SimVLA: A Simple VLA Baseline for Robotic Manipulation
作者: Yuankai Luo, Woping Chen, Tong Liang, Baiqiao Wang, Zhenguo Li
分类: cs.RO, cs.LG
发布日期: 2026-02-20
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
SimVLA:用于机器人操作的简单且强大的视觉-语言-动作基线模型
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 机器人操作 基线模型 模仿学习 强化学习
📋 核心要点
- 现有VLA模型架构复杂,训练方法多样,难以确定性能提升的真正来源。
- SimVLA通过解耦感知与控制,采用标准骨干网络和轻量动作头,建立透明的VLA基线。
- SimVLA仅用0.5B参数,在模拟环境中超越了数十亿参数的模型,并在真实机器人上达到相当的性能。
📝 摘要(中文)
视觉-语言-动作(VLA)模型已成为通用机器人操作的一种有前景的范例,它利用大规模预训练来实现强大的性能。该领域随着额外的空间先验和各种架构创新而迅速发展。然而,这些进步往往伴随着不同的训练方法和实现细节,这使得难以区分经验收益的精确来源。在这项工作中,我们引入了SimVLA,一个简化的基线,旨在为VLA研究建立一个透明的参考点。通过严格地将感知与控制分离,使用标准的视觉-语言骨干网络和一个轻量级的动作头,并标准化关键的训练动态,我们证明了一个最小的设计可以实现最先进的性能。尽管只有0.5B参数,SimVLA在标准模拟基准测试中优于具有数十亿参数的模型,而无需机器人预训练。SimVLA也达到了与pi0.5相当的真实机器人性能。我们的结果表明,SimVLA是一个稳健、可复现的基线,能够清晰地将经验收益归因于未来的架构创新。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型在机器人操作任务中取得了显著进展,但复杂的架构和不一致的训练流程使得评估不同组件的贡献变得困难。现有方法难以区分架构创新带来的增益和训练技巧带来的增益,缺乏一个清晰、可复现的基准。
核心思路:SimVLA的核心思路是构建一个极简的VLA模型,通过严格控制各个组件的设计和训练流程,建立一个透明的基线。通过解耦感知和控制,使用标准化的视觉-语言骨干网络和轻量级的动作头,可以更容易地评估未来架构改进的有效性。
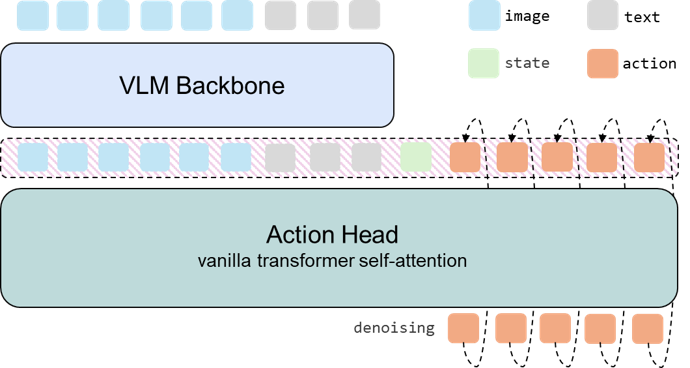
技术框架:SimVLA的整体架构包含三个主要模块:视觉编码器、语言编码器和动作解码器。视觉编码器负责从图像中提取视觉特征,语言编码器负责从文本指令中提取语义特征。然后,视觉和语言特征被融合,并输入到动作解码器中,生成机器人执行的动作序列。该框架采用端到端的方式进行训练。
关键创新:SimVLA的关键创新在于其极简的设计理念和标准化的训练流程。与现有方法相比,SimVLA避免了复杂的架构设计和定制化的训练技巧,而是专注于构建一个清晰、可复现的基线。这种设计使得研究人员可以更容易地评估未来架构改进的有效性,并更好地理解VLA模型的内部工作机制。
关键设计:SimVLA使用预训练的视觉-语言模型作为骨干网络,例如CLIP。动作解码器采用简单的多层感知机(MLP)。损失函数包括动作预测损失和模仿学习损失。训练过程采用标准化的数据增强和优化策略。关键参数包括学习率、批量大小和训练轮数。模型大小被控制在0.5B参数以内。
🖼️ 关键图片

