Learning to Tune Pure Pursuit in Autonomous Racing: Joint Lookahead and Steering-Gain Control with PPO
作者: Mohamed Elgouhary, Amr S. El-Wakeel
分类: cs.RO, cs.AI, cs.LG, eess.SY
发布日期: 2026-02-20
💡 一句话要点
提出基于PPO的Pure Pursuit参数自整定方法,提升自主赛车性能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自主赛车 路径跟踪 Pure Pursuit 强化学习 近端策略优化 参数自整定 F1TENTH ROS 2
📋 核心要点
- 传统Pure Pursuit算法依赖人工调参,难以适应不同赛道和速度,泛化性差。
- 提出基于PPO的强化学习方法,在线联合优化前视距离和转向增益,无需人工干预。
- 实验表明,该方法在仿真和真实赛车上均优于传统PP算法和MPC,提升了路径跟踪精度和速度。
📝 摘要(中文)
Pure Pursuit (PP)算法因其高效和几何清晰性而被广泛应用于自主赛车中的实时路径跟踪,但其性能对关键参数(前视距离和转向增益)的选择高度敏感。标准的基于速度的调整方法通常只能近似地调整这些参数,并且常常无法跨赛道和速度曲线泛化。本文提出了一种强化学习(RL)方法,该方法使用近端策略优化(PPO)在线联合选择前视距离Ld和转向增益g。该策略观察紧凑的状态特征(速度和曲率),并在每个控制步骤输出(Ld, g)。该策略在F1TENTH Gym中训练,并在ROS 2堆栈中部署,直接驱动PP(带有轻微平滑),并且不需要针对每个地图进行重新调整。在仿真和真实车辆测试中,所提出的联合选择(Ld, g)的RL-PP控制器始终优于固定前视距离的PP、基于速度调度的自适应PP和仅使用RL调整前视距离的变体,并且在我们评估的设置中,在单圈时间、路径跟踪精度和转向平滑度方面也超过了运动学MPC赛道跟踪器,证明了策略引导的参数调整可以可靠地改进经典的基于几何的控制。
🔬 方法详解
问题定义:Pure Pursuit (PP) 算法在自主赛车中被广泛使用,但其性能对前视距离和转向增益这两个关键参数非常敏感。传统方法通常依赖于基于速度的启发式规则进行参数调整,这些规则难以适应不同的赛道环境和速度曲线,导致泛化能力不足,需要针对每个赛道进行手动调整。
核心思路:本文的核心思路是利用强化学习 (RL) 自动学习最优的 PP 参数调整策略。通过将参数调整问题建模为一个马尔可夫决策过程 (MDP),并使用近端策略优化 (PPO) 算法训练一个策略网络,该网络能够根据当前车辆的状态(速度和曲率)动态地选择最佳的前视距离和转向增益。这种方法能够克服传统启发式规则的局限性,实现更好的泛化能力和性能。
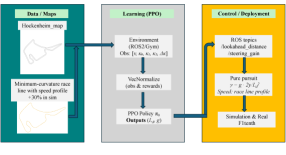
技术框架:整体框架包括三个主要部分:环境 (F1TENTH Gym 仿真器或真实赛车)、智能体 (基于 PPO 的参数调整策略) 和 Pure Pursuit 控制器。智能体观察环境的状态(速度和曲率),并输出前视距离和转向增益。这些参数被传递给 Pure Pursuit 控制器,控制器计算出车辆的转向指令。环境根据车辆的动作更新状态,并提供奖励信号给智能体,用于训练策略网络。整个过程形成一个闭环控制系统。
关键创新:该论文的关键创新在于提出了一种基于强化学习的 Pure Pursuit 参数自整定方法,能够在线联合优化前视距离和转向增益。与传统的基于速度的启发式规则相比,该方法能够更好地适应不同的赛道环境和速度曲线,实现更好的泛化能力和性能。此外,该方法还能够自动学习最优的参数调整策略,无需人工干预。
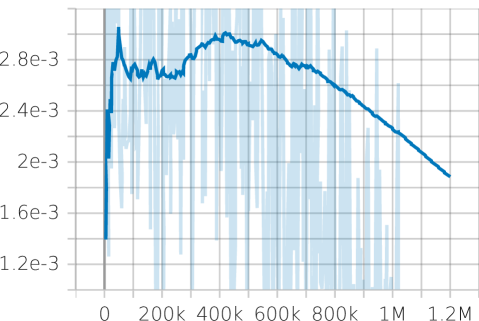
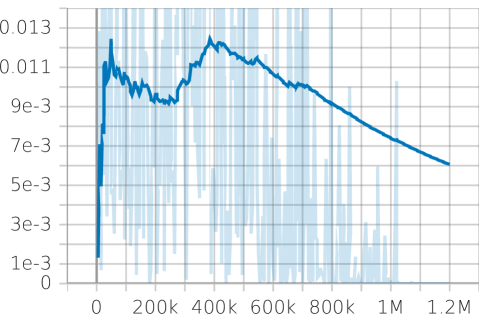
关键设计:状态空间包括车辆的速度和曲率信息,动作空间包括前视距离和转向增益。奖励函数的设计旨在鼓励车辆快速、准确地跟踪赛道中心线,并保持平稳的转向。PPO 算法用于训练策略网络,该网络采用多层感知机 (MLP) 结构。为了保证控制的平滑性,对策略网络的输出进行了平滑处理。
🖼️ 关键图片
📊 实验亮点
实验结果表明,所提出的RL-PP控制器在仿真和真实赛车测试中均优于传统的固定前视距离PP、基于速度调度的自适应PP以及仅使用RL调整前视距离的变体。在单圈时间、路径跟踪精度和转向平滑度方面,该方法甚至超过了运动学MPC赛道跟踪器,证明了其有效性。
🎯 应用场景
该研究成果可应用于各种自主车辆的路径跟踪控制,尤其是在需要高精度和高速度的场景中,如自动驾驶赛车、无人配送车等。通过自动优化Pure Pursuit参数,可以提高车辆的行驶效率、安全性和舒适性,降低人工调试成本,加速自主驾驶技术的落地。
📄 摘要(原文)
Pure Pursuit (PP) is widely used in autonomous racing for real-time path tracking due to its efficiency and geometric clarity, yet performance is highly sensitive to how key parameters-lookahead distance and steering gain-are chosen. Standard velocity-based schedules adjust these only approximately and often fail to transfer across tracks and speed profiles. We propose a reinforcement-learning (RL) approach that jointly chooses the lookahead Ld and a steering gain g online using Proximal Policy Optimization (PPO). The policy observes compact state features (speed and curvature taps) and outputs (Ld, g) at each control step. Trained in F1TENTH Gym and deployed in a ROS 2 stack, the policy drives PP directly (with light smoothing) and requires no per-map retuning. Across simulation and real-car tests, the proposed RL-PP controller that jointly selects (Ld, g) consistently outperforms fixed-lookahead PP, velocity-scheduled adaptive PP, and an RL lookahead-only variant, and it also exceeds a kinematic MPC raceline tracker under our evaluated settings in lap time, path-tracking accuracy, and steering smoothness, demonstrating that policy-guided parameter tuning can reliably improve classical geometry-based control.