Markerless 6D Pose Estimation and Position-Based Visual Servoing for Endoscopic Continuum Manipulators
作者: Junhyun Park, Chunggil An, Myeongbo Park, Ihsan Ullah, Sihyeong Park, Minho Hwang
分类: cs.RO, cs.CV
发布日期: 2026-02-18
备注: 20 pages, 13 figures, 7 tables
💡 一句话要点
提出基于视觉的无标记6D位姿估计与伺服控制,用于内窥镜连续体机械臂的精准操作。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱七:动作重定向 (Motion Retargeting)
关键词: 连续体机械臂 6D位姿估计 视觉伺服 无标记 深度学习 立体视觉 域适应
📋 核心要点
- 内窥镜连续体机械臂面临滞后、柔顺性和远端传感受限等挑战,导致精确位姿估计和闭环控制困难。
- 论文提出一种无标记的立体视觉6D位姿估计方法,并结合基于位置的视觉伺服,实现精准控制。
- 通过仿真训练、多特征融合、渲染细化和自监督域适应,在真实世界中实现了显著的性能提升。
📝 摘要(中文)
本文提出了一种统一的框架,用于连续体机械臂的无标记立体6D位姿估计和基于位置的视觉伺服。通过逼真的仿真流程,实现了像素级标注的大规模自动训练。一个立体感知的多特征融合网络联合利用分割掩码、关键点、热图和边界框来增强几何可观测性。为了在没有迭代优化的情况下强制执行几何一致性,一个前馈渲染的细化模块在单次传递中预测残余位姿校正。一种自监督的sim-to-real自适应策略进一步利用未标记数据提高了真实世界的性能。大量的真实世界验证实现了0.83毫米的平均平移误差和2.76°的平均旋转误差(1000个样本)。由估计位姿驱动的无标记闭环视觉伺服实现了精确的轨迹跟踪,平均平移误差为2.07毫米,平均旋转误差为7.41°,与开环控制相比分别降低了85%和59%,并在重复的点到达任务中具有很高的重复性。据我们所知,这项工作提出了第一个完全无标记的位姿估计驱动的基于位置的连续体机械臂视觉伺服框架,无需物理标记或嵌入式传感即可实现精确的闭环控制。
🔬 方法详解
