How Fast Can I Run My VLA? Demystifying VLA Inference Performance with VLA-Perf
作者: Wenqi Jiang, Jason Clemons, Karu Sankaralingam, Christos Kozyrakis
分类: cs.RO
发布日期: 2026-02-20
💡 一句话要点
VLA-Perf:用于分析和优化Vision-Language-Action模型推理性能的分析模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Vision-Language-Action模型 推理性能分析 性能建模 实时推理 具身智能
📋 核心要点
- 现有VLA模型推理性能受模型架构和推理系统组合影响大,缺乏系统性分析,难以满足实时性要求。
- 论文提出VLA-Perf分析模型,用于评估不同VLA模型和推理系统组合的推理性能,指导模型和系统设计。
- 通过VLA-Perf,论文系统研究了模型设计选择、部署位置等因素对VLA推理性能的影响,并总结了15个关键结论。
📝 摘要(中文)
Vision-Language-Action (VLA) 模型在具身智能任务中展现了卓越能力。然而,VLA模型架构和推理系统组合繁多,其推理性能仍缺乏深入理解,这给在实际机器人上部署VLA模型带来了挑战,因为实际部署对实时推理有严格要求。本文旨在回答一个根本性问题:如何设计未来的VLA模型和系统以支持实时推理?为此,我们提出了VLA-Perf,一个分析性能模型,能够分析任意VLA模型和推理系统的推理性能。利用VLA-Perf,我们首次对VLA推理性能进行了系统性研究。从模型设计的角度,我们考察了模型缩放、架构选择、长上下文视频输入、异步推理和双系统模型流水线如何影响推理性能。从部署的角度,我们分析了VLA推理应该在哪里执行——设备端、边缘服务器或云端——以及硬件能力和网络性能如何共同决定端到端延迟。我们从全面的评估中提炼出15个关键结论,希望这项工作能为未来VLA模型和推理系统的设计提供实践指导。
🔬 方法详解
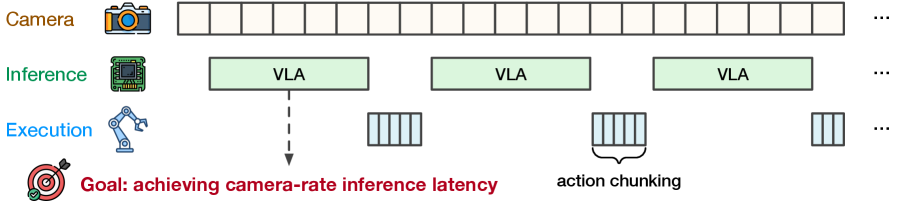
问题定义:论文旨在解决Vision-Language-Action (VLA) 模型在实际机器人部署中面临的实时推理性能问题。现有方法缺乏对VLA模型和推理系统组合的系统性分析,难以指导模型和系统的设计,从而无法满足实时性要求。现有方法难以在模型设计和部署层面进行优化,以达到实时推理的目标。
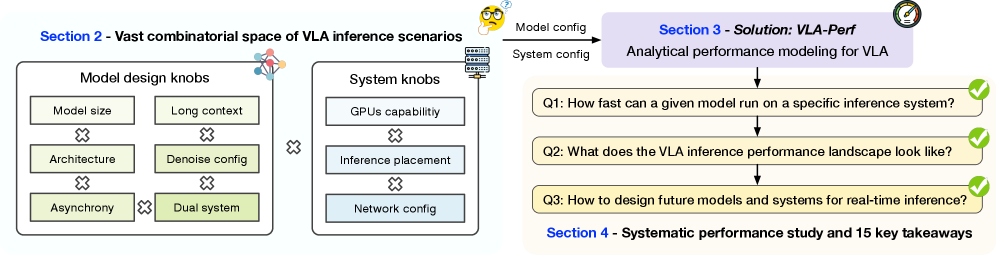
核心思路:论文的核心思路是构建一个分析性能模型VLA-Perf,该模型能够对任意VLA模型和推理系统的推理性能进行分析和预测。通过VLA-Perf,可以系统地研究不同因素(如模型架构、部署位置等)对推理性能的影响,从而为模型和系统的设计提供指导。这种方法避免了耗时的实际部署和测试,能够快速评估不同方案的性能。
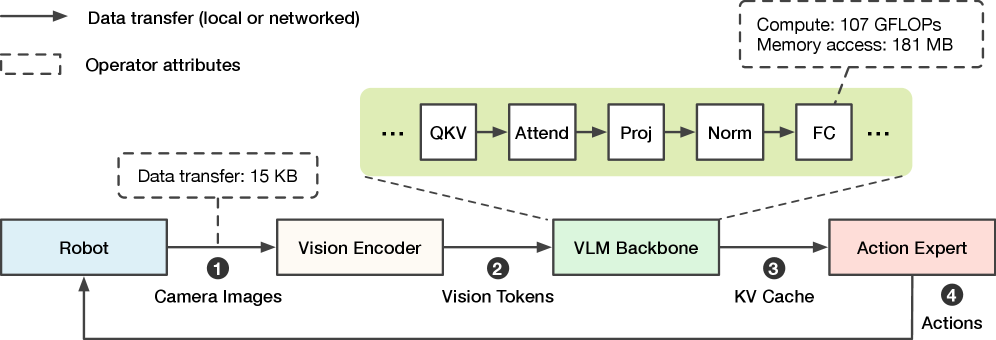
技术框架:VLA-Perf的技术框架主要包括以下几个部分:1) 模型描述:用于描述VLA模型的架构、参数量等信息。2) 系统描述:用于描述推理系统的硬件配置、软件栈等信息。3) 性能模型:基于模型和系统描述,预测推理延迟、吞吐量等性能指标。4) 分析模块:用于分析不同因素对性能的影响,并提供优化建议。整体流程是,首先对VLA模型和推理系统进行描述,然后利用性能模型预测性能指标,最后通过分析模块进行性能分析和优化。
关键创新:论文的关键创新在于提出了VLA-Perf分析性能模型。与传统的基于实际部署和测试的性能评估方法相比,VLA-Perf能够快速、高效地评估不同VLA模型和推理系统组合的性能。此外,VLA-Perf还能够分析不同因素对性能的影响,从而为模型和系统的设计提供更深入的理解和指导。
关键设计:VLA-Perf的关键设计包括:1) 模型描述语言:用于精确描述VLA模型的架构和参数。2) 硬件性能模型:用于模拟不同硬件平台的计算能力和内存带宽。3) 通信性能模型:用于模拟不同网络环境下的数据传输延迟。4) 异步推理模型:用于模拟异步推理对性能的影响。此外,论文还研究了长上下文视频输入、双系统模型流水线等因素对性能的影响,并提出了相应的优化策略。
