VIGOR: Visual Goal-In-Context Inference for Unified Humanoid Fall Safety
作者: Osher Azulay, Zhengjie Xu, Andrew Scheffer, Stella X. Yu
分类: cs.RO
发布日期: 2026-02-18
💡 一句话要点
VIGOR:用于统一人形机器人跌倒安全的视觉上下文目标推理
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 人形机器人 跌倒安全 模仿学习 蒸馏学习 视觉感知 上下文推理 机器人控制
📋 核心要点
- 人形机器人跌倒恢复至关重要,但现有方法将其割裂为多个子问题,或依赖无视觉的端到端策略,泛化性受限。
- 论文提出VIGOR,通过模仿学习训练学生模型,使其学习教师模型的上下文目标潜在表示,实现快速全身反应。
- 实验表明,VIGOR在模拟和真实Unitree G1人形机器人上,实现了鲁棒的零样本跌倒安全,无需真实环境微调。
📝 摘要(中文)
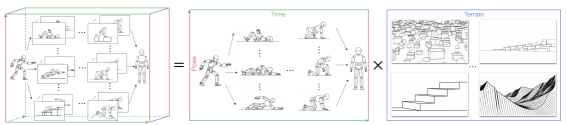
可靠的跌倒恢复对于在复杂环境中运行的人形机器人至关重要。与四足机器人或轮式机器人不同,人形机器人在跌倒过程中会经历高能量冲击、复杂的全身接触以及大的视角变化,因此恢复对于持续运行至关重要。现有的方法将跌倒安全分解为单独的问题,例如跌倒避免、冲击缓解和站立恢复,或者依赖于通过强化学习或模仿学习训练的端到端策略,通常在平坦地形上进行,且不使用视觉信息。更深层次地看,跌倒安全被视为单一的数据复杂性问题,将姿势、动力学和地形耦合在一起,需要详尽的覆盖,从而限制了可扩展性和泛化性。我们提出了一种统一的跌倒安全方法,涵盖了跌倒恢复的所有阶段。它建立在两个见解之上:1) 自然的人体跌倒和恢复姿势受到高度约束,并且可以通过对齐从平坦地形转移到复杂地形;2) 快速的全身反应需要集成的感知-运动表示。我们使用稀疏的人工演示在平坦地形和模拟的复杂地形上训练了一个特权教师模型,并将其提炼成一个可部署的学生模型,该模型仅依赖于自我中心的深度和本体感受。学生模型通过匹配教师模型的上下文目标潜在表示来学习如何反应,该表示将下一个目标姿势与局部地形相结合,而不是单独编码它必须感知什么以及必须如何行动。在模拟和真实的Unitree G1人形机器人上的结果表明,在各种非平坦环境中实现了鲁棒的、零样本的跌倒安全,而无需真实世界的微调。
🔬 方法详解
问题定义:现有的人形机器人跌倒安全方法存在以下痛点:一是将跌倒安全分解为跌倒避免、冲击缓解和站立恢复等孤立的子问题,缺乏整体性考虑;二是依赖于强化学习或模仿学习训练的端到端策略,这些策略通常在平坦地形上训练,泛化到复杂地形的能力有限;三是将姿势、动力学和地形耦合在一起,导致数据复杂性高,难以进行有效的学习和泛化。
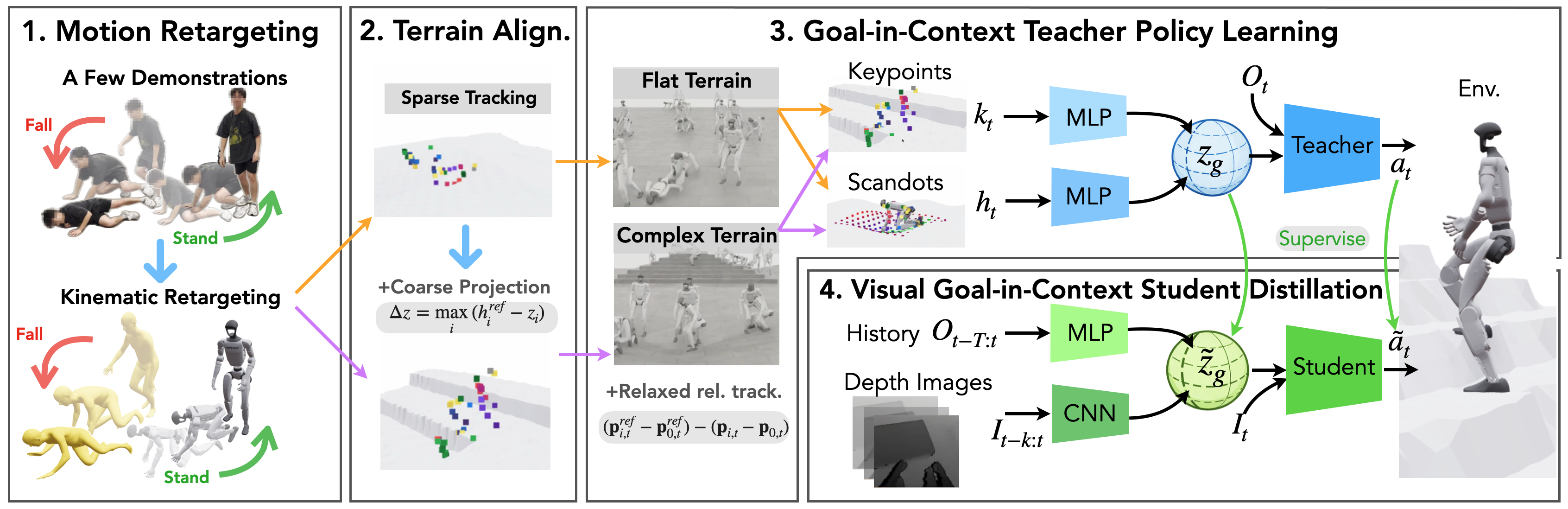
核心思路:论文的核心解决思路是利用人类跌倒和恢复姿势的内在约束性,以及快速全身反应需要集成的感知-运动表示这两个关键见解。通过模仿学习,将一个在平坦和复杂地形上训练的“教师”模型的知识迁移到一个只依赖于视觉和本体感受的“学生”模型。学生模型学习的是教师模型的“上下文目标潜在表示”,该表示融合了目标姿势和局部地形信息,从而避免了分别学习感知和行动的复杂性。
技术框架:VIGOR的技术框架主要包含以下几个阶段:1) 教师模型训练:使用稀疏的人工演示在平坦地形和模拟的复杂地形上训练一个特权教师模型。该教师模型可以访问完整的状态信息,包括机器人姿势、速度、地形信息等。2) 上下文目标潜在表示提取:教师模型学习将当前状态和目标姿势编码成一个上下文目标潜在表示。3) 学生模型训练:使用蒸馏学习,训练一个只依赖于自我中心的深度图像和本体感受的学生模型,使其能够匹配教师模型的上下文目标潜在表示。4) 部署:将训练好的学生模型部署到真实的人形机器人上,实现零样本的跌倒安全。
关键创新:VIGOR最重要的技术创新点在于其“上下文目标潜在表示”的设计。与传统的分别学习感知和行动的方法不同,VIGOR将目标姿势和局部地形信息融合到一个统一的表示中,从而简化了学习过程,提高了泛化能力。此外,VIGOR采用蒸馏学习,将一个具有完整状态信息的教师模型的知识迁移到一个只依赖于视觉和本体感受的学生模型,从而实现了在真实机器人上的部署。
关键设计:在教师模型训练中,使用了稀疏的人工演示,以减少对人工标注的依赖。在学生模型训练中,使用了对比学习损失,鼓励学生模型学习到与教师模型相似的上下文目标潜在表示。学生模型的网络结构采用了卷积神经网络(CNN)来处理深度图像,并使用循环神经网络(RNN)来处理本体感受信息。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
