Dual-Quadruped Collaborative Transportation in Narrow Environments via Safe Reinforcement Learning
作者: Zhezhi Lei, Zhihai Bi, Wenxin Wang, Jun Ma
分类: cs.RO
发布日期: 2026-02-18
💡 一句话要点
提出基于安全强化学习的双足机器人狭窄环境协同运输方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 协同运输 双足机器人 强化学习 安全强化学习 约束马尔可夫博弈
📋 核心要点
- 现有方法难以在狭窄环境中保证多机器人协同运输的安全性和高性能。
- 提出基于安全强化学习的框架,通过约束马尔可夫博弈和代价优势分解保证安全性。
- 实验结果表明,该方法在双足机器人协同运输任务中表现出更高的性能和成功率。
📝 摘要(中文)
本文提出了一种基于安全强化学习的双足机器人协同运输方法,旨在解决狭窄环境中机器人间安全高效协作的难题。该方法将任务建模为完全合作的约束马尔可夫博弈,并将避障问题转化为约束条件。通过引入代价优势分解方法,确保团队约束的总和保持在上限以下,从而保证强化学习框架内的任务安全性。此外,提出了一种约束分配方法,将共享约束分配给各个机器人,以最大化整体任务奖励,鼓励机器人自主进行任务分配,从而提高协作任务的性能。仿真和实时实验结果表明,与现有方法相比,该方法在双足机器人协同运输中取得了更好的性能和更高的成功率。
🔬 方法详解
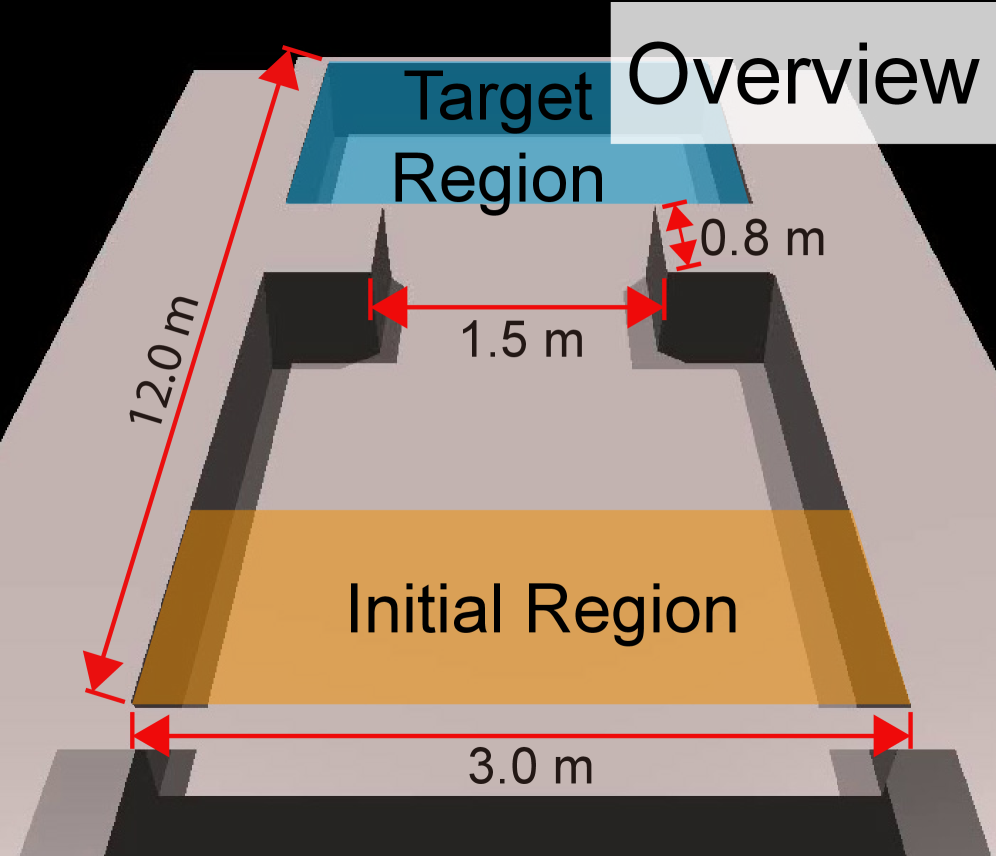
问题定义:论文旨在解决双足机器人在狭窄环境中协同运输有效载荷的问题。现有方法在狭窄环境中难以保证机器人之间安全高效的协作,尤其是在避障和任务分配方面存在挑战。如何在保证安全的前提下,提高协同运输的效率和成功率是亟待解决的问题。
核心思路:论文的核心思路是将协同运输任务建模为完全合作的约束马尔可夫博弈,并通过安全强化学习来训练机器人的控制策略。通过将避障问题转化为约束条件,并引入代价优势分解方法,确保团队的整体安全性。同时,通过约束分配方法,鼓励机器人自主进行任务分配,从而提高协作效率。
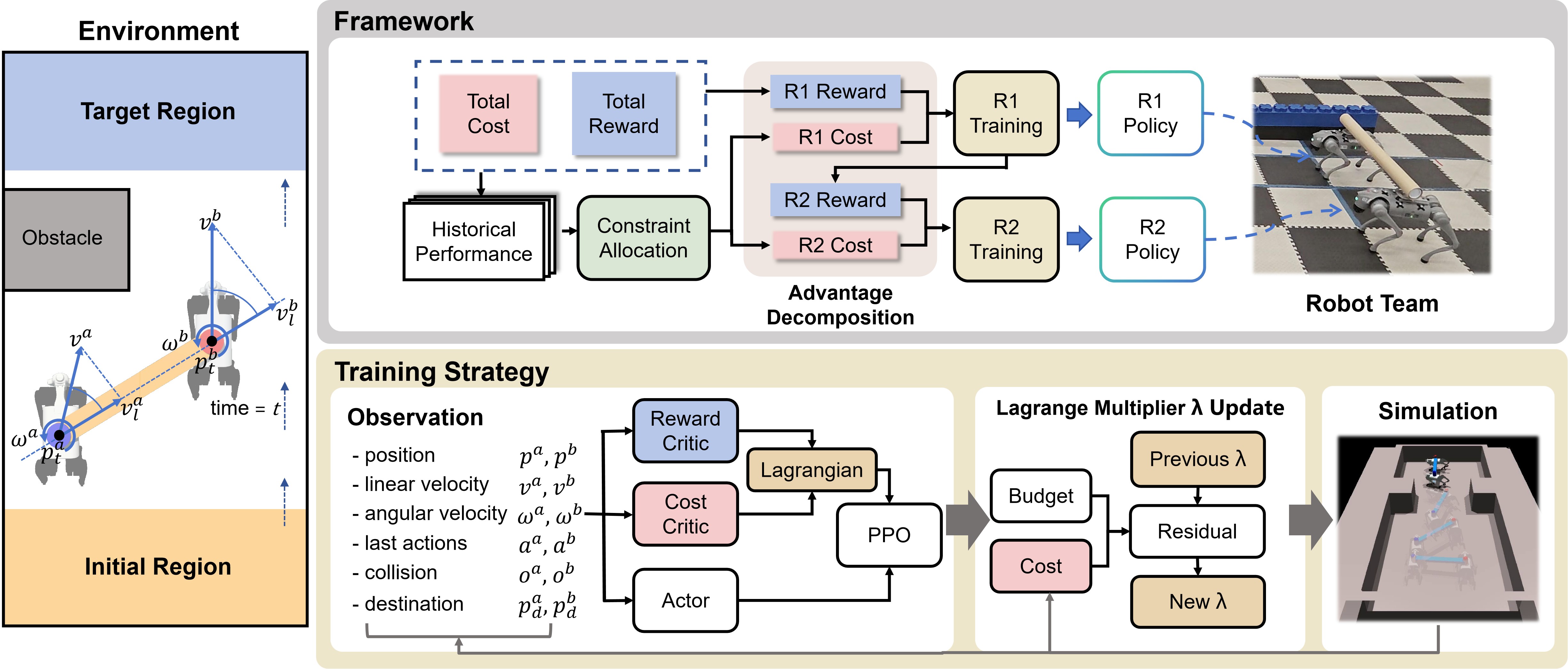
技术框架:该方法的技术框架主要包括以下几个模块:1) 任务建模:将协同运输任务建模为约束马尔可夫博弈,定义状态空间、动作空间、奖励函数和约束条件。2) 安全强化学习:使用安全强化学习算法训练机器人的控制策略,目标是在满足约束条件的前提下最大化累积奖励。3) 代价优势分解:引入代价优势分解方法,将团队约束分解为个体约束,并确保团队约束的总和保持在上限以下。4) 约束分配:提出一种约束分配方法,将共享约束分配给各个机器人,以最大化整体任务奖励。
关键创新:论文的关键创新在于以下几个方面:1) 将协同运输任务建模为约束马尔可夫博弈,为安全强化学习提供了理论基础。2) 提出代价优势分解方法,有效地保证了团队的整体安全性。3) 提出约束分配方法,鼓励机器人自主进行任务分配,提高了协作效率。与现有方法相比,该方法在安全性和协作效率方面都有显著提升。
关键设计:在具体实现中,论文可能涉及以下关键设计:1) 状态空间的设计:需要包含机器人的位置、姿态、速度等信息,以及有效载荷的位置和姿态信息。2) 动作空间的设计:需要包含机器人的关节角度或力矩等控制指令。3) 奖励函数的设计:需要包含任务完成的奖励、避障的惩罚等。4) 约束条件的设计:需要包含机器人之间的距离约束、机器人与环境之间的距离约束等。5) 强化学习算法的选择:可以选择TRPO、PPO等安全强化学习算法。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在双足机器人协同运输任务中取得了显著的性能提升。与现有方法相比,该方法能够以更高的成功率完成任务,并且在狭窄环境中表现出更好的避障能力。具体的性能数据(例如成功率、完成时间等)在摘要中未明确给出,但强调了优于现有方法。