问题定义:内窥镜手术中的连续体机械臂由于其高灵活性,在微创手术中具有优势。然而,由于机械臂的滞后性、柔顺性以及远端传感的局限性,精确的位姿估计和闭环控制仍然是一个挑战。现有的基于视觉的方法虽然降低了硬件复杂度,但往往受到几何可观测性有限和计算开销高的限制,难以应用于实时闭环控制。
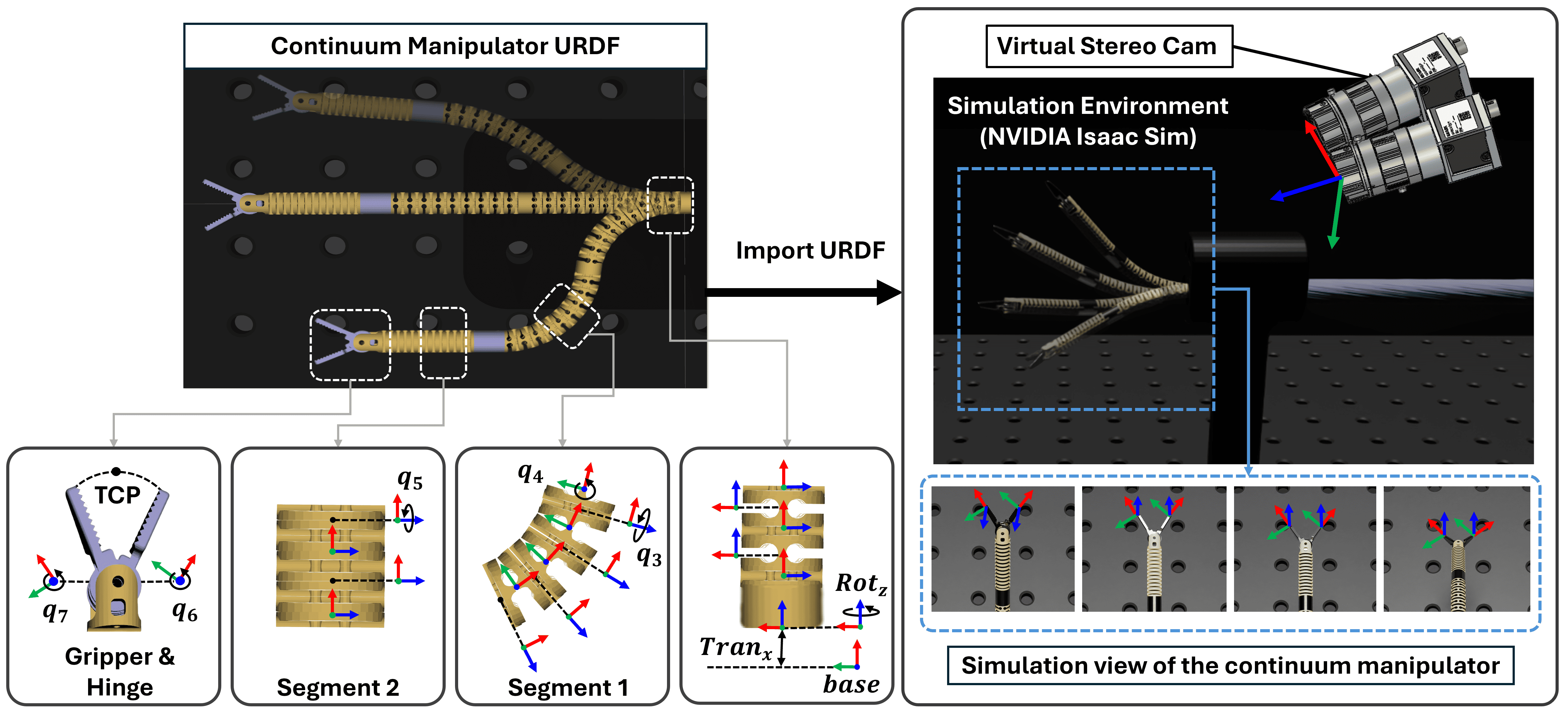
核心思路:本文的核心思路是利用立体视觉信息,通过深度学习网络直接从图像中估计连续体机械臂的6D位姿,并将其用于视觉伺服控制。通过仿真数据进行预训练,并采用自监督学习方法进行域适应,从而提高在真实环境中的性能。这种方法避免了使用物理标记或嵌入式传感器,简化了系统设计。
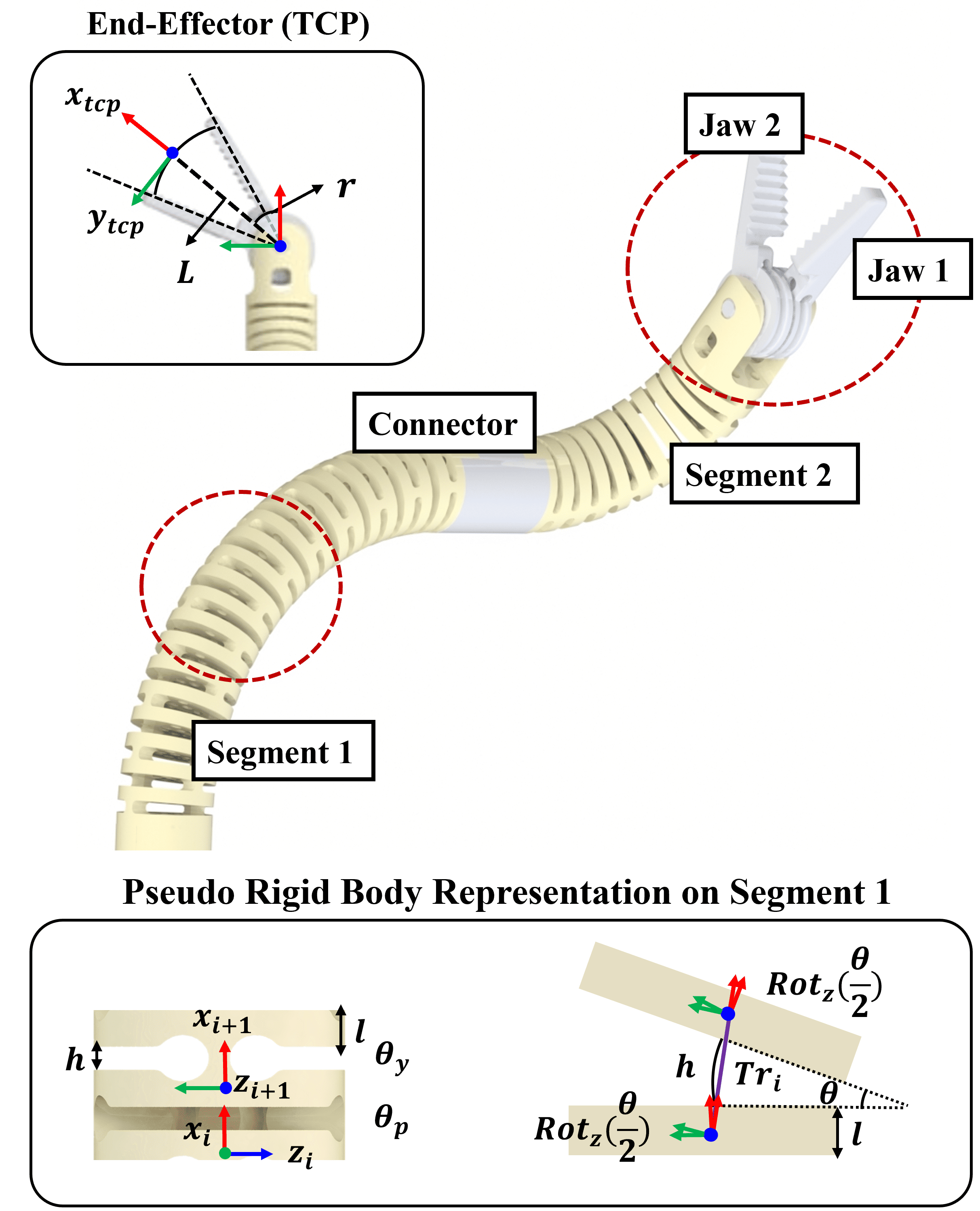
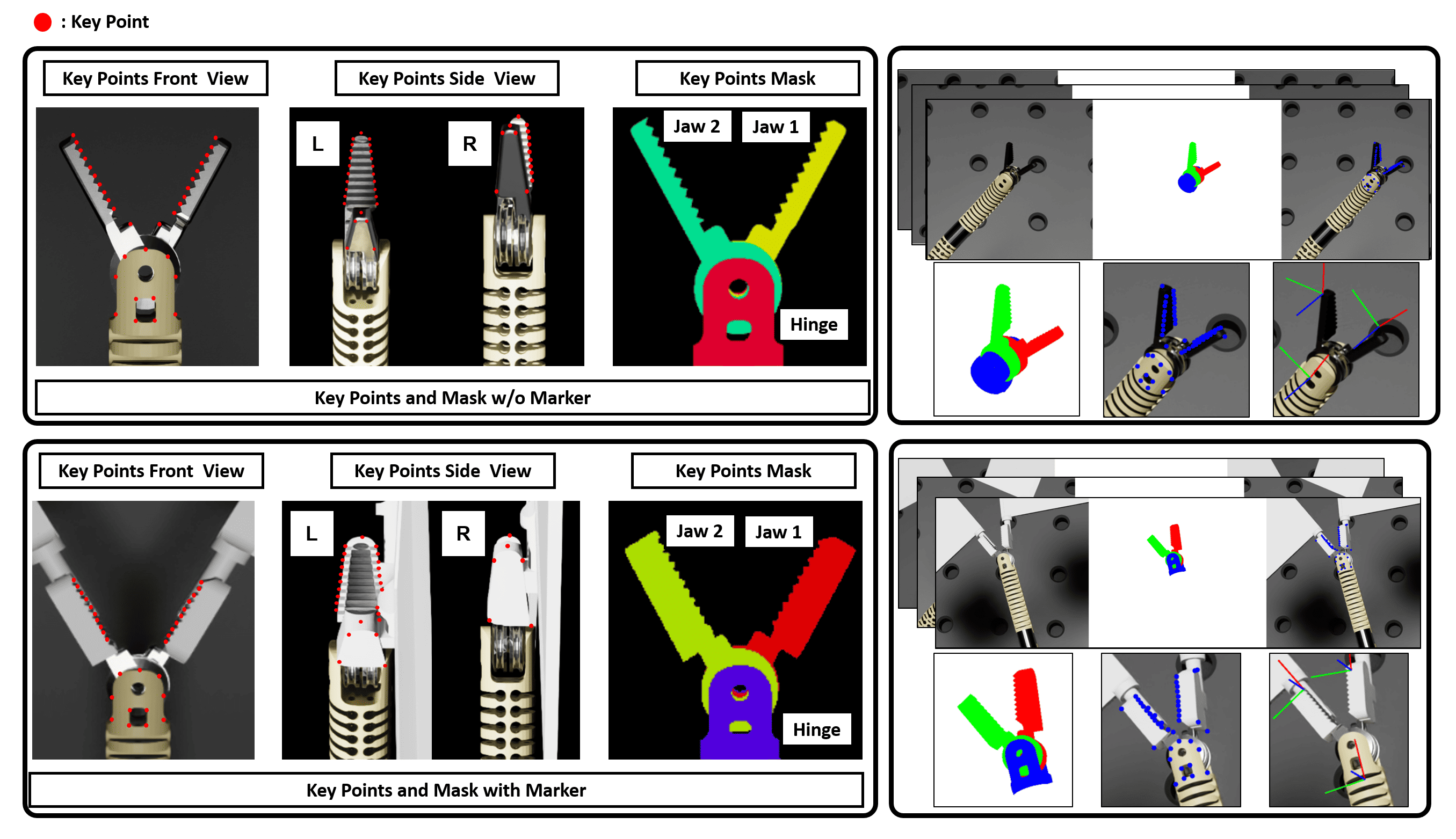
技术框架:该框架包含以下几个主要模块:1) 仿真数据生成:利用逼真的仿真环境生成大量带有像素级标注的训练数据。2) 多特征融合网络:设计一个立体感知的多特征融合网络,该网络同时利用分割掩码、关键点、热图和边界框等多种视觉特征来增强几何可观测性。3) 渲染细化模块:为了保证几何一致性,设计了一个基于渲染的细化模块,该模块通过前馈网络预测残余位姿校正。4) 自监督域适应:利用真实世界中未标记的数据,采用自监督学习方法对模型进行微调,从而提高其在真实环境中的泛化能力。5) 视觉伺服控制:将估计的6D位姿用于基于位置的视觉伺服控制,实现对连续体机械臂的精确轨迹跟踪。
关键创新:该论文的关键创新在于提出了一个完全无标记的、基于深度学习的6D位姿估计和视觉伺服框架,用于连续体机械臂的控制。与现有方法相比,该方法无需物理标记或嵌入式传感器,降低了系统复杂性,并提高了控制精度。此外,该论文还提出了一种有效的自监督域适应方法,可以显著提高模型在真实环境中的性能。
关键设计:在多特征融合网络中,使用了立体视觉信息来增强深度感知。渲染细化模块采用前馈网络结构,避免了迭代优化,提高了计算效率。自监督域适应方法利用了真实世界中未标记的数据,通过最小化重投影误差来对模型进行微调。损失函数的设计综合考虑了位姿估计的平移和旋转误差,以及重投影误差。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在真实世界中实现了0.83毫米的平均平移误差和2.76°的平均旋转误差。与开环控制相比,闭环视觉伺服控制的平均平移误差降低了85%,平均旋转误差降低了59%。在重复的点到达任务中,该方法表现出很高的重复性,验证了其在实际应用中的可行性。