VIGOR在模拟和真实的Unitree G1人形机器人上进行了实验验证。实验结果表明,VIGOR能够在各种非平坦环境中实现鲁棒的零样本跌倒安全,而无需进行真实世界的微调。与传统的跌倒安全方法相比,VIGOR在复杂地形上的表现有了显著提升,并且能够更好地适应不同的跌倒姿势和环境。
🎯 应用场景
VIGOR技术可广泛应用于人形机器人的安全控制、人机协作、灾难救援等领域。通过提高人形机器人在复杂环境中的跌倒恢复能力,可以显著提升其工作效率和安全性,使其能够更好地完成各种任务。未来,该技术有望应用于家庭服务机器人、医疗辅助机器人等领域,为人们的生活带来便利。
📄 摘要(原文)
Reliable fall recovery is critical for humanoids operating in cluttered environments. Unlike quadrupeds or wheeled robots, humanoids experience high-energy impacts, complex whole-body contact, and large viewpoint changes during a fall, making recovery essential for continued operation. Existing methods fragment fall safety into separate problems such as fall avoidance, impact mitigation, and stand-up recovery, or rely on end-to-end policies trained without vision through reinforcement learning or imitation learning, often on flat terrain. At a deeper level, fall safety is treated as monolithic data complexity, coupling pose, dynamics, and terrain and requiring exhaustive coverage, limiting scalability and generalization. We present a unified fall safety approach that spans all phases of fall recovery. It builds on two insights: 1) Natural human fall and recovery poses are highly constrained and transferable from flat to complex terrain through alignment, and 2) Fast whole-body reactions require integrated perceptual-motor representations. We train a privileged teacher using sparse human demonstrations on flat terrain and simulated complex terrains, and distill it into a deployable student that relies only on egocentric depth and proprioception. The student learns how to react by matching the teacher's goal-in-context latent representation, which combines the next target pose with the local terrain, rather than separately encoding what it must perceive and how it must act. Results in simulation and on a real Unitree G1 humanoid demonstrate robust, zero-shot fall safety across diverse non-flat environments without real-world fine-tuning. The project page is available at https://vigor2026.github.io/