🖼️ 关键图片
📊 实验亮点
论文通过VLA-Perf对多种VLA模型和推理系统进行了评估,揭示了模型缩放、架构选择、部署位置等因素对推理性能的影响。例如,研究发现,在某些情况下,将推理任务卸载到边缘服务器可以显著降低端到端延迟。此外,论文还提出了异步推理和双系统模型流水线等优化策略,并验证了其有效性。论文总结的15个关键结论为VLA模型和系统的设计提供了宝贵的实践指导。
🎯 应用场景
该研究成果可应用于机器人、自动驾驶、智能家居等领域,帮助开发者设计和部署满足实时性要求的VLA模型。通过VLA-Perf,可以快速评估不同模型和系统的性能,从而选择最优方案,加速VLA技术在实际场景中的应用。未来,该研究可以扩展到其他类型的AI模型,为更广泛的应用提供性能优化指导。
📄 摘要(原文)
Vision-Language-Action (VLA) models have recently demonstrated impressive capabilities across various embodied AI tasks. While deploying VLA models on real-world robots imposes strict real-time inference constraints, the inference performance landscape of VLA remains poorly understood due to the large combinatorial space of model architectures and inference systems. In this paper, we ask a fundamental research question: How should we design future VLA models and systems to support real-time inference? To address this question, we first introduce VLA-Perf, an analytical performance model that can analyze inference performance for arbitrary combinations of VLA models and inference systems. Using VLA-Perf, we conduct the first systematic study of the VLA inference performance landscape. From a model-design perspective, we examine how inference performance is affected by model scaling, model architectural choices, long-context video inputs, asynchronous inference, and dual-system model pipelines. From the deployment perspective, we analyze where VLA inference should be executed -- on-device, on edge servers, or in the cloud -- and how hardware capability and network performance jointly determine end-to-end latency. By distilling 15 key takeaways from our comprehensive evaluation, we hope this work can provide practical guidance for the design of future VLA models and inference systems.