FRAPPE: Infusing World Modeling into Generalist Policies via Multiple Future Representation Alignment
作者: Han Zhao, Jingbo Wang, Wenxuan Song, Shuai Chen, Yang Liu, Yan Wang, Haoang Li, Donglin Wang
分类: cs.RO
发布日期: 2026-02-19
备注: Project Website: https://h-zhao1997.github.io/frappe
💡 一句话要点
FRAPPE:通过多重未来表征对齐,将世界建模融入通用策略
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人策略学习 世界建模 未来表征对齐 视觉基础模型 通用机器人
📋 核心要点
- 现有机器人策略训练方法过度依赖像素级重建,限制了模型对环境语义的理解和泛化能力。
- FRAPPE通过两阶段微调策略,首先预测未来观测的潜在表征,然后与多个视觉基础模型对齐,提升模型的世界感知能力。
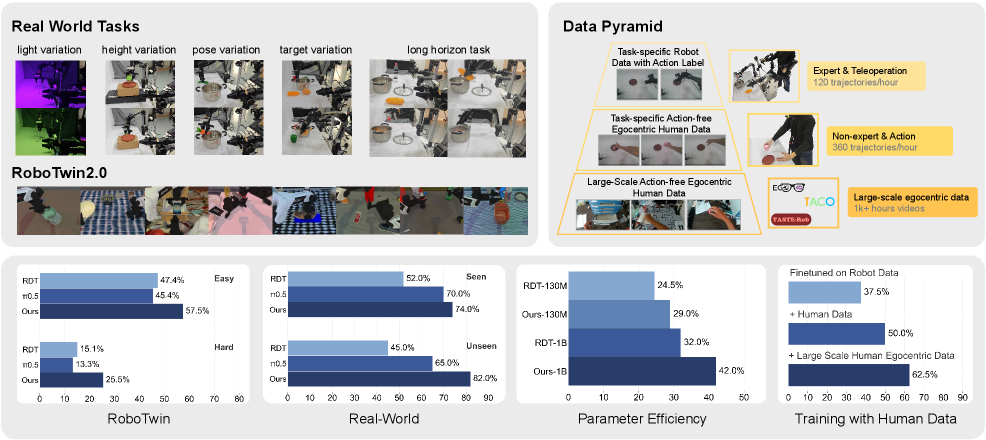
- 实验表明,FRAPPE在RoboTwin基准测试和真实世界任务中,优于现有方法,并在长时程和未见场景中表现出强大的泛化能力。
📝 摘要(中文)
为了提升机器人推理和泛化能力,将环境动态预测(即世界建模)融入视觉-语言-动作(VLA)模型至关重要。然而,现有方法面临两个主要问题:一是训练目标过度强调像素级重建,限制了语义学习和泛化;二是推理过程中依赖预测的未来观测,容易导致误差累积。为了解决这些问题,我们提出了基于并行渐进扩展的未来表征对齐(FRAPPE)。我们的方法采用两阶段微调策略:在中期训练阶段,模型学习预测未来观测的潜在表征;在后期训练阶段,我们并行扩展计算量,并同时将表征与多个不同的视觉基础模型对齐。通过显著提高微调效率并减少对动作标注数据的依赖,FRAPPE为增强通用机器人策略中的世界感知能力提供了一条可扩展且数据高效的途径。在RoboTwin基准测试和真实世界任务上的实验表明,FRAPPE优于最先进的方法,并在长时程和未见场景中表现出强大的泛化能力。
🔬 方法详解
问题定义:现有基于视觉-语言-动作(VLA)模型的机器人策略学习方法,在进行世界建模时,往往过度强调像素级别的重建,导致模型难以学习到深层的语义信息,从而限制了其泛化能力。此外,这些方法在推理过程中依赖于预测的未来观测,一旦预测出现偏差,就会导致误差累积,影响最终的决策。
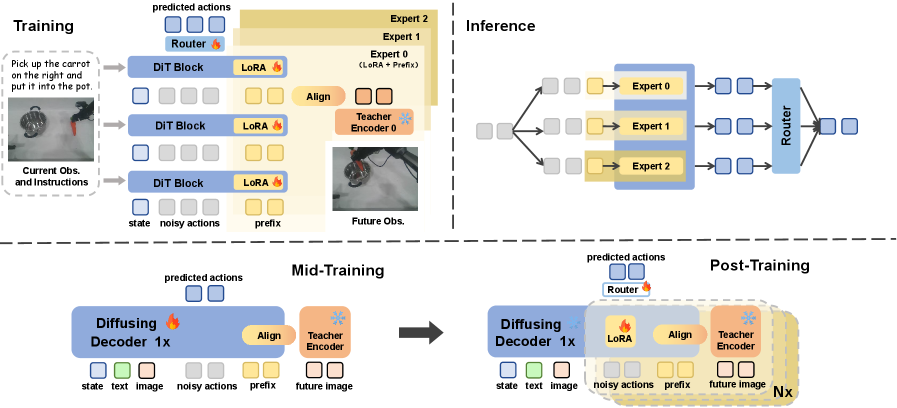
核心思路:FRAPPE的核心思路是通过未来表征对齐来提升模型的世界建模能力。具体来说,模型首先学习预测未来观测的潜在表征,然后将这些表征与多个不同的视觉基础模型对齐。这种方式避免了直接进行像素级别的重建,从而能够更好地学习到环境的语义信息。同时,通过与多个视觉基础模型对齐,可以提高表征的鲁棒性和泛化能力。
技术框架:FRAPPE采用两阶段微调策略。第一阶段(中期训练阶段),模型学习预测未来观测的潜在表征。这一阶段的目标是让模型能够理解环境的动态变化,并将其编码到潜在空间中。第二阶段(后期训练阶段),并行扩展计算量,并同时将表征与多个不同的视觉基础模型对齐。这一阶段的目标是提高表征的鲁棒性和泛化能力。整个框架的关键在于未来表征的预测和对齐。
关键创新:FRAPPE的关键创新在于其未来表征对齐策略。与传统的像素级重建方法相比,FRAPPE能够更好地学习到环境的语义信息。此外,通过与多个视觉基础模型对齐,可以提高表征的鲁棒性和泛化能力。这种方法还能够显著提高微调效率,并减少对动作标注数据的依赖。
关键设计:FRAPPE的关键设计包括:1) 使用自编码器结构来预测未来观测的潜在表征;2) 使用对比学习损失来对齐不同视觉基础模型的表征;3) 采用并行计算的方式来提高微调效率;4) 设计了一种渐进扩展的策略,逐步增加计算量,从而避免了训练过程中的不稳定。