🎯 应用场景
该研究成果可应用于微创手术机器人、工业检测、柔性臂控制等领域。通过精确的位姿估计和视觉伺服,可以提高手术精度和安全性,降低手术风险。在工业检测中,可以实现对复杂形状物体的精确测量和定位。未来,该技术有望进一步推广到其他需要高精度控制的柔性机器人应用中。
📄 摘要(原文)
Continuum manipulators in flexible endoscopic surgical systems offer high dexterity for minimally invasive procedures; however, accurate pose estimation and closed-loop control remain challenging due to hysteresis, compliance, and limited distal sensing. Vision-based approaches reduce hardware complexity but are often constrained by limited geometric observability and high computational overhead, restricting real-time closed-loop applicability. This paper presents a unified framework for markerless stereo 6D pose estimation and position-based visual servoing of continuum manipulators. A photo-realistic simulation pipeline enables large-scale automatic training with pixel-accurate annotations. A stereo-aware multi-feature fusion network jointly exploits segmentation masks, keypoints, heatmaps, and bounding boxes to enhance geometric observability. To enforce geometric consistency without iterative optimization, a feed-forward rendering-based refinement module predicts residual pose corrections in a single pass. A self-supervised sim-to-real adaptation strategy further improves real-world performance using unlabeled data. Extensive real-world validation achieves a mean translation error of 0.83 mm and a mean rotation error of 2.76° across 1,000 samples. Markerless closed-loop visual servoing driven by the estimated pose attains accurate trajectory tracking with a mean translation error of 2.07 mm and a mean rotation error of 7.41°, corresponding to 85% and 59% reductions compared to open-loop control, together with high repeatability in repeated point-reaching tasks. To the best of our knowledge, this work presents the first fully markerless pose-estimation-driven position-based visual servoing framework for continuum manipulators, enabling precise closed-loop control without physical markers or embedded sensing.