Learning Smooth Time-Varying Linear Policies with an Action Jacobian Penalty
作者: Zhaoming Xie, Kevin Karol, Jessica Hodgins
分类: cs.RO, cs.GR
发布日期: 2026-02-20
💡 一句话要点
提出基于动作雅可比惩罚的线性策略网络,用于学习平滑的时变线性策略。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 强化学习 动作雅可比惩罚 线性策略网络 机器人控制 运动模仿
📋 核心要点
- 现有强化学习策略常产生不自然的高频控制信号,难以应用于真实机器人,且现有平滑策略方法需要大量调参。
- 本文提出动作雅可比惩罚,通过自动微分直接约束动作变化,无需任务特定调参即可消除高频信号。
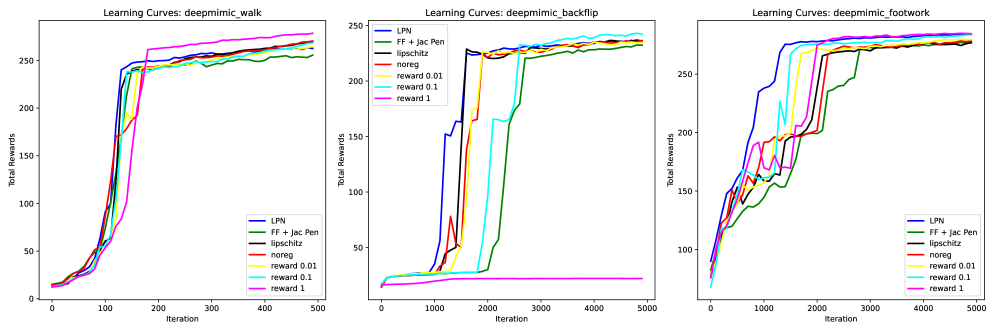
- 为降低计算负担,提出线性策略网络(LPN),实验表明LPN能更快收敛,并成功应用于四足机器人动态运动控制。
📝 摘要(中文)
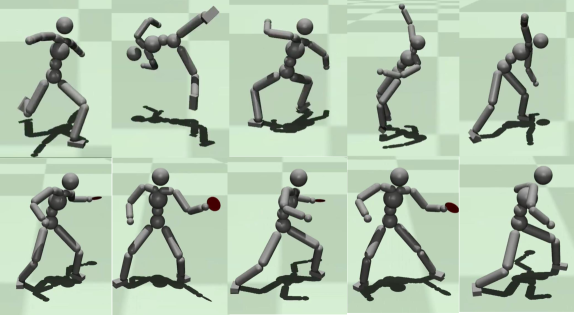
强化学习为学习控制策略提供了一个框架,该策略可以复现模拟角色的各种运动。然而,这些策略通常利用不自然的、高频信号,这些信号对于人类或物理机器人来说是无法实现的,使得它们成为现实世界行为的不良表示。现有工作通过添加一个惩罚动作随时间变化的奖励项来解决这个问题,但这通常需要大量的调优工作。我们提出使用动作雅可比惩罚,通过自动微分直接惩罚动作相对于模拟状态变化的改变。这有效地消除了不切实际的高频控制信号,而无需针对特定任务进行调整。虽然有效,但动作雅可比惩罚在与传统的全连接神经网络架构一起使用时会引入显著的计算开销。为了缓解这个问题,我们引入了一种名为线性策略网络(LPN)的新架构,该架构显著降低了训练期间计算动作雅可比惩罚的计算负担。此外,LPN不需要参数调整,与基线方法相比表现出更快的学习收敛速度,并且在推理时可以更有效地查询。我们证明了线性策略网络与动作雅可比惩罚相结合,能够学习生成平滑信号的策略,同时解决具有不同特征的多个运动模仿任务,包括动态运动(如后空翻)和各种具有挑战性的跑酷技能。最后,我们将这种方法应用于在配备手臂的物理四足机器人上创建动态运动策略。
🔬 方法详解
问题定义:现有强化学习方法在控制模拟角色运动时,生成的策略常常包含不自然的高频信号,导致无法直接应用于真实的机器人控制。现有的通过惩罚动作变化来平滑策略的方法,需要针对不同的任务进行大量的参数调整,缺乏通用性。
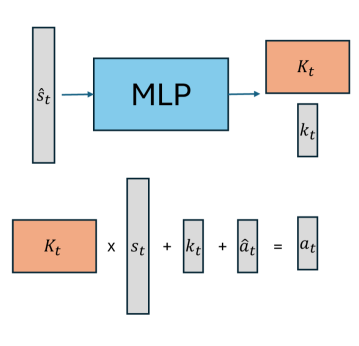
核心思路:本文的核心思路是通过引入动作雅可比惩罚,直接约束动作相对于状态的变化。动作雅可比矩阵描述了动作对状态变化的敏感程度,通过惩罚雅可比矩阵的范数,可以有效地抑制高频控制信号,从而生成更加平滑的控制策略。同时,为了降低计算复杂度,作者设计了一种新的网络结构——线性策略网络(LPN)。
技术框架:整体框架包含一个强化学习训练循环,其中策略网络(LPN)根据当前状态输出动作,环境根据动作反馈新的状态和奖励。在计算损失函数时,除了传统的奖励函数外,还加入了动作雅可比惩罚项。该惩罚项通过自动微分计算动作雅可比矩阵,并惩罚其范数。LPN的设计旨在简化雅可比矩阵的计算,从而降低训练的计算负担。
关键创新:最重要的技术创新点在于将动作雅可比惩罚引入强化学习,并结合线性策略网络来降低计算复杂度。与现有方法相比,该方法无需针对特定任务进行参数调整,即可有效地生成平滑的控制策略。LPN网络结构本身也是一个创新,它通过线性层和非线性激活函数的组合,实现了高效的策略表示和雅可比矩阵计算。
关键设计:动作雅可比惩罚项的计算公式为:λ * ||∂a/∂s||,其中λ是惩罚系数,a是动作,s是状态。LPN网络由多个线性层和非线性激活函数组成,其关键在于利用线性层的特性,使得雅可比矩阵的计算可以简化为矩阵乘法。损失函数由奖励函数和动作雅可比惩罚项加权组成。参数λ的选择对最终结果有一定影响,但作者声称其鲁棒性较好,不需要精细调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,线性策略网络(LPN)结合动作雅可比惩罚,能够在多个运动模仿任务中生成平滑的控制策略,包括后空翻和跑酷等复杂动作。与传统的全连接神经网络相比,LPN具有更快的学习收敛速度和更低的计算复杂度。在四足机器人上的实验也验证了该方法在实际机器人控制中的有效性。具体性能数据未知,但作者强调了无需手动调参即可获得良好效果。
