Interacting safely with cyclists using Hamilton-Jacobi reachability and reinforcement learning
作者: Aarati Andrea Noronha, Jean Oh
分类: cs.RO, cs.LG
发布日期: 2026-02-20
备注: 7 pages. This manuscript was completed in 2020 as part of the first author's graduate thesis at Carnegie Mellon University
💡 一句话要点
提出基于Hamilton-Jacobi可达性与强化学习的框架,保障自动驾驶车辆与骑行者交互安全
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自动驾驶 人机交互 强化学习 Hamilton-Jacobi可达性 安全导航
📋 核心要点
- 现有自动驾驶车辆与骑行者交互方法难以同时保证安全性和效率,且缺乏对骑行者行为适应性的建模。
- 该论文融合Hamilton-Jacobi可达性分析和深度Q学习,利用可达性分析提供安全度量,并将其作为强化学习的奖励信号。
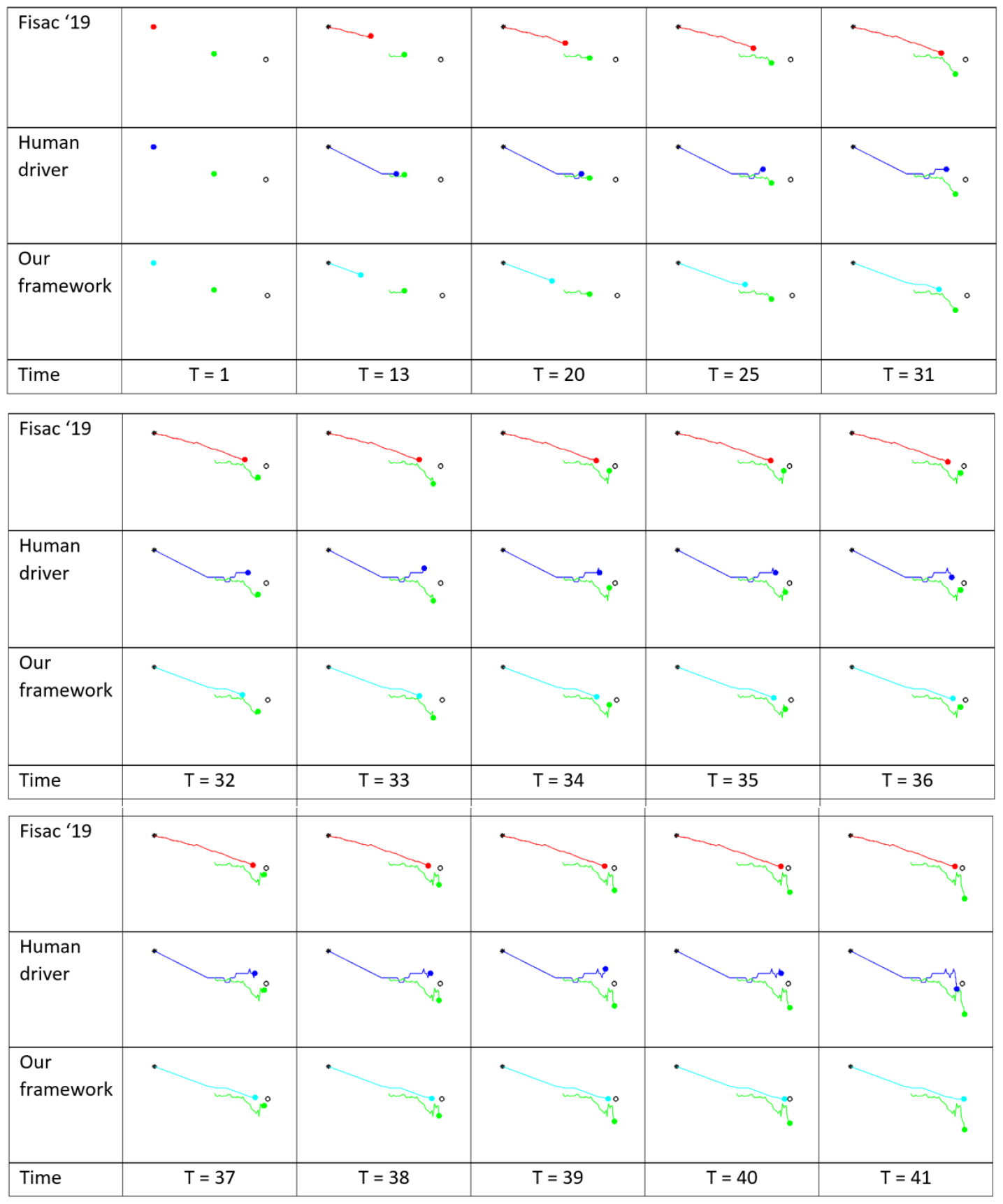
- 通过仿真实验验证了该框架的有效性,并与人类驾驶行为和现有方法进行了对比,展示了其优越性。
📝 摘要(中文)
本文提出了一种框架,旨在使自动驾驶车辆能够以兼顾安全性和最优性的方式与骑行者互动。该方法将Hamilton-Jacobi可达性分析与深度Q学习相结合,共同解决安全保证和时间效率导航问题。通过求解时变Hamilton-Jacobi-Bellman不等式计算价值函数,为每个系统状态提供定量的安全度量。该安全指标作为结构化的奖励信号被纳入强化学习框架中。该方法进一步对骑行者对车辆的潜在反应进行建模,允许扰动输入反映人类的舒适度和行为适应性。通过仿真,并将结果与人类驾驶行为和现有的最先进方法进行比较,对所提出的框架进行了评估。
🔬 方法详解
问题定义:自动驾驶车辆在城市环境中与骑行者安全交互是一个复杂的问题。现有的方法通常难以在保证安全性的同时,实现时间效率高的导航。此外,这些方法往往忽略了骑行者对车辆行为的适应性反应,导致安全性评估不准确。因此,需要一种能够同时考虑安全、效率和骑行者行为的自动驾驶决策框架。
