One Hand to Rule Them All: Canonical Representations for Unified Dexterous Manipulation
作者: Zhenyu Wei, Yunchao Yao, Mingyu Ding
分类: cs.RO
发布日期: 2026-02-18
备注: Project Page: https://zhenyuwei2003.github.io/OHRA/
💡 一句话要点
提出一种参数化的规范表示,用于统一灵巧手操作并实现跨embodiment泛化。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 灵巧操作 机器人手 跨embodiment学习 规范表示 变分自编码器
📋 核心要点
- 现有灵巧操作策略依赖固定手部设计,限制了其在新embodiment上的泛化能力,这是核心问题。
- 提出一种参数化的规范表示,统一不同灵巧手架构的表示空间和动作空间,实现跨embodiment策略学习。
- 实验表明,该方法在仿真和真实世界任务中,对未见过的形态具有良好的零样本迁移性能,例如在3指LEAP Hand上实现了81.9%的零样本成功率。
📝 摘要(中文)
本文提出了一种参数化的规范表示,旨在统一各种灵巧手架构,解决现有方法对固定手部设计的依赖问题。该表示包含一个统一的参数空间和一个规范的URDF格式,具有三个关键优势:1) 参数空间能够捕捉形态和运动学的重要变化,从而有效指导学习算法;2) 可以在该空间上学习结构化的潜在流形,其中embodiment之间的插值能够产生平滑且具有物理意义的形态过渡;3) 规范URDF标准化了动作空间,同时保留了原始URDF的动态和功能属性,从而实现高效可靠的跨embodiment策略学习。通过大量的分析和实验,包括抓取策略重放、VAE潜在编码和跨embodiment零样本迁移,验证了这些优势。特别地,在统一表示上训练了一个VAE,以获得紧凑且语义丰富的潜在嵌入,并开发了一个以规范表示为条件的抓取策略,该策略可以推广到不同的灵巧手。通过仿真和真实世界的任务,在未见过的形态上(例如,在3指LEAP Hand上实现了81.9%的零样本成功率)证明了该框架统一了结构多样的手的表示空间和动作空间,为实现通用灵巧操作的跨手学习提供了可扩展的基础。
🔬 方法详解
问题定义:现有灵巧操作策略通常针对特定手部设计进行优化,难以泛化到具有不同运动学和结构布局的新型灵巧手。这限制了灵巧操作策略的通用性和可扩展性。现有方法的痛点在于缺乏一种通用的表示方法,能够捕捉不同灵巧手的形态和运动学特征,并实现动作空间的标准化。
核心思路:本文的核心思路是设计一种参数化的规范表示,该表示能够统一不同灵巧手架构的形态和运动学特征,并将其映射到一个标准化的动作空间。通过学习该规范表示上的策略,可以实现跨embodiment的策略迁移和泛化。这种设计能够解耦策略学习与具体的手部结构,从而提高策略的通用性和鲁棒性。
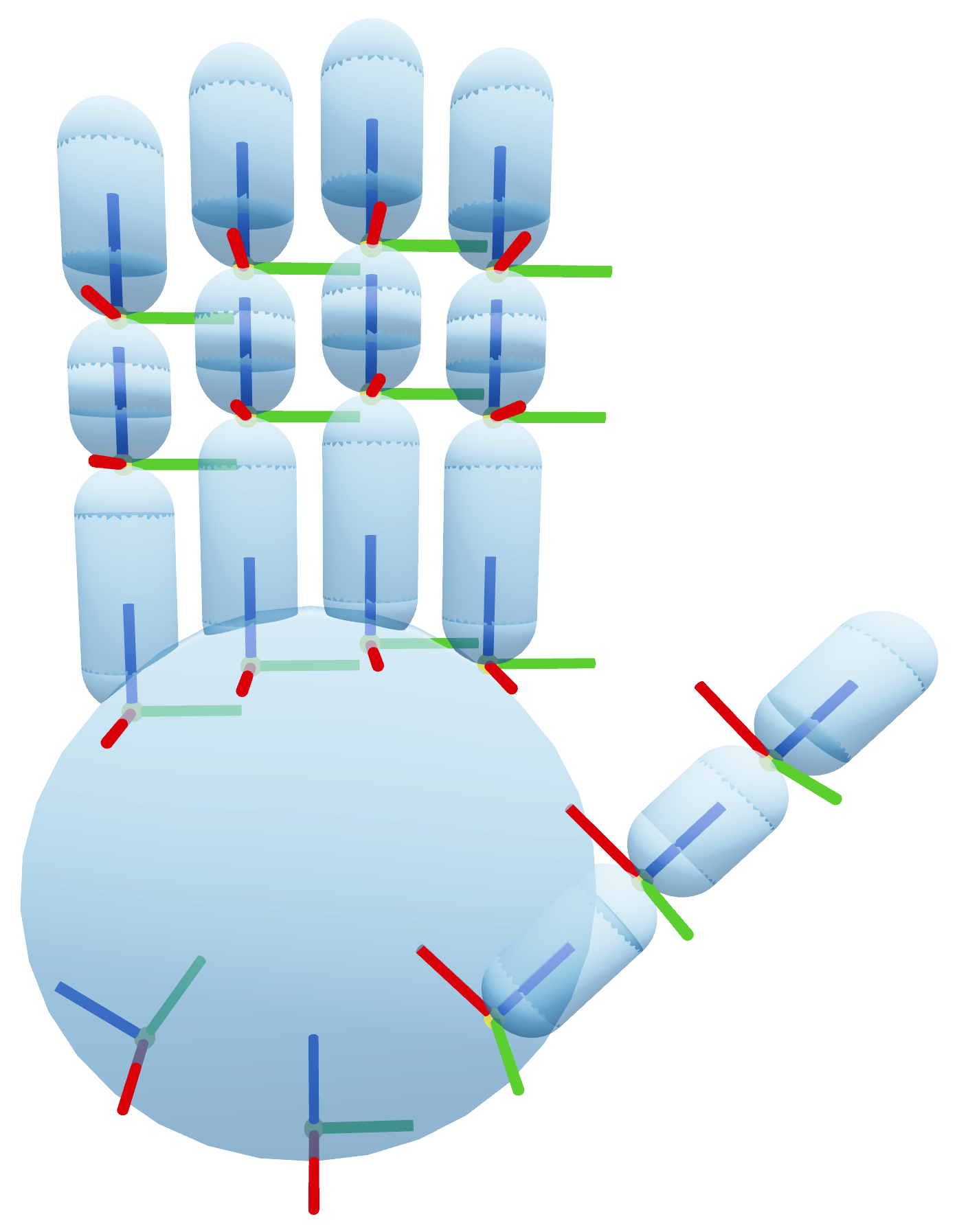
技术框架:该框架主要包含以下几个模块:1) 参数化规范表示:定义一个参数空间,用于描述不同灵巧手的形态和运动学特征。2) 规范URDF生成:基于参数空间中的参数,生成一个规范的URDF模型,该模型具有标准化的动作空间。3) VAE潜在编码:使用变分自编码器(VAE)学习参数空间的潜在表示,从而获得紧凑且语义丰富的嵌入。4) 条件策略学习:训练一个以规范表示为条件的抓取策略,该策略能够根据不同的手部形态生成相应的动作。
关键创新:最重要的技术创新点在于提出了一种参数化的规范表示,该表示能够统一不同灵巧手架构的表示空间和动作空间。与现有方法相比,该方法能够更好地捕捉不同灵巧手的形态和运动学特征,并实现动作空间的标准化,从而实现跨embodiment的策略迁移和泛化。
关键设计:参数空间的设计需要考虑不同灵巧手的关键形态和运动学参数,例如手指长度、关节角度范围等。规范URDF的设计需要保证动作空间的标准化,同时保留原始URDF的动态和功能属性。VAE的损失函数需要平衡重构误差和潜在空间的正则化。条件策略学习需要选择合适的网络结构和损失函数,以实现高效的策略学习。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在仿真和真实世界任务中均取得了良好的性能。在跨embodiment零样本迁移实验中,该方法在3指LEAP Hand上实现了81.9%的零样本成功率,显著优于基线方法。此外,通过VAE学习到的潜在表示能够捕捉不同灵巧手的语义信息,并实现平滑的形态过渡。