📊 实验亮点
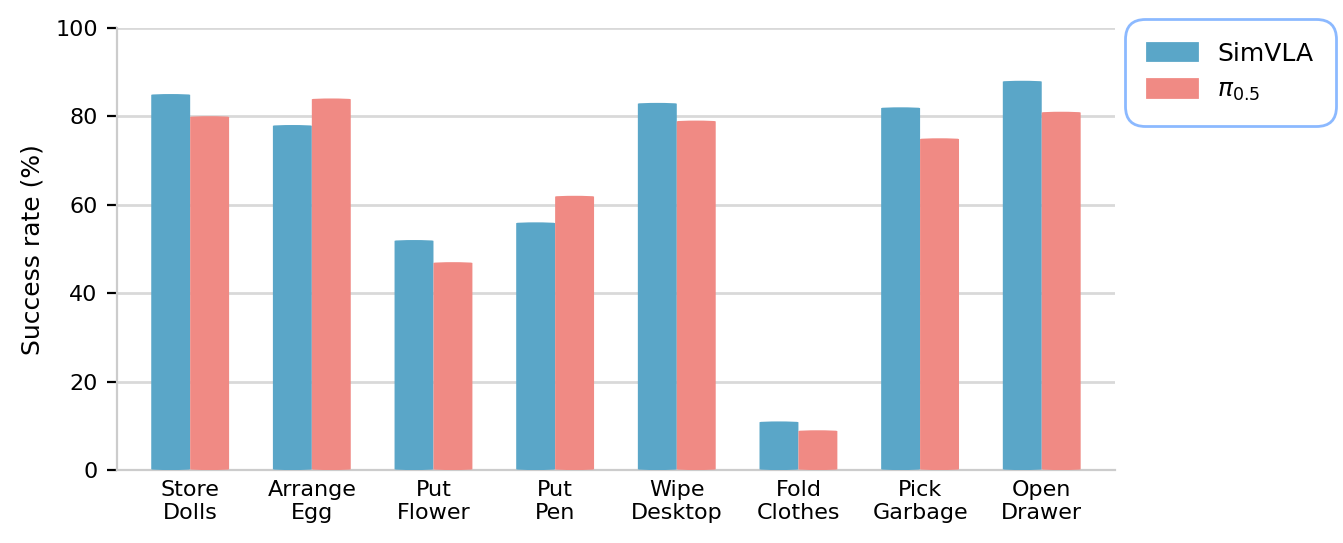
SimVLA在模拟环境中超越了参数量更大的模型,无需机器人预训练即可达到SOTA性能。在真实机器人实验中,SimVLA也达到了与pi0.5相当的性能。这些结果表明,即使采用极简的设计,VLA模型也能实现强大的性能,SimVLA是一个有力的基线。
🎯 应用场景
SimVLA可应用于各种机器人操作任务,例如物体抓取、放置、组装等。它为VLA模型的研究提供了一个可靠的基准,有助于加速该领域的发展。此外,SimVLA的极简设计使其易于部署到实际机器人系统中,具有广泛的应用前景。
📄 摘要(原文)
Vision-Language-Action (VLA) models have emerged as a promising paradigm for general-purpose robotic manipulation, leveraging large-scale pre-training to achieve strong performance. The field has rapidly evolved with additional spatial priors and diverse architectural innovations. However, these advancements are often accompanied by varying training recipes and implementation details, which can make it challenging to disentangle the precise source of empirical gains. In this work, we introduce SimVLA, a streamlined baseline designed to establish a transparent reference point for VLA research. By strictly decoupling perception from control, using a standard vision-language backbone and a lightweight action head, and standardizing critical training dynamics, we demonstrate that a minimal design can achieve state-of-the-art performance. Despite having only 0.5B parameters, SimVLA outperforms multi-billion-parameter models on standard simulation benchmarks without robot pretraining. SimVLA also reaches on-par real-robot performance compared to pi0.5. Our results establish SimVLA as a robust, reproducible baseline that enables clear attribution of empirical gains to future architectural innovations. Website: https://frontierrobo.github.io/SimVLA