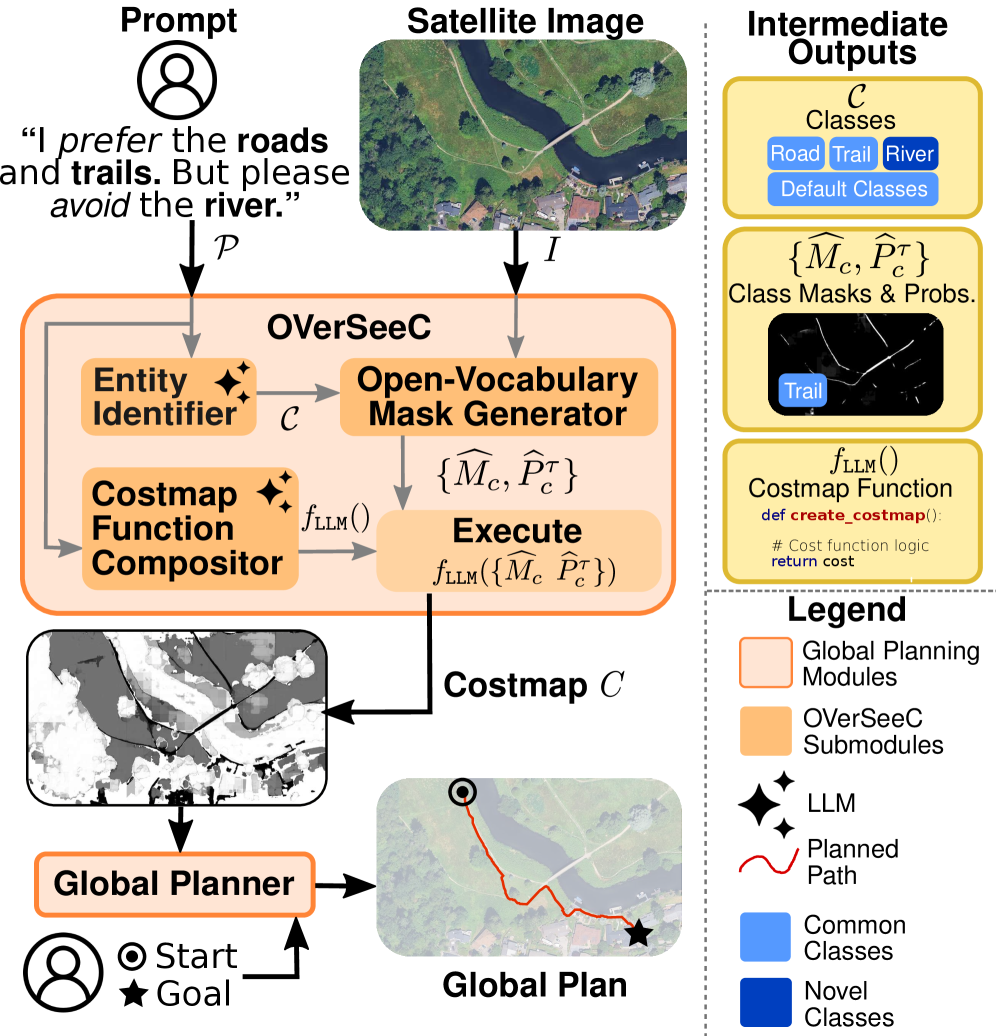
问题定义:论文旨在解决自主导航中,如何根据用户以自然语言描述的任务需求,从卫星图像中生成全局代价地图的问题。现有方法依赖于预定义的本体和静态的代价映射,无法灵活适应新的任务需求和未知的地形实体,限制了其在实际应用中的泛化能力。
核心思路:论文的核心思路是将问题分解为三个模块化的阶段:解释(Interpret)、定位(Locate)和合成(Synthesize)。通过这种分解,可以利用大型语言模型(LLM)强大的语义理解和代码生成能力,以及开放词汇分割模型对图像中任意实体的识别能力,从而实现零样本的代价地图生成。
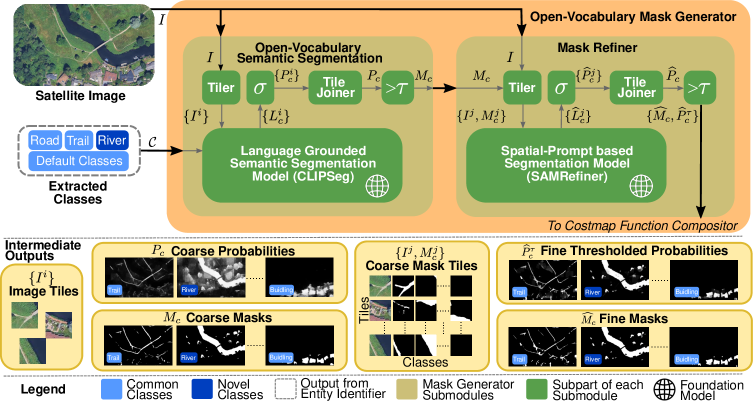
技术框架:OVerSeeC框架包含三个主要模块:1) 解释模块:使用LLM解析用户输入的自然语言指令,提取其中的实体信息和偏好排序。2) 定位模块:利用开放词汇分割模型,从高分辨率卫星图像中识别出解释模块提取的实体,并生成相应的掩码。3) 合成模块:使用LLM,根据用户的自然语言偏好和定位模块生成的掩码,合成可执行的代价地图代码。
关键创新:OVerSeeC的关键创新在于其模块化的设计和对基础模型的有效利用。它将复杂的代价地图生成问题分解为三个相对独立的子问题,并分别利用LLM和开放词汇分割模型的优势来解决这些子问题。这种模块化的设计使得OVerSeeC能够灵活适应新的任务需求和未知的地形实体,而无需重新训练模型。
关键设计:在解释模块中,LLM被用于提取实体和偏好排序,具体的prompt工程和LLM的选择(例如GPT-4)对性能至关重要。在定位模块中,使用了CLIP模型进行开放词汇分割,需要仔细选择合适的图像编码器和文本编码器。在合成模块中,LLM需要生成可执行的代价地图代码,这需要设计合适的prompt,并对LLM的输出进行验证和修正。
🖼️ 关键图片
📊 实验亮点
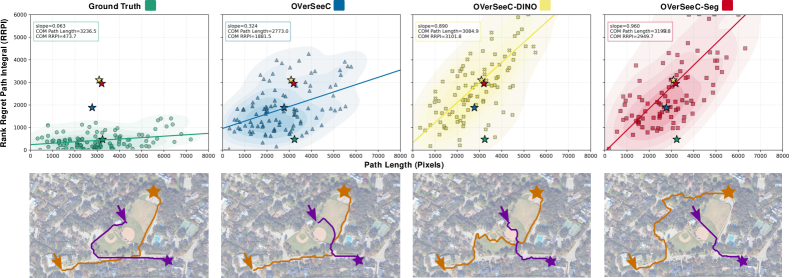
实验结果表明,OVerSeeC能够处理新实体,尊重排序和组合偏好,并在不同区域生成与人类绘制轨迹一致的路线。该框架在处理分布偏移方面表现出鲁棒性,证明了模块化组合基础模型在开放词汇、偏好对齐的代价地图生成方面的有效性。
🎯 应用场景
OVerSeeC可应用于自主导航、灾害救援、城市规划等领域。它能够根据用户自定义的任务需求,快速生成全局代价地图,为自主系统提供环境感知和路径规划能力。该研究有助于提升自主系统在复杂环境下的适应性和智能化水平,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
Aerial imagery provides essential global context for autonomous navigation, enabling route planning at scales inaccessible to onboard sensing. We address the problem of generating global costmaps for long-range planning directly from satellite imagery when entities and mission-specific traversal rules are expressed in natural language at test time. This setting is challenging since mission requirements vary, terrain entities may be unknown at deployment, and user prompts often encode compositional traversal logic. Existing approaches relying on fixed ontologies and static cost mappings cannot accommodate such flexibility. While foundation models excel at language interpretation and open-vocabulary perception, no single model can simultaneously parse nuanced mission directives, locate arbitrary entities in large-scale imagery, and synthesize them into an executable cost function for planners. We therefore propose OVerSeeC, a zero-shot modular framework that decomposes the problem into Interpret-Locate-Synthesize: (i) an LLM extracts entities and ranked preferences, (ii) an open-vocabulary segmentation pipeline identifies these entities from high-resolution imagery, and (iii) the LLM uses the user's natural language preferences and masks to synthesize executable costmap code. Empirically, OVerSeeC handles novel entities, respects ranked and compositional preferences, and produces routes consistent with human-drawn trajectories across diverse regions, demonstrating robustness to distribution shifts. This shows that modular composition of foundation models enables open-vocabulary, preference-aligned costmap generation for scalable, mission-adaptive global planning.