核心思路:该论文的核心思路是将Hamilton-Jacobi (HJ) 可达性分析与深度Q学习相结合。HJ可达性分析提供了一种严格的安全保证,能够量化车辆在不同状态下的安全程度。深度Q学习则用于学习最优的导航策略,以实现时间效率高的驾驶。通过将HJ可达性分析得到的安全度量作为强化学习的奖励信号,可以引导车辆学习既安全又高效的驾驶策略。同时,该方法还对骑行者的行为进行建模,使其能够适应车辆的行为,从而提高安全性评估的准确性。
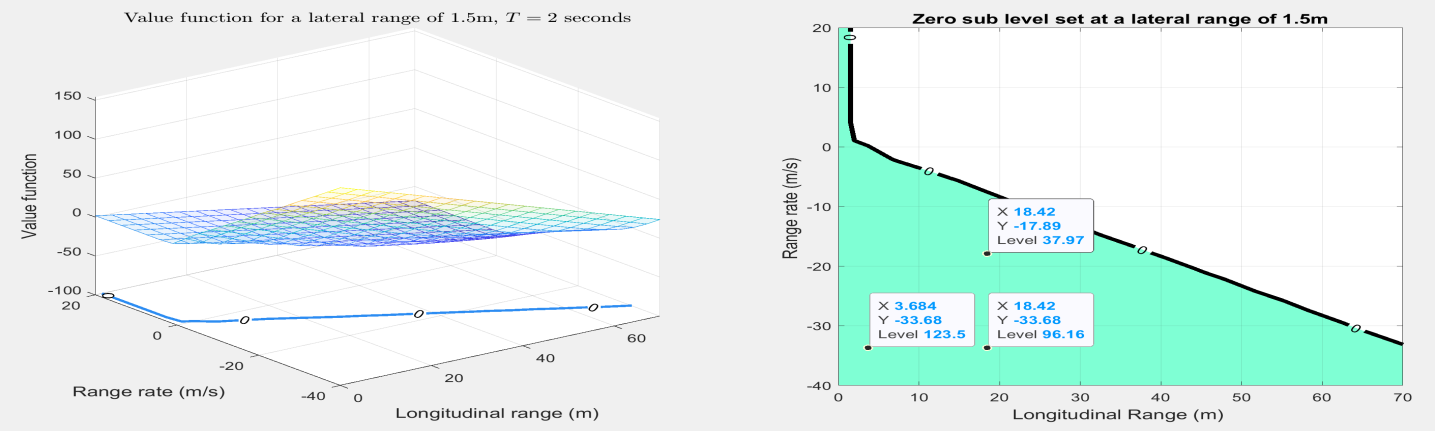
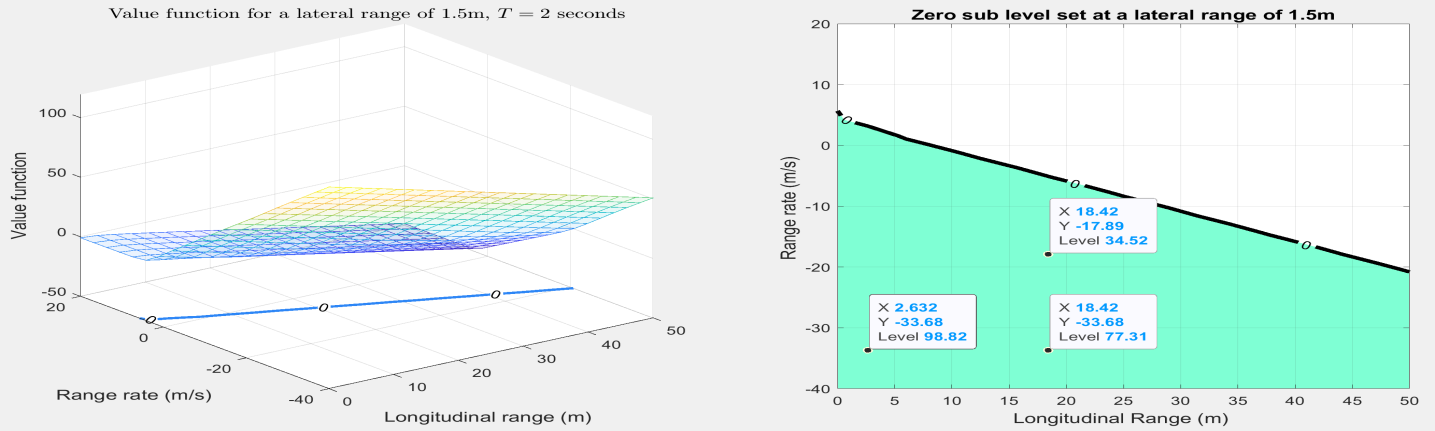
技术框架:该框架主要包含以下几个模块:1) Hamilton-Jacobi可达性分析模块:该模块用于计算车辆在不同状态下的安全价值函数,该函数是时变Hamilton-Jacobi-Bellman不等式的解。2) 骑行者行为建模模块:该模块用于对骑行者对车辆行为的潜在反应进行建模,允许扰动输入反映人类的舒适度和行为适应性。3) 深度Q学习模块:该模块使用深度神经网络来学习最优的导航策略。安全价值函数作为奖励信号被输入到深度Q学习模块中。4) 仿真环境:用于评估和验证所提出的框架。
关键创新:该论文的关键创新在于将Hamilton-Jacobi可达性分析与深度Q学习相结合,并将其应用于自动驾驶车辆与骑行者交互的安全问题。与现有方法相比,该方法能够提供更严格的安全保证,并能够学习到更高效的驾驶策略。此外,该方法还对骑行者的行为进行了建模,使其能够适应车辆的行为,从而提高安全性评估的准确性。
关键设计:Hamilton-Jacobi-Bellman不等式的具体形式需要根据车辆和骑行者的动力学模型进行设计。深度Q学习模块使用的神经网络结构和训练参数需要根据具体问题进行调整。奖励函数的设计至关重要,需要平衡安全性和效率。骑行者行为模型的参数也需要根据实际数据进行标定。
🖼️ 关键图片
📊 实验亮点
通过仿真实验,该框架在与骑行者交互时表现出良好的安全性和效率。与现有方法相比,该方法能够显著降低碰撞风险,并提高导航效率。此外,实验结果表明,该框架能够适应骑行者的行为变化,从而提高安全性评估的准确性。具体的性能数据(如碰撞率、平均行驶时间等)在论文中进行了详细的展示和分析。
🎯 应用场景
该研究成果可应用于自动驾驶车辆在城市道路上的行驶,尤其是在与骑行者等弱势交通参与者交互的场景中。通过提高自动驾驶车辆的安全性,可以减少交通事故,提升交通效率,并增强公众对自动驾驶技术的信任度。该研究还可扩展到其他机器人安全交互领域,例如人机协作等。
📄 摘要(原文)
In this paper, we present a framework for enabling autonomous vehicles to interact with cyclists in a manner that balances safety and optimality. The approach integrates Hamilton-Jacobi reachability analysis with deep Q-learning to jointly address safety guarantees and time-efficient navigation. A value function is computed as the solution to a time-dependent Hamilton-Jacobi-Bellman inequality, providing a quantitative measure of safety for each system state. This safety metric is incorporated as a structured reward signal within a reinforcement learning framework. The method further models the cyclist's latent response to the vehicle, allowing disturbance inputs to reflect human comfort and behavioral adaptation. The proposed framework is evaluated through simulation and comparison with human driving behavior and an existing state-of-the-art method.