Grasp Synthesis Matching From Rigid To Soft Robot Grippers Using Conditional Flow Matching
作者: Tanisha Parulekar, Ge Shi, Josh Pinskier, David Howard, Jen Jen Chung
分类: cs.RO
发布日期: 2026-02-19
💡 一句话要点
提出基于条件流匹配的抓取姿态迁移方法,实现刚性到柔性夹爪的抓取合成。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 柔性机器人 抓取合成 条件流匹配 刚柔迁移 机器人抓取
📋 核心要点
- 现有抓取合成方法主要针对刚性夹爪设计,难以直接应用于柔性夹爪,无法有效捕捉柔性夹爪的顺应性。
- 利用条件流匹配(CFM)学习刚性夹爪到柔性夹爪抓取姿态的映射,以物体几何信息为条件,实现抓取策略迁移。
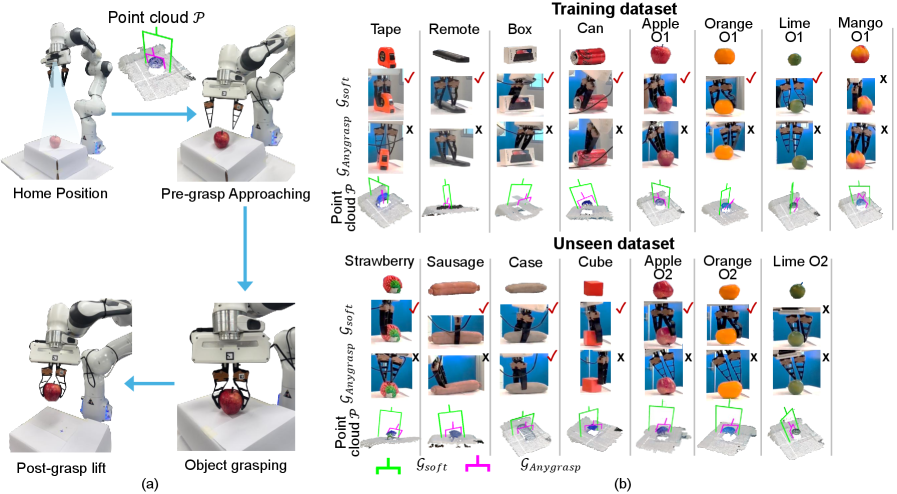
- 实验表明,该方法在已见和未见物体上的抓取成功率均显著高于基线方法,尤其在圆柱形和球形物体上提升明显。
📝 摘要(中文)
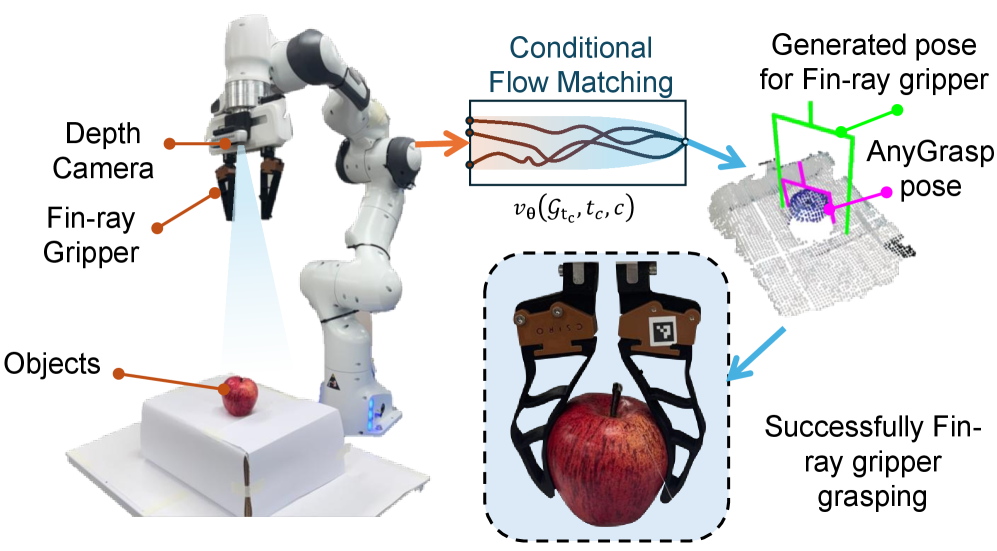
刚性和柔性夹爪的抓取合成之间存在表示差异。现有的抓取合成方法,如Anygrasp,主要为刚性平行夹爪设计,直接应用于柔性夹爪时,无法捕捉其独特的柔顺特性,导致模型需要大量数据且精度不高。为解决此问题,本文提出一种新框架,将刚性夹爪的抓取姿态映射到柔性Fin-ray夹爪。利用生成模型条件流匹配(CFM)学习这种复杂变换。该方法包含一个数据收集流程,用于生成配对的刚性-柔性抓取姿态。一个U-Net自编码器以深度图像中的物体几何信息为条件,驱动CFM模型学习从初始Anygrasp姿态到稳定Fin-ray夹爪姿态的连续映射。在7自由度机器人上的验证表明,与基线刚性姿态相比,CFM生成的姿态在已见和未见物体上的整体成功率更高(分别为34%和46%,而基线分别为6%和25%)。该模型在圆柱形(已见和未见物体的成功率分别为50%和100%)和球形物体(已见和未见物体的成功率分别为25%和31%)上表现出显著改进,并成功泛化到未见物体。这项工作表明,CFM是一种数据高效且有效的抓取策略迁移方法,为其他柔性机器人系统提供了一种可扩展的方法。
🔬 方法详解
问题定义:现有抓取合成方法,如Anygrasp,主要针对刚性平行夹爪设计,直接应用于柔性夹爪时,由于忽略了柔性夹爪的顺应性,导致抓取性能下降,且需要大量数据进行训练才能获得较好的效果。因此,如何有效地将刚性夹爪的抓取策略迁移到柔性夹爪,是本文要解决的核心问题。