🎯 应用场景
该研究成果可应用于多种场景,例如:在狭窄的仓库或工厂环境中,多个机器人协同搬运货物;在灾难救援现场,多个机器人协同清理障碍物或运送物资;在太空探索任务中,多个机器人协同完成复杂的任务。该研究具有重要的实际价值,可以提高多机器人协同工作的效率和安全性,并为未来的机器人应用提供新的思路。
📄 摘要(原文)
Collaborative transportation, where multiple robots collaboratively transport a payload, has garnered significant attention in recent years. While ensuring safe and high-performance inter-robot collaboration is critical for effective task execution, it is difficult to pursue in narrow environments where the feasible region is extremely limited. To address this challenge, we propose a novel approach for dual-quadruped collaborative transportation via safe reinforcement learning (RL). Specifically, we model the task as a fully cooperative constrained Markov game, where collision avoidance is formulated as constraints. We introduce a cost-advantage decomposition method that enforces the sum of team constraints to remain below an upper bound, thereby guaranteeing task safety within an RL framework. Furthermore, we propose a constraint allocation method that assigns shared constraints to individual robots to maximize the overall task reward, encouraging autonomous task-assignment among robots, thereby improving collaborative task performance. Simulation and real-time experimental results demonstrate that the proposed approach achieves superior performance and a higher success rate in dual-quadruped collaborative transportation compared to existing methods.