SIT-LMPC: Safe Information-Theoretic Learning Model Predictive Control for Iterative Tasks
作者: Zirui Zang, Ahmad Amine, Nick-Marios T. Kokolakis, Truong X. Nghiem, Ugo Rosolia, Rahul Mangharam
分类: cs.RO, cs.AI, eess.SY
发布日期: 2026-02-18
备注: 8 pages, 5 figures. Published in IEEE RA-L, vol. 11, no. 1, Jan. 2026. Presented at ICRA 2026
期刊: IEEE Robotics and Automation Letters, vol. 11, no. 1, pp. 986-993, 2026
💡 一句话要点
提出SIT-LMPC算法,解决复杂不确定环境下迭代任务的鲁棒安全控制问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 模型预测控制 信息论学习 迭代学习 安全控制 归一化流
📋 核心要点
- 现有方法难以在复杂不确定环境中平衡迭代任务的鲁棒性、安全性和高性能。
- SIT-LMPC利用信息论MPC和归一化流学习价值函数,实现安全约束下的迭代优化控制。
- 仿真和硬件实验验证了SIT-LMPC在提高性能和满足约束方面的有效性。
📝 摘要(中文)
本文提出了一种用于迭代任务的安全信息论学习模型预测控制(SIT-LMPC)算法。该算法基于信息论模型预测控制框架,用于解决离散时间非线性随机系统的约束无限时域最优控制问题。开发了一种自适应惩罚方法,以确保安全性的同时兼顾最优性。利用先前迭代的轨迹,使用归一化流学习价值函数,与高斯先验相比,能够实现更丰富的不确定性建模。SIT-LMPC专为图形处理单元上的高度并行执行而设计,从而可以实现高效的实时优化。基准模拟和硬件实验表明,SIT-LMPC可以迭代地提高系统性能,同时稳健地满足系统约束。
🔬 方法详解
问题定义:论文旨在解决复杂、不确定环境中机器人执行迭代任务时,如何在保证安全约束的前提下,实现高性能的控制。现有方法通常难以同时兼顾鲁棒性、安全性和优化性能,尤其是在处理非线性随机系统时,对不确定性的建模不够充分。
