EgoPush: Learning End-to-End Egocentric Multi-Object Rearrangement for Mobile Robots
作者: Boyuan An, Zhexiong Wang, Yipeng Wang, Jiaqi Li, Sihang Li, Jing Zhang, Chen Feng
分类: cs.RO
发布日期: 2026-02-20
备注: 18 pages, 13 figures. Project page: https://ai4ce.github.io/EgoPush/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
EgoPush:学习基于自中心视觉的多物体重排列策略,用于移动机器人
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 物体重排列 自中心视觉 强化学习 师生学习 移动机器人 非抓取操作 零样本迁移
📋 核心要点
- 现有方法依赖全局坐标,在动态遮挡环境中表现不佳,难以实现移动机器人长时程多物体重排列。
- EgoPush通过学习物体间相对关系的物体中心潜在空间,并采用师生学习框架,实现自中心视觉驱动的重排列。
- 仿真实验表明,EgoPush显著优于端到端RL基线,并成功实现了真实机器人上的零样本迁移。
📝 摘要(中文)
本文研究了移动机器人利用单个自中心相机在复杂环境中进行长时程多物体非抓取重排列的问题。受人类能力的启发,我们提出了EgoPush,一个策略学习框架,它能够进行自中心、感知驱动的重排列,而无需依赖在动态场景中经常失效的显式全局状态估计。EgoPush设计了一个以物体为中心的潜在空间来编码物体之间的相对空间关系,而不是绝对姿态。这种设计使得一个特权强化学习(RL)教师能够从稀疏的关键点联合学习潜在状态和移动动作,然后将其提炼成一个纯视觉学生策略。为了减少全知教师和部分观察学生之间的监督差距,我们限制教师的观察到视觉上可访问的线索。这诱导了可以从学生的视角恢复的主动感知行为。为了解决长时程信用分配问题,我们使用时间衰减的、阶段局部完成奖励将重排列分解为阶段级子问题。大量的仿真实验表明,EgoPush在成功率方面显著优于端到端RL基线,消融研究验证了每个设计选择。我们进一步展示了在真实世界移动平台上的零样本sim-to-real迁移。
🔬 方法详解
问题定义:论文旨在解决移动机器人如何仅通过自中心视觉感知,在复杂环境中进行多个物体的非抓取式重排列问题。现有方法通常依赖于全局状态估计,但在动态和遮挡环境中容易失效,限制了机器人的操作能力。此外,长时程任务中的信用分配也是一个挑战。
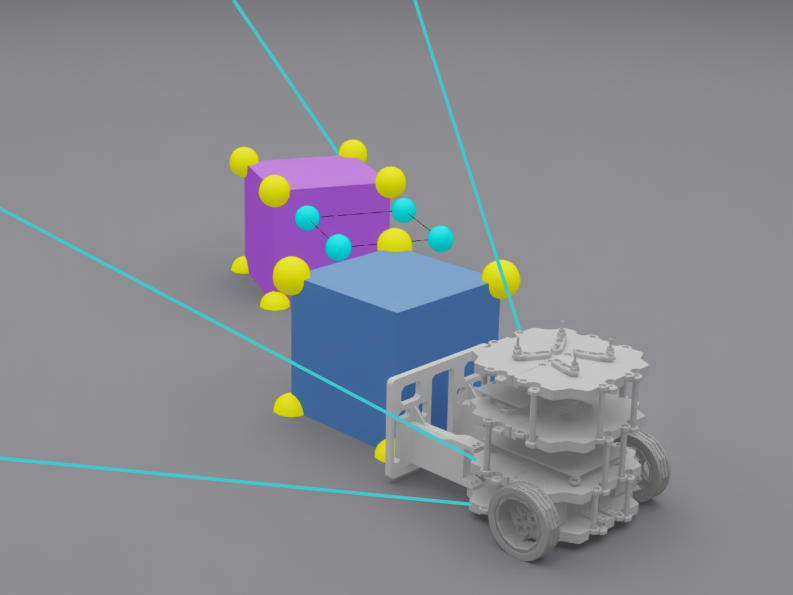
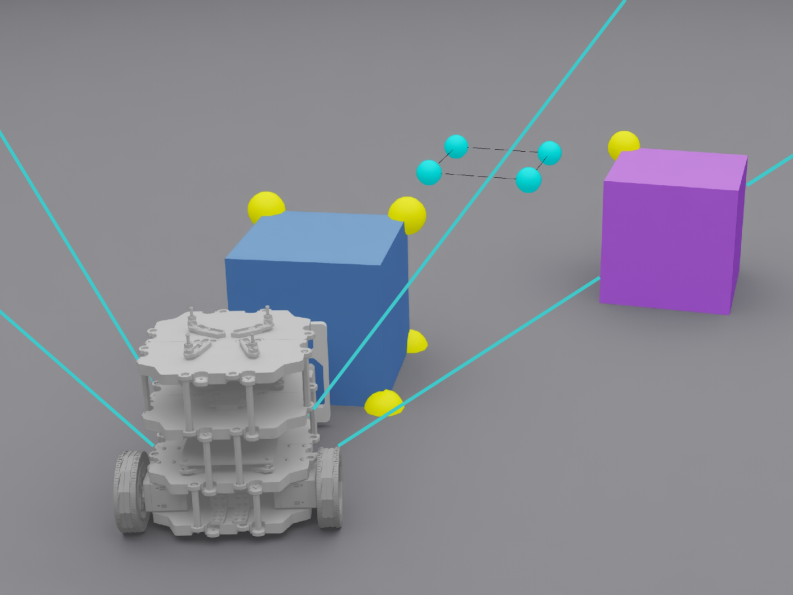
核心思路:论文的核心思路是学习一个自中心、感知驱动的重排列策略,该策略不依赖于显式的全局状态估计。通过设计一个以物体为中心的潜在空间,编码物体之间的相对空间关系,从而避免了对绝对姿态的依赖。利用师生学习框架,将从稀疏关键点学习到的策略迁移到纯视觉策略,降低了对环境的依赖。
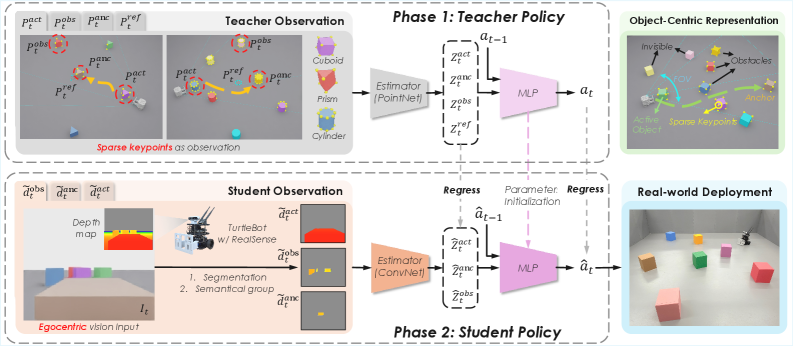
技术框架:EgoPush框架包含一个特权强化学习教师和一个视觉学生。教师从稀疏关键点学习潜在状态和动作,学生则通过视觉输入学习策略。教师的观察被限制为视觉上可访问的线索,以缩小师生之间的差距。重排列任务被分解为阶段级子问题,并使用时间衰减的阶段局部完成奖励来解决长时程信用分配问题。
关键创新:最重要的技术创新点在于以物体为中心的潜在空间表示,它能够编码物体之间的相对空间关系,从而避免了对全局状态估计的依赖。此外,限制教师的观察到视觉上可访问的线索,并使用阶段局部奖励,有助于缩小师生之间的差距,并解决长时程信用分配问题。
关键设计:论文使用了Actor-Critic架构进行强化学习。教师网络接收稀疏关键点作为输入,学生网络接收视觉图像作为输入。损失函数包括强化学习损失、蒸馏损失和辅助损失。阶段局部奖励的设计考虑了时间衰减,使得早期阶段的完成对最终奖励的影响更大。
🖼️ 关键图片
📊 实验亮点