🎯 应用场景
该研究成果可广泛应用于机器人运动控制领域,尤其是在需要平滑、自然的运动控制策略的场景中,例如人形机器人、四足机器人、机械臂等。通过学习平滑的控制策略,可以提高机器人的运动性能和安全性,使其能够更好地适应复杂环境,并与人类进行更自然的交互。此外,该方法还可以应用于游戏角色的动画生成,提高动画的真实感和流畅度。
📄 摘要(原文)
Reinforcement learning provides a framework for learning control policies that can reproduce diverse motions for simulated characters. However, such policies often exploit unnatural high-frequency signals that are unachievable by humans or physical robots, making them poor representations of real-world behaviors. Existing work addresses this issue by adding a reward term that penalizes a large change in actions over time. This term often requires substantial tuning efforts. We propose to use the action Jacobian penalty, which penalizes changes in action with respect to the changes in simulated state directly through auto differentiation. This effectively eliminates unrealistic high-frequency control signals without task specific tuning. While effective, the action Jacobian penalty introduces significant computational overhead when used with traditional fully connected neural network architectures. To mitigate this, we introduce a new architecture called a Linear Policy Net (LPN) that significantly reduces the computational burden for calculating the action Jacobian penalty during training. In addition, a LPN requires no parameter tuning, exhibits faster learning convergence compared to baseline methods, and can be more efficiently queried during inference time compared to a fully connected neural network. We demonstrate that a Linear Policy Net, combined with the action Jacobian penalty, is able to learn policies that generate smooth signals while solving a number of motion imitation tasks with different characteristics, including dynamic motions such as a backflip and various challenging parkour skills. Finally, we apply this approach to create policies for dynamic motions on a physical quadrupedal robot equipped with an arm.