Articulated 3D Scene Graphs for Open-World Mobile Manipulation
作者: Martin Büchner, Adrian Röfer, Tim Engelbracht, Tim Welschehold, Zuria Bauer, Hermann Blum, Marc Pollefeys, Abhinav Valada
分类: cs.RO, cs.AI, cs.CV
发布日期: 2026-02-18
💡 一句话要点
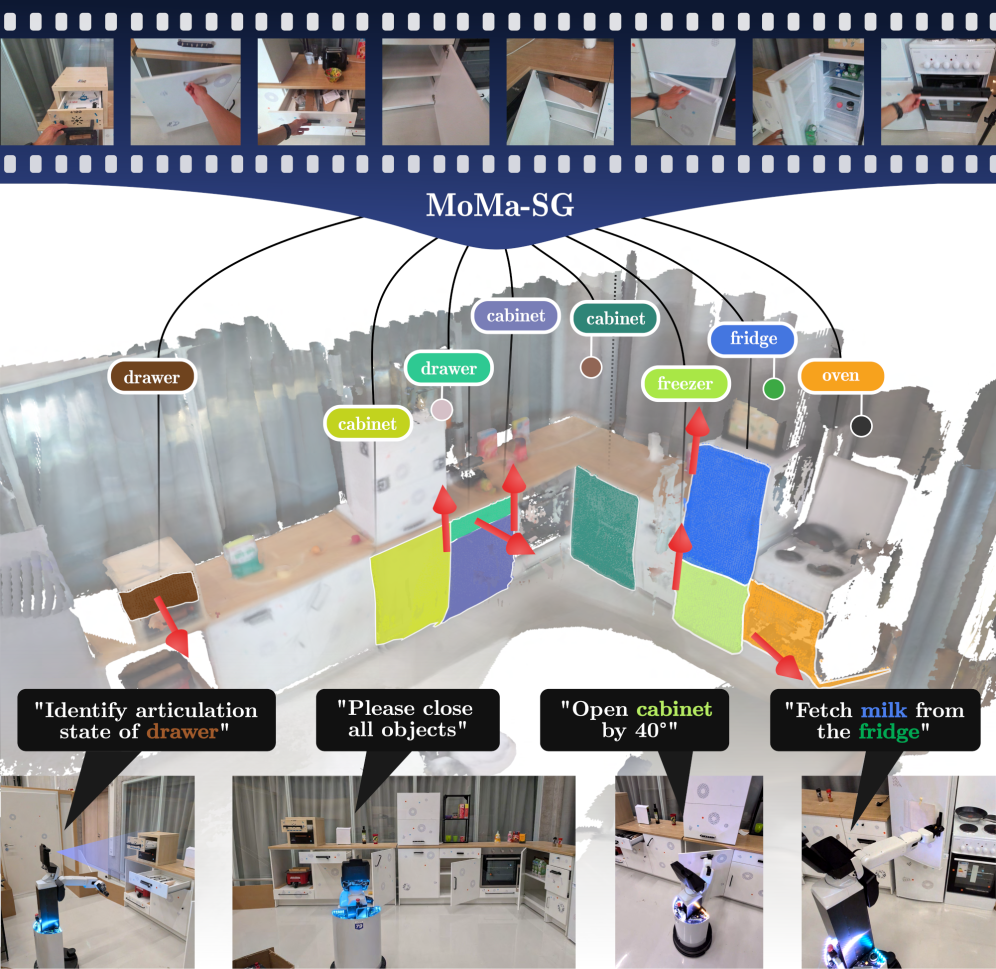
MoMa-SG:为开放世界移动操作构建可交互物体的语义-运动3D场景图
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 语义场景理解 运动估计 铰接物体操作 机器人操作 3D场景图
📋 核心要点
- 现有机器人无法预测物体如何移动,这限制了其在真实环境中进行长时程移动操作的能力。
- MoMa-SG通过构建语义-运动3D场景图,将语义、几何和运动学信息相结合,从而实现对铰接物体的理解和操作。
- 该方法在Arti4D-Semantic数据集上进行了评估,并在真实机器人平台上验证了其在家庭环境中操作铰接物体的能力。
📝 摘要(中文)
本文提出MoMa-SG,一个用于构建包含大量可交互物体的铰接场景的语义-运动3D场景图的新框架。给定包含多个物体铰接的RGB-D序列,该方法首先对物体交互进行时序分割,并使用抗遮挡的点跟踪来推断物体运动。然后,将点轨迹提升到3D空间,并使用一种新颖的统一twist估计公式来估计铰接模型,该公式在单个优化过程中稳健地估计旋转和棱柱关节参数。接下来,将物体与估计的铰接相关联,并通过推理已识别的打开状态下的父子关系来检测包含的物体。此外,还引入了Arti4D-Semantic数据集,该数据集独特地结合了分层物体语义(包括父子关系标签)和物体轴注释,涵盖62个真实RGB-D序列,包含600个物体交互和三种不同的观察范式。在两个数据集上广泛评估了MoMa-SG的性能,并消融了该方法中的关键设计选择。此外,在四足机器人和移动操作机器人上的真实实验表明,语义-运动场景图能够对日常家庭环境中铰接物体进行稳健的操作。代码和数据可在https://momasg.cs.uni-freiburg.de获取。
🔬 方法详解
问题定义:现有机器人操作方法缺乏对物体运动的预测能力,无法有效处理真实世界中大量存在的铰接物体。这限制了机器人在复杂环境中的长时程操作能力,例如打开抽屉、操作铰链等。现有方法难以将语义信息、几何信息和运动学信息有效结合,从而无法充分理解和利用场景中的可交互物体。
核心思路:MoMa-SG的核心思路是构建一种语义-运动3D场景图,将场景中的物体表示为节点,物体之间的关系(例如父子关系、铰接关系)表示为边。通过对RGB-D序列进行分析,提取物体的语义信息、几何信息和运动信息,并将其整合到场景图中。这种场景图能够帮助机器人理解场景中的物体及其运动方式,从而实现更智能的操作。
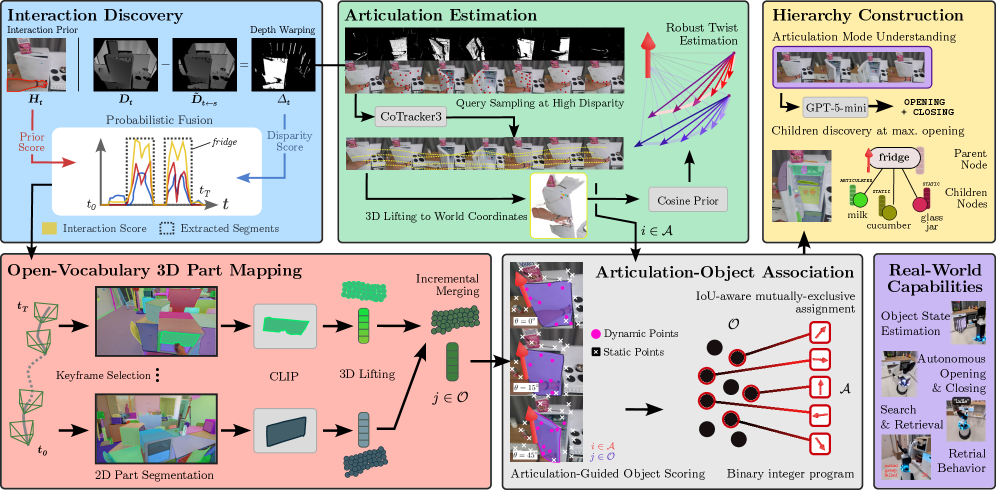
技术框架:MoMa-SG的整体框架包括以下几个主要阶段:1) 物体交互分割:对RGB-D序列进行时序分割,识别物体交互事件。2) 点云跟踪:使用抗遮挡的点云跟踪方法,估计物体在交互过程中的运动轨迹。3) 铰接模型估计:利用统一的twist估计公式,从点云轨迹中估计铰接模型的参数,包括旋转关节和棱柱关节。4) 物体关联与包含关系检测:将物体与估计的铰接相关联,并通过推理父子关系来检测包含的物体。5) 场景图构建:将上述信息整合到语义-运动3D场景图中。
关键创新:MoMa-SG的关键创新在于:1) 提出了一种统一的twist估计公式,能够稳健地估计旋转关节和棱柱关节的参数。2) 提出了一种基于父子关系推理的物体包含关系检测方法。3) 构建了Arti4D-Semantic数据集,该数据集包含了丰富的铰接物体交互信息和语义标注。
关键设计:在铰接模型估计中,使用了鲁棒的优化方法来最小化点云轨迹与铰接模型之间的误差。在物体包含关系检测中,利用了物体在不同打开状态下的几何信息和语义信息,例如抽屉完全打开时的状态。Arti4D-Semantic数据集包含了62个真实RGB-D序列,涵盖了多种铰接物体和交互方式,为算法的训练和评估提供了丰富的数据。
🖼️ 关键图片

📊 实验亮点
