Perceptive Humanoid Parkour: Chaining Dynamic Human Skills via Motion Matching
作者: Zhen Wu, Xiaoyu Huang, Lujie Yang, Yuanhang Zhang, Koushil Sreenath, Xi Chen, Pieter Abbeel, Rocky Duan, Angjoo Kanazawa, Carmelo Sferrazza, Guanya Shi, C. Karen Liu
分类: cs.RO, cs.AI, cs.LG, eess.SY
发布日期: 2026-02-17
💡 一句话要点
提出PHP框架,通过运动匹配和深度强化学习,实现人形机器人自主完成复杂环境下的跑酷动作。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 人形机器人 跑酷 运动匹配 强化学习 深度感知 技能组合 自主决策
📋 核心要点
- 现有的人形机器人运动控制方法难以实现像人类一样敏捷和适应性强的动态运动,尤其是在复杂的跑酷环境中。
- PHP框架通过运动匹配组合人类技能,并利用深度强化学习训练感知策略,使机器人能够根据视觉输入自主决策并执行跑酷动作。
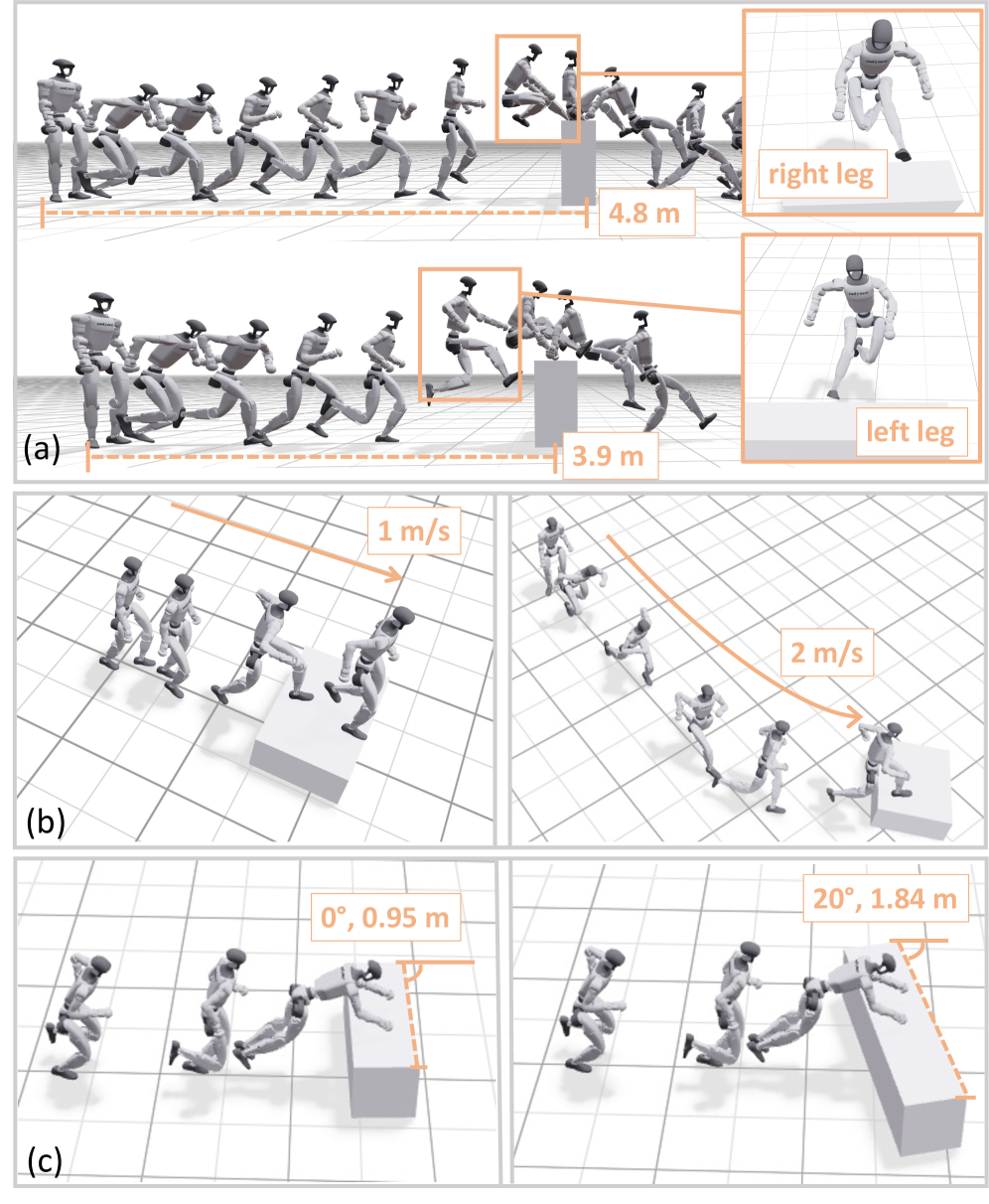
- 实验表明,该框架使Unitree G1机器人能够攀爬高达1.25米的障碍物,并适应实时障碍物扰动,完成长程多障碍物穿越。
📝 摘要(中文)
本文提出了一种名为感知人形机器人跑酷(PHP)的模块化框架,使人形机器人能够在具有挑战性的障碍赛道上自主执行基于视觉的长程跑酷动作。该方法首先利用运动匹配(将其形式化为特征空间中的最近邻搜索)将重新定向的原子人类技能组合成长程运动轨迹。这种框架能够灵活地组合和流畅地过渡复杂的技能链,同时保留动态人类运动的优雅性和流畅性。接下来,我们为这些组合的运动训练运动跟踪强化学习(RL)专家策略,并使用DAgger和RL的组合将它们提炼成一个基于深度的多技能学生策略。至关重要的是,感知和技能组合的结合实现了自主的、上下文感知的决策:仅使用板载深度感知和一个离散的2D速度命令,机器人就可以选择和执行跨越、攀爬、跳跃或滚下不同几何形状和高度的障碍物。我们通过在Unitree G1人形机器人上进行的大量真实世界实验验证了我们的框架,展示了高度动态的跑酷技能,例如攀爬高达1.25米(96%机器人高度)的障碍物,以及具有闭环适应实时障碍物扰动的长程多障碍物穿越。
🔬 方法详解
问题定义:论文旨在解决人形机器人在复杂环境中自主进行跑酷运动的问题。现有的方法通常难以兼顾低级别的鲁棒性、人类般的运动表达、长程技能组合以及基于感知的决策。
核心思路:核心思路是将人类的跑酷技能分解为原子技能,通过运动匹配将这些技能组合成长程轨迹,然后利用强化学习训练机器人执行这些轨迹。通过结合感知信息,机器人可以根据环境自主选择合适的技能。
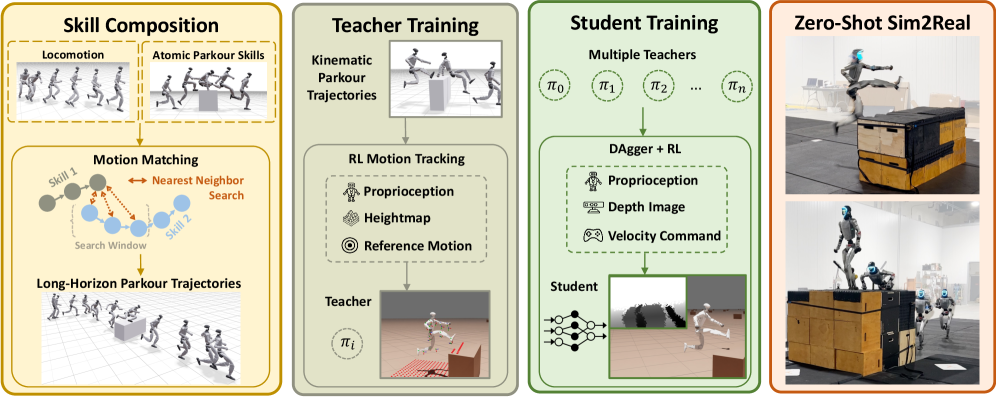
技术框架:PHP框架包含以下几个主要模块:1) 运动匹配模块,用于将人类跑酷动作库中的原子技能组合成长程运动轨迹;2) 运动跟踪强化学习模块,用于训练机器人模仿这些轨迹;3) 深度感知模块,用于获取环境信息;4) 决策模块,用于根据感知信息选择合适的技能。
关键创新:该方法最重要的创新点在于将运动匹配和深度强化学习相结合,实现了人形机器人的自主跑酷。运动匹配保证了运动的流畅性和人类相似性,而深度强化学习则赋予了机器人适应环境变化的能力。此外,基于深度感知的决策模块使得机器人能够根据环境自主选择合适的技能。
关键设计:运动匹配模块使用特征空间中的最近邻搜索来选择合适的原子技能。强化学习模块使用DAgger和RL的组合来训练学生策略,使其能够模仿专家策略。深度感知模块使用板载深度传感器获取环境信息。决策模块使用一个离散的2D速度命令作为输入,选择合适的技能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该框架使Unitree G1机器人能够攀爬高达1.25米(96%机器人高度)的障碍物,并成功穿越多个障碍物,同时能够适应实时障碍物扰动。这些实验验证了该框架在复杂环境下实现人形机器人自主跑酷的有效性。
🎯 应用场景