EgoPush在仿真实验中显著优于端到端RL基线,成功率提升显著。消融实验验证了物体中心潜在空间、限制教师观察和阶段局部奖励等关键设计的有效性。更重要的是,EgoPush成功实现了在真实机器人上的零样本sim-to-real迁移,表明其具有良好的泛化能力和实用价值。
🎯 应用场景
EgoPush技术可应用于家庭服务机器人、仓储物流机器人等领域,使其能够在复杂环境中自主进行物体整理和重排列。例如,机器人可以整理杂乱的桌面,将物体放置到指定位置,或者在仓库中重新排列货物,提高空间利用率和工作效率。该技术还可扩展到其他需要精细操作和环境理解的机器人应用中。
📄 摘要(原文)
Humans can rearrange objects in cluttered environments using egocentric perception, navigating occlusions without global coordinates. Inspired by this capability, we study long-horizon multi-object non-prehensile rearrangement for mobile robots using a single egocentric camera. We introduce EgoPush, a policy learning framework that enables egocentric, perception-driven rearrangement without relying on explicit global state estimation that often fails in dynamic scenes. EgoPush designs an object-centric latent space to encode relative spatial relations among objects, rather than absolute poses. This design enables a privileged reinforcement-learning (RL) teacher to jointly learn latent states and mobile actions from sparse keypoints, which is then distilled into a purely visual student policy. To reduce the supervision gap between the omniscient teacher and the partially observed student, we restrict the teacher's observations to visually accessible cues. This induces active perception behaviors that are recoverable from the student's viewpoint. To address long-horizon credit assignment, we decompose rearrangement into stage-level subproblems using temporally decayed, stage-local completion rewards. Extensive simulation experiments demonstrate that EgoPush significantly outperforms end-to-end RL baselines in success rate, with ablation studies validating each design choice. We further demonstrate zero-shot sim-to-real transfer on a mobile platform in the real world. Code and videos are available at https://ai4ce.github.io/EgoPush/.