🎯 应用场景
该研究成果可应用于机器人灵巧操作、自动化装配、医疗康复等领域。通过该方法,可以训练一个通用的灵巧操作策略,使其能够适应不同的手部结构,从而降低开发成本,提高操作效率。未来,该方法可以扩展到更多类型的机器人和任务,实现更智能、更灵活的机器人操作。
📄 摘要(原文)
Dexterous manipulation policies today largely assume fixed hand designs, severely restricting their generalization to new embodiments with varied kinematic and structural layouts. To overcome this limitation, we introduce a parameterized canonical representation that unifies a broad spectrum of dexterous hand architectures. It comprises a unified parameter space and a canonical URDF format, offering three key advantages. 1) The parameter space captures essential morphological and kinematic variations for effective conditioning in learning algorithms. 2) A structured latent manifold can be learned over our space, where interpolations between embodiments yield smooth and physically meaningful morphology transitions. 3) The canonical URDF standardizes the action space while preserving dynamic and functional properties of the original URDFs, enabling efficient and reliable cross-embodiment policy learning. We validate these advantages through extensive analysis and experiments, including grasp policy replay, VAE latent encoding, and cross-embodiment zero-shot transfer. Specifically, we train a VAE on the unified representation to obtain a compact, semantically rich latent embedding, and develop a grasping policy conditioned on the canonical representation that generalizes across dexterous hands. We demonstrate, through simulation and real-world tasks on unseen morphologies (e.g., 81.9% zero-shot success rate on 3-finger LEAP Hand), that our framework unifies both the representational and action spaces of structurally diverse hands, providing a scalable foundation for cross-hand learning toward universal dexterous manipulation.