核心思路:本文的核心思路是利用条件流匹配(CFM)学习一个从刚性夹爪抓取姿态到柔性夹爪抓取姿态的映射函数。通过将物体几何信息作为条件输入到CFM模型中,使得模型能够根据物体的形状自适应地调整抓取姿态,从而实现更稳定的抓取。这种方法避免了直接对柔性夹爪进行建模的复杂性,而是通过学习映射关系来实现抓取策略的迁移。
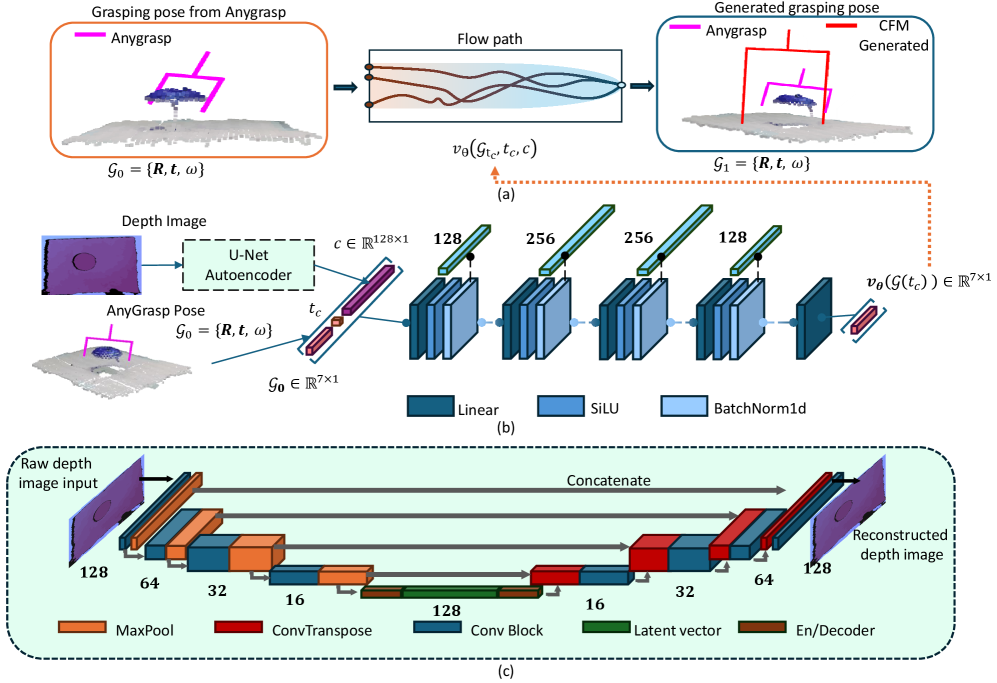
技术框架:该方法的技术框架主要包括以下几个阶段:1) 数据收集:构建一个数据收集流程,生成配对的刚性-柔性抓取姿态数据。2) 模型训练:使用U-Net自编码器提取深度图像中的物体几何特征,并将这些特征作为条件输入到CFM模型中。CFM模型学习从初始Anygrasp姿态到稳定Fin-ray夹爪姿态的连续映射。3) 抓取执行:在机器人上执行CFM模型生成的抓取姿态,并评估抓取成功率。
关键创新:该论文的关键创新在于使用条件流匹配(CFM)来学习刚性夹爪到柔性夹爪的抓取姿态映射。与传统的直接对柔性夹爪进行建模的方法相比,CFM方法更加数据高效,并且能够更好地捕捉柔性夹爪的顺应性。此外,使用U-Net自编码器提取物体几何特征作为条件输入,使得模型能够根据物体的形状自适应地调整抓取姿态。
关键设计:在数据收集方面,需要设计合理的实验流程来生成配对的刚性-柔性抓取姿态数据。在模型训练方面,U-Net自编码器的结构和参数需要仔细调整,以确保能够有效地提取物体几何特征。CFM模型的损失函数需要设计成能够鼓励模型学习到稳定的抓取姿态。具体的网络结构和参数设置在论文中没有详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在已见和未见物体上的抓取成功率均显著高于基线方法。在已见物体上,CFM生成的姿态的成功率为34%,而基线刚性姿态的成功率仅为6%。在未见物体上,CFM生成的姿态的成功率为46%,而基线刚性姿态的成功率为25%。尤其是在圆柱形和球形物体上,该方法取得了显著的提升,在未见圆柱形物体上的抓取成功率达到了100%。
🎯 应用场景
该研究成果可应用于各种需要柔性抓取的场景,例如食品加工、医疗手术、精密装配等。通过将现有的刚性夹爪抓取策略迁移到柔性夹爪,可以降低柔性机器人应用的开发成本和难度,提高抓取的稳定性和适应性。未来,该方法有望推广到其他类型的柔性机器人系统,实现更广泛的应用。
📄 摘要(原文)
A representation gap exists between grasp synthesis for rigid and soft grippers. Anygrasp [1] and many other grasp synthesis methods are designed for rigid parallel grippers, and adapting them to soft grippers often fails to capture their unique compliant behaviors, resulting in data-intensive and inaccurate models. To bridge this gap, this paper proposes a novel framework to map grasp poses from a rigid gripper model to a soft Fin-ray gripper. We utilize Conditional Flow Matching (CFM), a generative model, to learn this complex transformation. Our methodology includes a data collection pipeline to generate paired rigid-soft grasp poses. A U-Net autoencoder conditions the CFM model on the object's geometry from a depth image, allowing it to learn a continuous mapping from an initial Anygrasp pose to a stable Fin-ray gripper pose. We validate our approach on a 7-DOF robot, demonstrating that our CFM-generated poses achieve a higher overall success rate for seen and unseen objects (34% and 46% respectively) compared to the baseline rigid poses (6% and 25% respectively) when executed by the soft gripper. The model shows significant improvements, particularly for cylindrical (50% and 100% success for seen and unseen objects) and spherical objects (25% and 31% success for seen and unseen objects), and successfully generalizes to unseen objects. This work presents CFM as a data-efficient and effective method for transferring grasp strategies, offering a scalable methodology for other soft robotic systems.