Learning to unfold cloth: Scaling up world models to deformable object manipulation
作者: Jack Rome, Stephen James, Subramanian Ramamoorthy
分类: cs.RO
发布日期: 2026-02-18
备注: 8 pages, 5 figures, 3 tables
💡 一句话要点
提出基于DreamerV2改进的强化学习方法,解决复杂形变物体(如布料)的操控问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 布料操控 强化学习 世界模型 DreamerV2 表面法线
📋 核心要点
- 布料操控是机器人研究的典型问题,在辅助护理和服务行业等领域具有重要应用价值,但其复杂的形变特性带来了挑战。
- 论文核心在于改进DreamerV2架构,通过引入表面法线信息,并优化回放缓冲区和数据增强,提升世界模型对布料物理特性的建模能力。
- 实验结果表明,该方法在仿真和真实机器人环境中均表现良好,能够成功展开各种类型的布料,并具有良好的泛化能力。
📝 摘要(中文)
本文提出了一种用于空中布料操控的方法,该方法基于最近提出的强化学习架构DreamerV2的变体。该实现修改了DreamerV2架构,利用表面法线输入,并改进了回放缓冲区和数据增强程序。这些修改共同增强了机器人使用的世界模型,从而解决了机器人所操控物体的物理复杂性。我们在仿真和真实机器人环境中进行了评估,在真实环境中对训练后的策略进行了零样本部署,执行各种不同类型布料的空中展开,展示了我们提出的架构的泛化优势。
🔬 方法详解
问题定义:现有方法在处理布料等复杂形变物体的操控时,难以应对形状、尺寸、褶皱模式以及外观变化等带来的挑战。传统的控制策略难以泛化到不同的布料类型和场景,需要更有效的模型来理解和预测布料的物理行为。
核心思路:论文的核心思路是通过改进世界模型,使其能够更好地理解和预测布料的物理特性。具体来说,通过引入表面法线信息作为输入,并改进回放缓冲区和数据增强策略,来增强模型对布料形变的感知和建模能力。这样可以提高策略的泛化能力,使其能够适应不同的布料类型和场景。
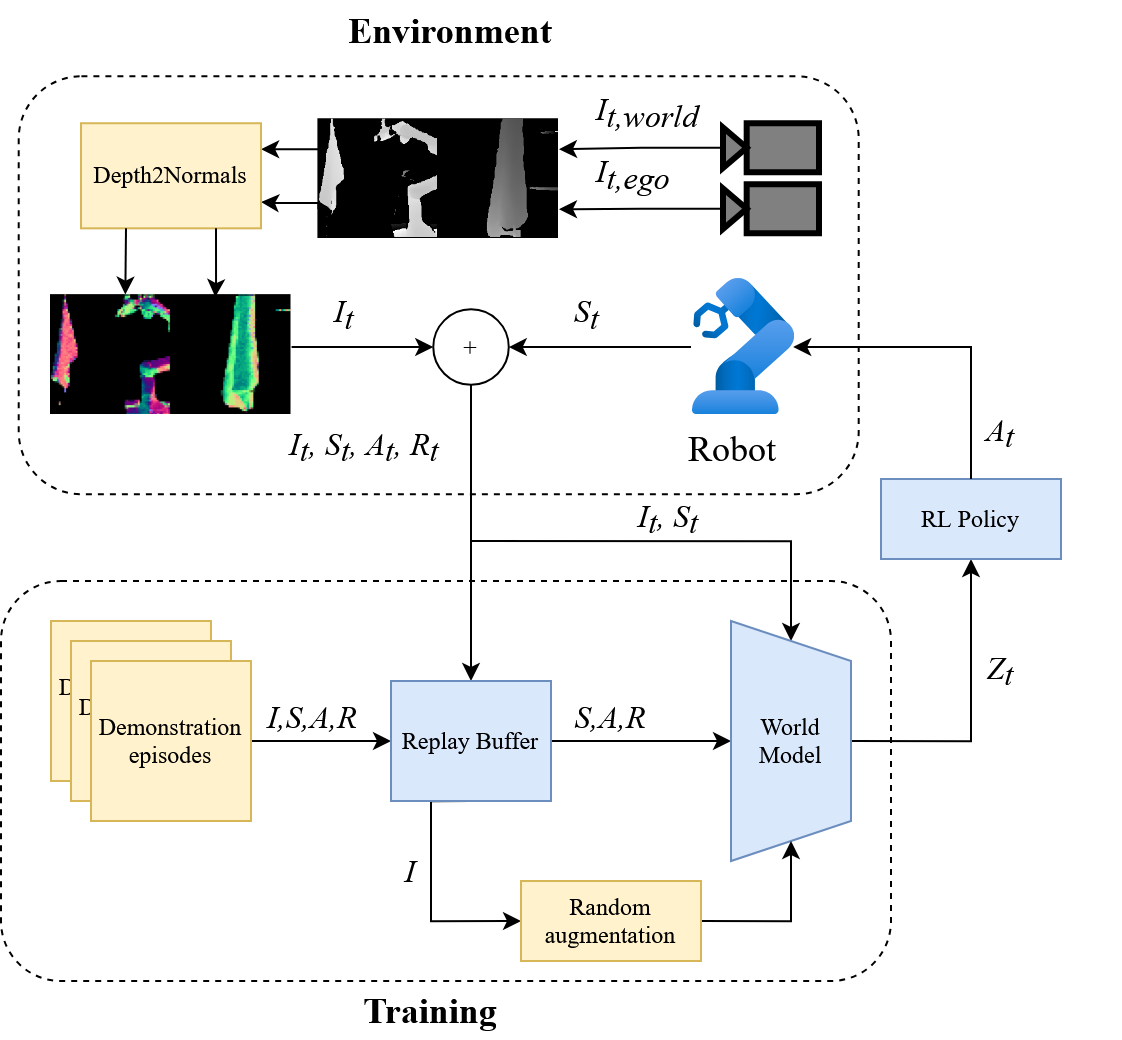
技术框架:该方法基于DreamerV2架构,这是一个基于世界模型的强化学习框架。整体流程包括:1) 使用视觉信息(包括RGB图像和表面法线)构建世界模型;2) 使用世界模型进行策略学习,训练一个能够控制机器人展开布料的策略;3) 将训练好的策略部署到真实机器人上进行测试。主要模块包括:视觉感知模块(提取RGB图像和表面法线),世界模型(预测布料的未来状态),策略学习模块(训练控制策略)。
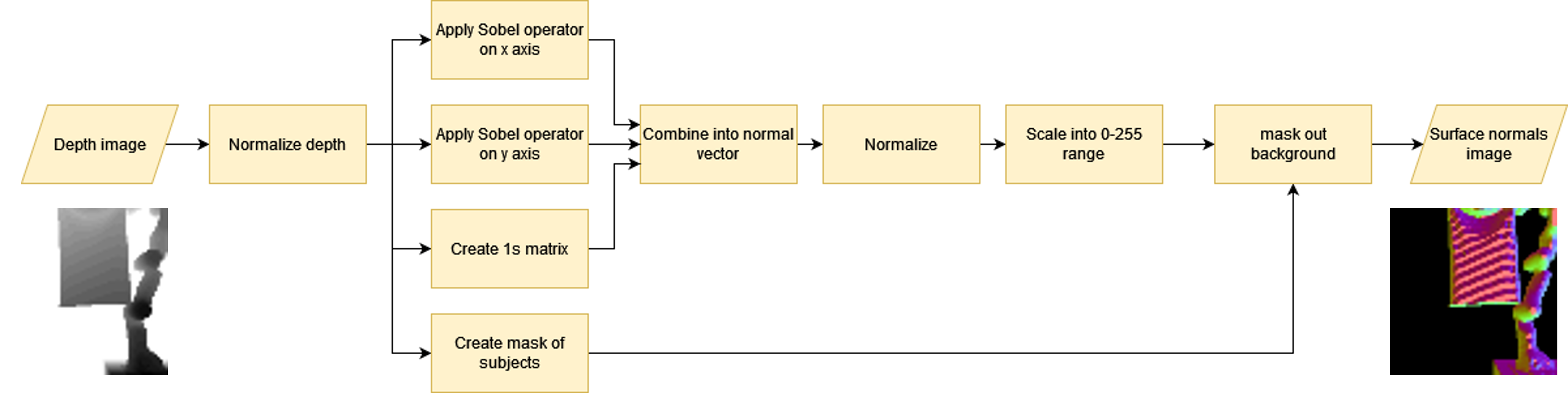
关键创新:最重要的技术创新点在于对DreamerV2架构的改进,具体包括:1) 引入表面法线作为输入,提供更丰富的几何信息;2) 改进回放缓冲区,提高训练数据的质量;3) 优化数据增强策略,增强模型的泛化能力。与现有方法相比,该方法能够更有效地建模布料的物理特性,从而提高操控策略的性能和泛化能力。
关键设计:论文中关键的设计包括:1) 使用深度神经网络来构建世界模型,包括一个编码器、一个解码器和一个动态模型;2) 使用强化学习算法(如PPO)来训练控制策略;3) 使用特定的损失函数来优化世界模型和控制策略,例如,使用重构损失来优化编码器和解码器,使用策略梯度损失来优化控制策略。具体参数设置和网络结构在论文中有详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