论文在Arti4D-Semantic数据集上进行了广泛的评估,结果表明MoMa-SG能够有效地构建语义-运动3D场景图。真实机器人实验表明,MoMa-SG能够帮助机器人在家庭环境中稳健地操作铰接物体。消融实验验证了关键设计选择的有效性,例如统一twist估计公式和基于父子关系推理的物体包含关系检测方法。
🎯 应用场景
该研究成果可应用于家庭服务机器人、工业自动化、辅助机器人等领域。例如,家庭服务机器人可以利用该技术理解并操作厨房中的各种铰接物体,如冰箱门、抽屉等,从而更好地完成家务任务。在工业自动化领域,机器人可以利用该技术操作生产线上的各种设备,提高生产效率。此外,该技术还可以应用于辅助机器人,帮助残疾人完成日常生活中的各种任务。
📄 摘要(原文)
Semantics has enabled 3D scene understanding and affordance-driven object interaction. However, robots operating in real-world environments face a critical limitation: they cannot anticipate how objects move. Long-horizon mobile manipulation requires closing the gap between semantics, geometry, and kinematics. In this work, we present MoMa-SG, a novel framework for building semantic-kinematic 3D scene graphs of articulated scenes containing a myriad of interactable objects. Given RGB-D sequences containing multiple object articulations, we temporally segment object interactions and infer object motion using occlusion-robust point tracking. We then lift point trajectories into 3D and estimate articulation models using a novel unified twist estimation formulation that robustly estimates revolute and prismatic joint parameters in a single optimization pass. Next, we associate objects with estimated articulations and detect contained objects by reasoning over parent-child relations at identified opening states. We also introduce the novel Arti4D-Semantic dataset, which uniquely combines hierarchical object semantics including parent-child relation labels with object axis annotations across 62 in-the-wild RGB-D sequences containing 600 object interactions and three distinct observation paradigms. We extensively evaluate the performance of MoMa-SG on two datasets and ablate key design choices of our approach. In addition, real-world experiments on both a quadruped and a mobile manipulator demonstrate that our semantic-kinematic scene graphs enable robust manipulation of articulated objects in everyday home environments. We provide code and data at: https://momasg.cs.uni-freiburg.de.