🖼️ 关键图片

📊 实验亮点
FRAPPE在RoboTwin基准测试和真实世界任务上取得了显著的性能提升。在RoboTwin基准测试中,FRAPPE优于现有的最先进方法。在真实世界任务中,FRAPPE表现出强大的泛化能力,能够在长时程和未见场景中成功完成任务。实验结果表明,FRAPPE能够有效地提升机器人的世界建模能力,从而提高其在复杂环境中的适应性和可靠性。
🎯 应用场景
FRAPPE具有广泛的应用前景,可应用于各种需要机器人进行复杂推理和决策的任务中,例如家庭服务机器人、工业自动化、自动驾驶等。通过提升机器人的世界建模能力,FRAPPE可以帮助机器人更好地理解环境,从而做出更明智的决策,提高其在复杂环境中的适应性和可靠性。未来,FRAPPE有望成为通用机器人策略学习的重要组成部分。
📄 摘要(原文)
Enabling VLA models to predict environmental dynamics, known as world modeling, has been recognized as essential for improving robotic reasoning and generalization. However, current approaches face two main issues: 1. The training objective forces models to over-emphasize pixel-level reconstruction, which constrains semantic learning and generalization 2. Reliance on predicted future observations during inference often leads to error accumulation. To address these challenges, we introduce Future Representation Alignment via Parallel Progressive Expansion (FRAPPE). Our method adopts a two-stage fine-tuning strategy: In the mid-training phase, the model learns to predict the latent representations of future observations; In the post-training phase, we expand the computational workload in parallel and align the representation simultaneously with multiple different visual foundation models. By significantly improving fine-tuning efficiency and reducing dependence on action-annotated data, FRAPPE provides a scalable and data-efficient pathway to enhance world-awareness in generalist robotic policies. Experiments on the RoboTwin benchmark and real-world tasks demonstrate that FRAPPE outperforms state-of-the-art approaches and shows strong generalization in long-horizon and unseen scenarios.