该研究成果可应用于搜救、勘探等复杂环境下的机器人作业。通过赋予机器人更强的运动能力和环境适应性,可以使其在人类难以到达或危险的区域执行任务,例如灾后救援、矿产勘探、高空作业等。此外,该技术还可以用于开发更具互动性和娱乐性的机器人应用,例如机器人跑酷游戏、机器人舞蹈等。
📄 摘要(原文)
While recent advances in humanoid locomotion have achieved stable walking on varied terrains, capturing the agility and adaptivity of highly dynamic human motions remains an open challenge. In particular, agile parkour in complex environments demands not only low-level robustness, but also human-like motion expressiveness, long-horizon skill composition, and perception-driven decision-making. In this paper, we present Perceptive Humanoid Parkour (PHP), a modular framework that enables humanoid robots to autonomously perform long-horizon, vision-based parkour across challenging obstacle courses. Our approach first leverages motion matching, formulated as nearest-neighbor search in a feature space, to compose retargeted atomic human skills into long-horizon kinematic trajectories. This framework enables the flexible composition and smooth transition of complex skill chains while preserving the elegance and fluidity of dynamic human motions. Next, we train motion-tracking reinforcement learning (RL) expert policies for these composed motions, and distill them into a single depth-based, multi-skill student policy, using a combination of DAgger and RL. Crucially, the combination of perception and skill composition enables autonomous, context-aware decision-making: using only onboard depth sensing and a discrete 2D velocity command, the robot selects and executes whether to step over, climb onto, vault or roll off obstacles of varying geometries and heights. We validate our framework with extensive real-world experiments on a Unitree G1 humanoid robot, demonstrating highly dynamic parkour skills such as climbing tall obstacles up to 1.25m (96% robot height), as well as long-horizon multi-obstacle traversal with closed-loop adaptation to real-time obstacle perturbations.