核心思路:论文的核心思路是利用信息论模型预测控制(IT-MPC)框架,结合学习到的价值函数,对未来状态的不确定性进行建模,并通过自适应惩罚方法来保证安全性。通过迭代学习,不断优化控制策略,提高系统性能。
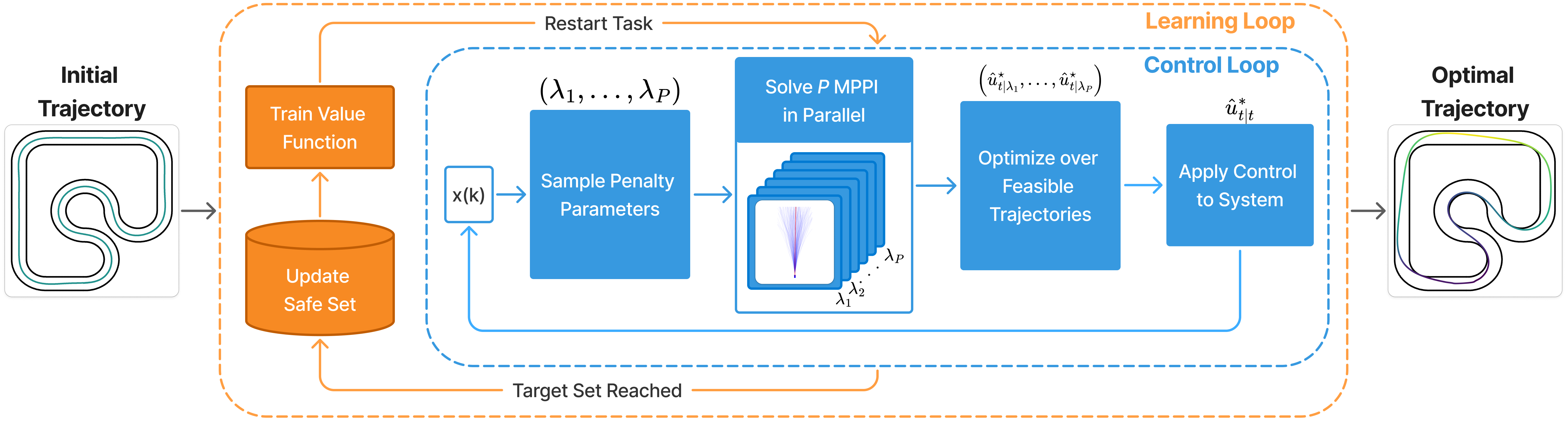
技术框架:SIT-LMPC算法的整体框架包括以下几个主要模块:1) 基于IT-MPC的预测控制模块,用于生成控制序列;2) 基于归一化流的价值函数学习模块,利用历史轨迹数据学习价值函数,从而对未来状态的不确定性进行建模;3) 自适应惩罚模块,根据系统状态与安全约束的距离,动态调整惩罚项,以保证安全性;4) 并行优化模块,利用GPU进行并行计算,提高优化速度。
关键创新:论文的关键创新在于:1) 将信息论引入MPC框架,通过最小化互信息来控制状态的不确定性;2) 使用归一化流学习价值函数,相比于传统的高斯先验,能够更灵活地建模复杂的不确定性分布;3) 提出了一种自适应惩罚方法,能够在保证安全性的同时,尽可能地优化性能。
关键设计:在价值函数学习模块中,使用了归一化流(Normalizing Flows)来建模价值函数。归一化流是一种强大的生成模型,可以通过一系列可逆变换将简单分布(如高斯分布)转换为复杂分布。在自适应惩罚模块中,惩罚系数根据当前状态与安全约束的距离动态调整。此外,算法充分利用GPU的并行计算能力,加速优化过程。
🖼️ 关键图片
📊 实验亮点
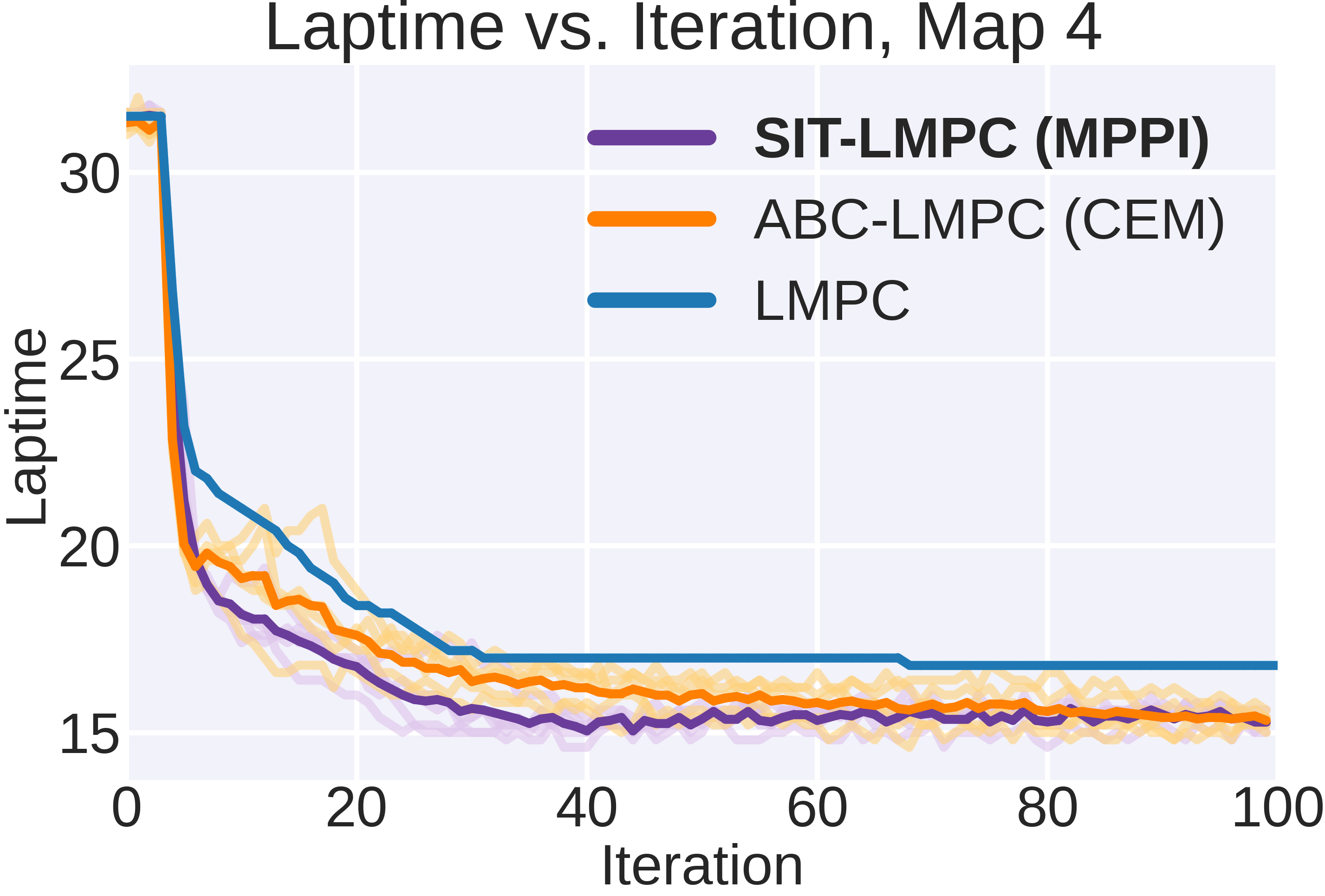
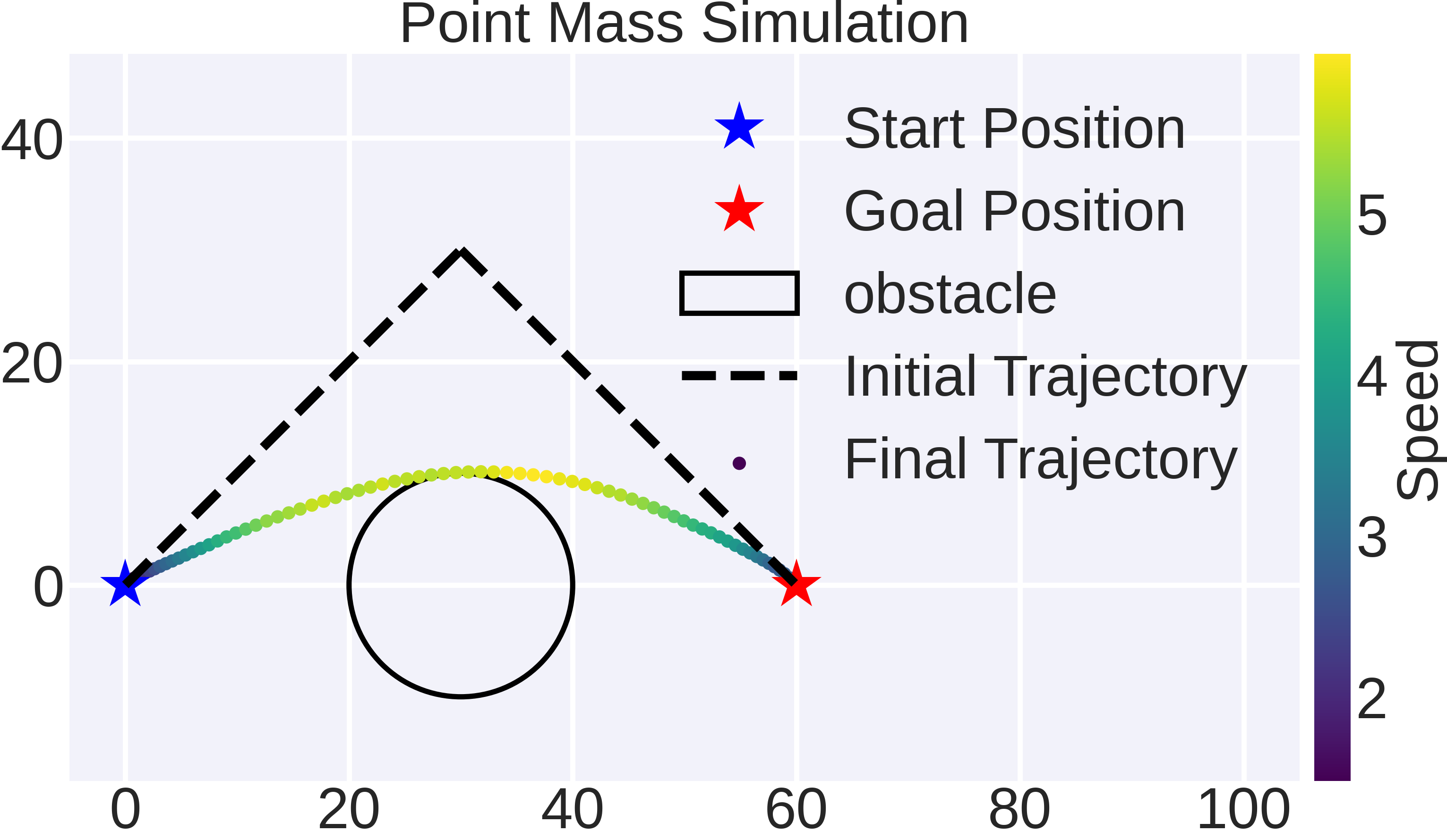
论文通过基准仿真和硬件实验验证了SIT-LMPC算法的有效性。实验结果表明,SIT-LMPC能够迭代地提高系统性能,同时稳健地满足系统约束。与传统方法相比,SIT-LMPC在处理复杂不确定环境下的迭代任务时,能够取得更好的性能和更高的安全性。
🎯 应用场景
SIT-LMPC算法可应用于各种需要在复杂不确定环境中执行迭代任务的机器人系统,例如:自动驾驶、无人机编队、工业机器人等。该算法能够提高系统的鲁棒性、安全性和性能,使其能够在实际应用中更好地适应环境变化和不确定性,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Robots executing iterative tasks in complex, uncertain environments require control strategies that balance robustness, safety, and high performance. This paper introduces a safe information-theoretic learning model predictive control (SIT-LMPC) algorithm for iterative tasks. Specifically, we design an iterative control framework based on an information-theoretic model predictive control algorithm to address a constrained infinite-horizon optimal control problem for discrete-time nonlinear stochastic systems. An adaptive penalty method is developed to ensure safety while balancing optimality. Trajectories from previous iterations are utilized to learn a value function using normalizing flows, which enables richer uncertainty modeling compared to Gaussian priors. SIT-LMPC is designed for highly parallel execution on graphics processing units, allowing efficient real-time optimization. Benchmark simulations and hardware experiments demonstrate that SIT-LMPC iteratively improves system performance while robustly satisfying system constraints.