该方法在仿真和真实机器人环境中进行了评估。在真实环境中,该方法能够成功展开各种不同类型的布料,包括T恤、毛巾等。实验结果表明,该方法具有良好的泛化能力,能够在零样本的情况下适应新的布料类型。具体的性能数据和对比基线未知。
🎯 应用场景
该研究成果可应用于多个领域,如:1) 辅助护理:帮助机器人进行穿衣、叠衣服等任务;2) 服务行业:在酒店、洗衣店等场所,机器人可以自动整理和展开布料;3) 工业生产:在服装制造等行业,机器人可以进行布料的自动化处理。该研究有助于提高机器人的自主性和智能化水平,具有广阔的应用前景。
📄 摘要(原文)
Learning to manipulate cloth is both a paradigmatic problem for robotic research and a problem of immediate relevance to a variety of applications ranging from assistive care to the service industry. The complex physics of the deformable object makes this problem of cloth manipulation nontrivial. In order to create a general manipulation strategy that addresses a variety of shapes, sizes, fold and wrinkle patterns, in addition to the usual problems of appearance variations, it becomes important to carefully consider model structure and their implications for generalisation performance. In this paper, we present an approach to in-air cloth manipulation that uses a variation of a recently proposed reinforcement learning architecture, DreamerV2. Our implementation modifies this architecture to utilise surface normals input, in addition to modiying the replay buffer and data augmentation procedures. Taken together these modifications represent an enhancement to the world model used by the robot, addressing the physical complexity of the object being manipulated by the robot. We present evaluations both in simulation and in a zero-shot deployment of the trained policies in a physical robot setup, performing in-air unfolding of a variety of different cloth types, demonstrating the generalisation benefits of our proposed architecture.